spark foreachPartition foreach
2024-08-29 08:27:15
1.foreach
val list = new ArrayBuffer()
myRdd.foreach(record => {
list += record
})
2.foreachPartition
val list = new ArrayBuffer
rdd.foreachPartition(it => {
it.foreach(r => {
list += r
})
})
说明:
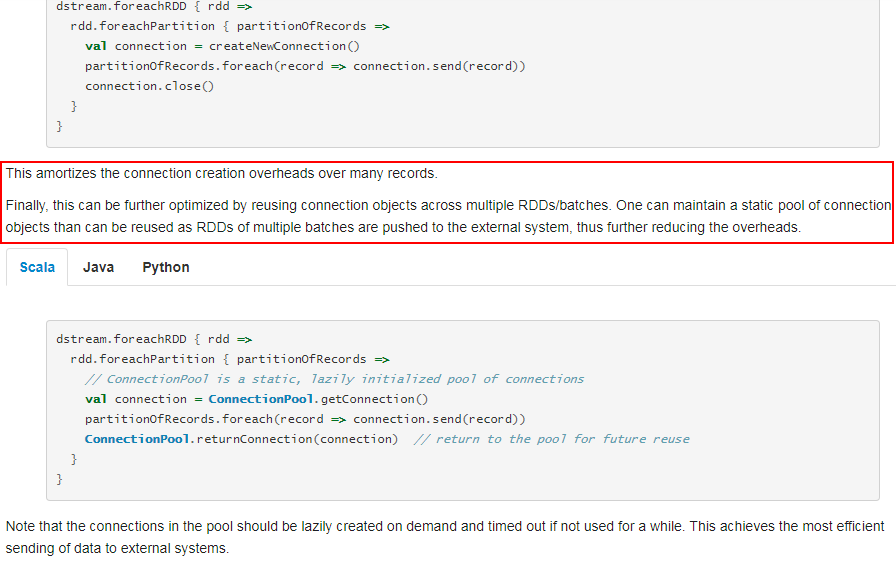
foreachPartition属于算子操作,可以提高模型效率。比如在使用foreach时,将RDD中所有数据写Mongo中,就会一条数据一条数据地写,每次函数调用可能就会创建一个数据库连接,此时就势必会频繁地创建和销毁数据库连接,性能是非常低下;但是如果用foreachPartitions算子一次性处理一个partition的数据,那么对于每个partition,只要创建一个数据库连接即可,然后执行批量插入操作,此时性能是比较高的。
参考官网的说明:
https://spark.apache.org/docs/latest/streaming-programming-guide.html
最新文章
- EasyAR 开发教程系列1--小试牛刀
- 症状解决,原因不详的用非默认管理权限账户登录COM注册成功但找不到类型问题
- JAVA线程同步辅助类CyclicBarrier循环屏障
- QInputDialog 使用方法
- Mysqldump参数大全(转)
- MailOtto 实现完美预加载以及源码解读
- iOS工程结构
- PHP发红包程序
- Vim 实用技术,第 2 部分: 常用插件(转)
- app 转caf 音频 代码
- awk学习点滴
- Wannafly交流赛1(施工中)
- Get-CrmSetting返回Unable to connect to the remote server的解决办法
- [ZJOI2019]麻将(动态规划,自动机)
- Notepad++编写运行python程序
- linux服务器进程信息查看命令
- Codeforces 749C. Voting 模拟题
- 手机端点击复制链接到剪切板(以及PC端)
- “全栈2019”Java第九十四章:局部内部类详解
- 海康解码器对接总结(java 版)