吴裕雄--天生自然 python数据分析:葡萄酒分析
2024-10-08 22:34:28
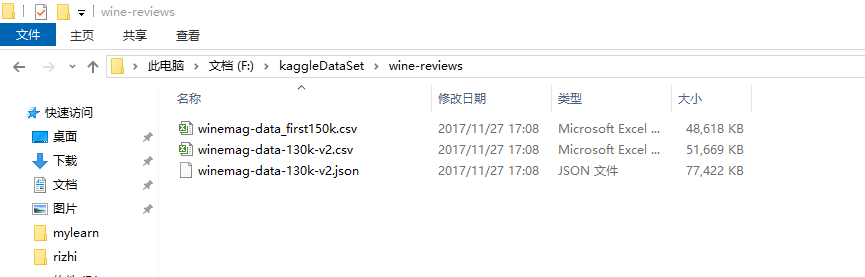
# import pandas
import pandas as pd # creating a DataFrame
pd.DataFrame({'Yes': [50, 31], 'No': [101, 2]})
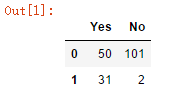
# another example of creating a dataframe
pd.DataFrame({'Bob': ['I liked it.', 'It was awful.'], 'Sue': ['Pretty good.', 'Bland']})
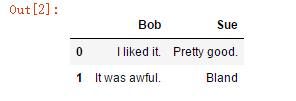
pd.DataFrame({'Bob': ['I liked it.', 'It was awful.'],
'Sue': ['Pretty good.', 'Bland.']},
index = ['Product A', 'Product B'])

# creating a pandas series
pd.Series([1, 2, 3, 4, 5])

# we can think of a Series as a column of a DataFrame.
# we can assign index values to Series in same way as pandas DataFrame
pd.Series([10, 20, 30], index=['2015 sales', '2016 sales', '2017 sales'], name='Product A')

# reading a csv file and storing it in a variable
wine_reviews = pd.read_csv("F:\\kaggleDataSet\\wine-reviews\\winemag-data-130k-v2.csv")
# we can use the 'shape' attribute to check size of dataset
wine_reviews.shape
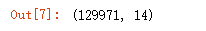
# To show first five rows of data, use 'head()' method
wine_reviews.head()
wine_reviews = pd.read_csv("F:\\kaggleDataSet\\wine-reviews\\winemag-data-130k-v2.csv", index_col=0)
wine_reviews.head()
wine_reviews.head().to_csv("F:\\wine_reviews.csv")
import pandas as pd
reviews = pd.read_csv("F:\\kaggleDataSet\\wine-reviews\\winemag-data-130k-v2.csv", index_col=0)
pd.set_option("display.max_rows", 5)
reviews
# access 'country' property (or column) of 'reviews'
reviews.country

# Another way to do above operation
# when a column name contains space, we have to use this method
reviews['country']
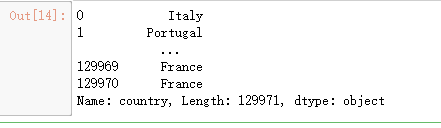
# To access first row of country column
reviews['country'][0]

# returns first row
reviews.iloc[0]

# returns first column (country) (all rows due to ':')
reviews.iloc[:, 0]
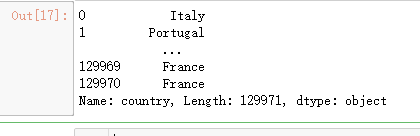
# retruns first 3 rows of first column
reviews.iloc[:3, 0]

# we can pass a list of indices of rows/columns to select
reviews.iloc[[0, 1, 2, 3], 0]

# We can also pass negative numbers as we do in Python
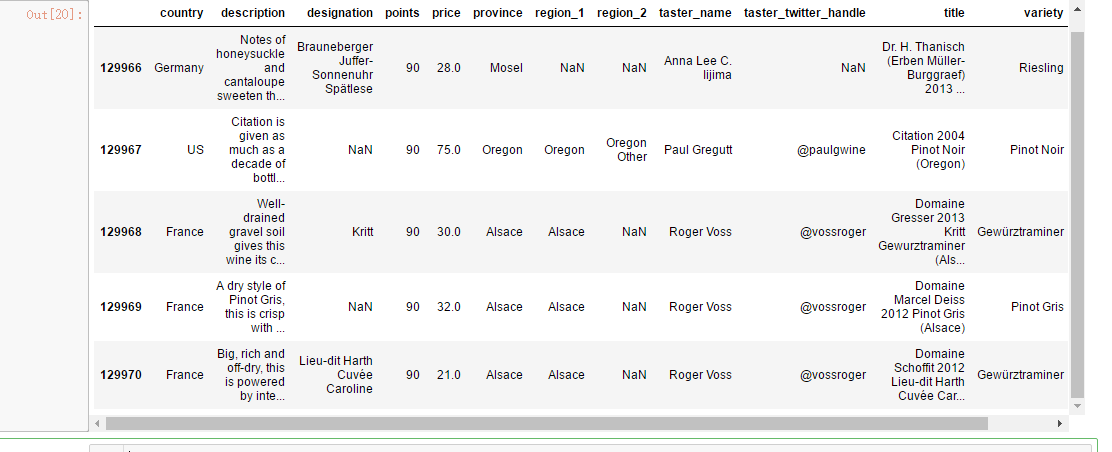
reviews.iloc[-5:]
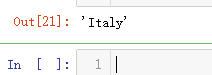
# To select first entry in country column
reviews.loc[0, 'country']
# select columns by name using 'loc'
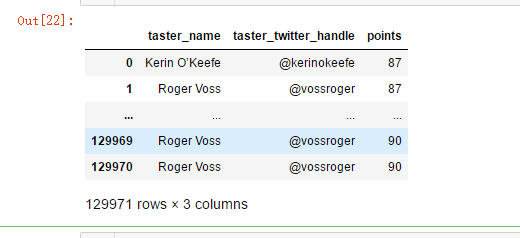
reviews.loc[:, ['taster_name', 'taster_twitter_handle', 'points']]
# 'set_index' to the 'title' field
reviews.set_index('title')

# 1. Find out whether wine is produced in Italy
reviews.country == 'Italy'

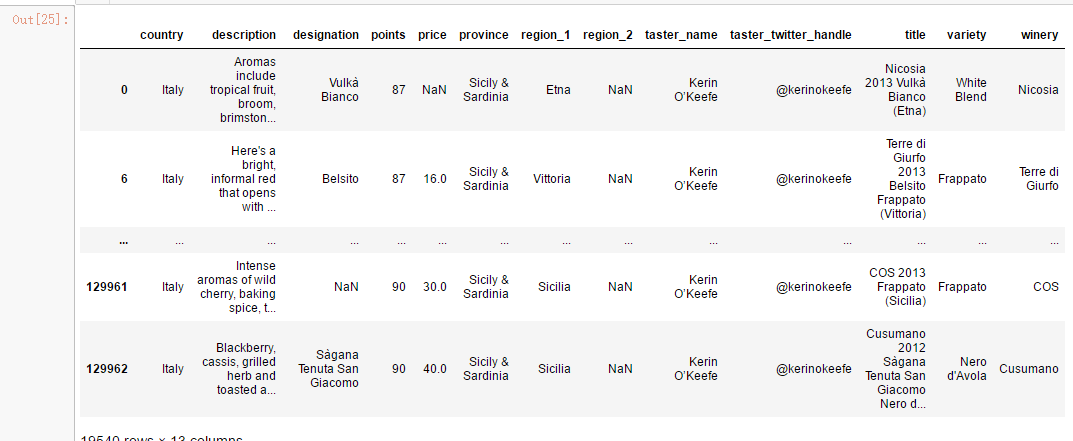
# 2. Now select all wines produced in Italy
reviews.loc[reviews.country == 'Italy'] #reviews[reviews.country == 'Italy']
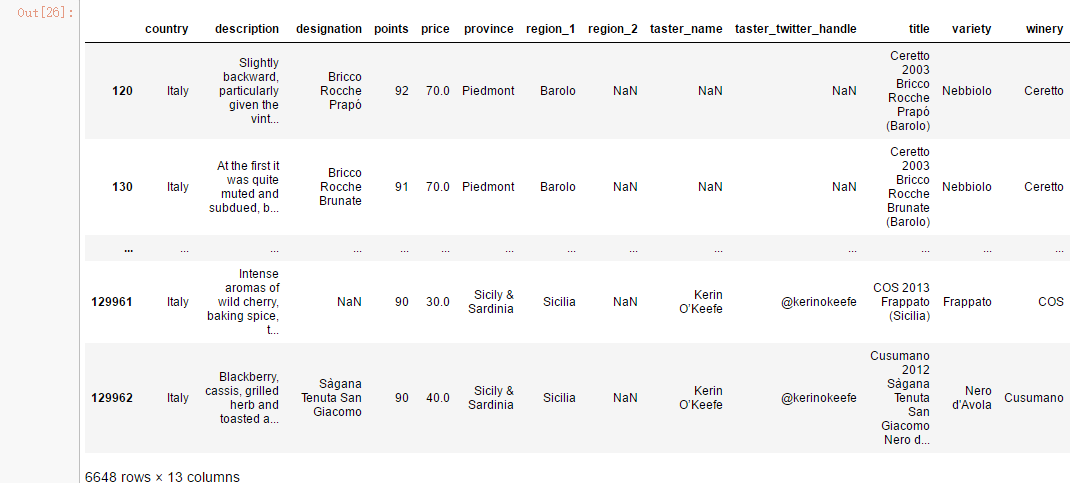
# Add one more condition for points to find better than average wines produced in Italy
reviews.loc[(reviews.country == 'Italy') & (reviews.points >= 90)] # use | for 'OR' condition
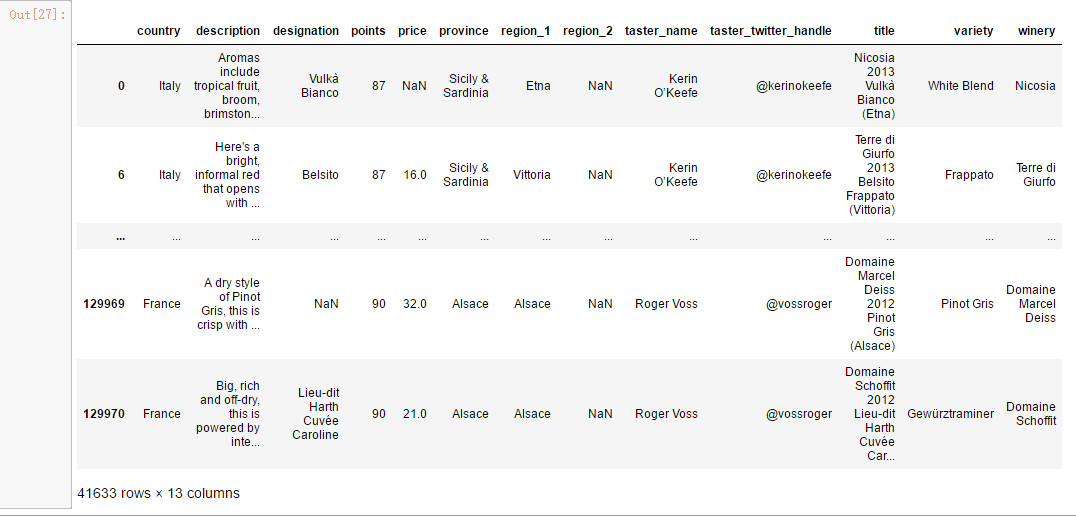
reviews.loc[reviews.country.isin(['Italy', 'France'])]
reviews.loc[reviews.price.notnull()]
reviews['critic'] = 'everyone'
reviews.critic

# using iterable for assigning
reviews['index_backwards'] = range(len(reviews), 0, -1)
reviews['index_backwards']

最新文章
- kibana 使用
- 文件上传和下载(可批量上传)——Spring(三)
- [ACM_模拟] ZOJ 3713 [In 7-bit 特殊输出规则 7bits 16进制]
- Linux和Windows互传文件命令(转)
- Linux脚本
- Installing vSphere SDK for Perl
- day57:00:26:34
- ASP.NET之自定义异步HTTP处理程序(图文教程)
- WinForms C#:html编辑器工程源码,含直接写WebBrowser的文件流、IPersistStreamInit接口的声明和一些相关的小方法
- Error:Android Source Generator: [sdk] Android SDK is not specified.
- 怀念Galois
- git忽略文件
- hdu 2825 aC自动机+状压dp
- cordova+vue打包webapp
- 使用hql动态创建对象问题
- 分布式架构的基石.简单的 RPC 框架实现(JAVA)
- FreeSWITCH部署与功能配置
- python第五十天--paramiko
- 【Java】-NO.13.Algorithm.1.Java Algorithm.1.001-【Java 常用算法手册 】-
- [转载]SQL Server中的事务与锁