Spark通过打jar包形式提交任务
2024-09-08 18:13:43
idea构建项目
- 创建一个maven项目,配置pom依赖,以及scala编译插件。 注意一定要保证,你的scala版本和spark版本和要提交的集群版本一致,要不很多莫名其妙的问题,scala如果你在window安装的版本就是和集群不一样,又懒得重新装,可以看 2 中,通过idea配置版本,并在编译插件里面指定好scala编译版本
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>org.example</groupId>
<artifactId>sparkextract</artifactId>
<version>1.0-SNAPSHOT</version>
<properties>
<maven.compiler.source>8</maven.compiler.source>
<maven.compiler.target>8</maven.compiler.target>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-hive_2.11</artifactId>
<version>2.4.8</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.11</artifactId>
<version>2.4.8</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.11</artifactId>
<version>2.4.8</version>
</dependency>
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>2.11.12</version>
</dependency>
</dependencies>
<build>
<sourceDirectory>src/main/scala</sourceDirectory>
<plugins>
<plugin>
<groupId>net.alchim31.maven</groupId>
<artifactId>scala-maven-plugin</artifactId>
<version>4.7.2</version>
<configuration>
<scalaVersion>2.11.12</scalaVersion>
</configuration>
</plugin>
</plugins>
</build>
</project>
配置scala的SDK, idea选项栏 File -> Project Structure -> Global Libraries
点击 + 号,选择一致的scala版本
编辑你的代码, 需要注意,SparkConf里,不要配置master的内容,否则在submit提交的时候,指定的master会失效。
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object WordCount{
def main(args: Array[String]):Unit = {
// spark配置新建
val sparkConf = new SparkConf().setAppName("Operator")
// spark上下文对象
val spark: SparkContext = SparkContext.getOrCreate(sparkConf)
// wordcount逻辑开始
val inPath: String = "hdfs:///user/zhangykun0508/exe.log"
val outPath: String = "hdfs:///user/zhangykun0508/wc.out"
val file: RDD[String] = spark.textFile(inPath)
val result: RDD[(String, Int)] = file.flatMap(a => a.split(" ")).map(a => (a, 1)).reduceByKey(_ + _)
result.saveAsTextFile(outPath)
}
}
- 打jar包,注意先要用 scala插件编译,然后再用maven打包
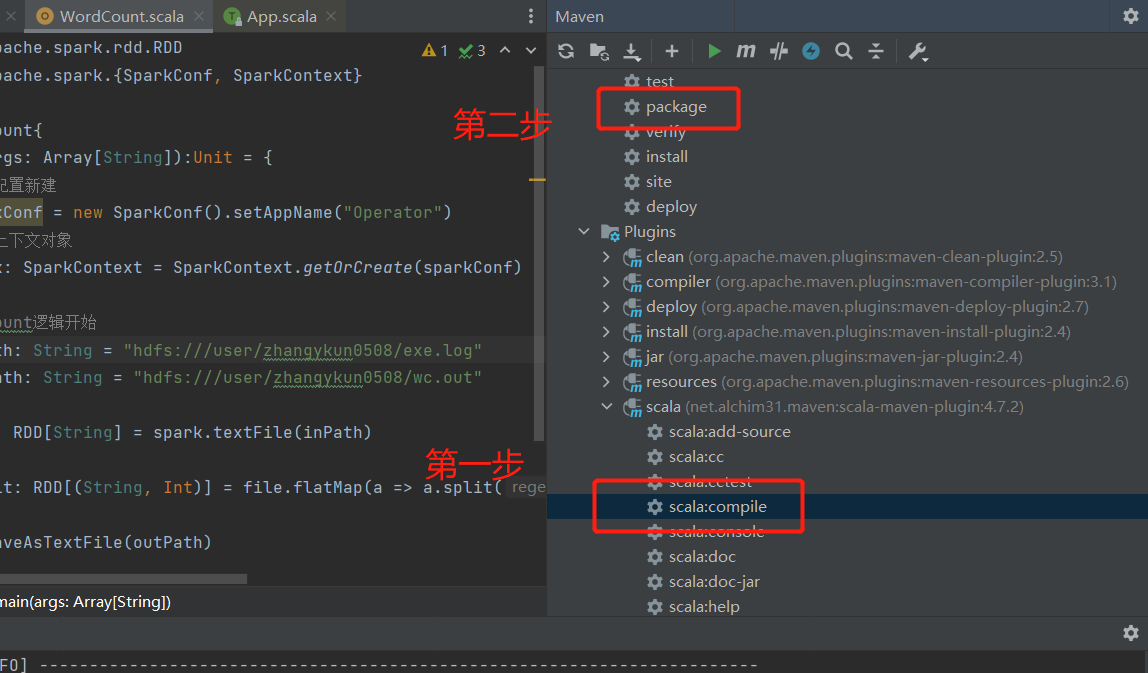
任务提交
我这边提交的方式为提交到yarn上。将上一步打包好的jar文件,传到hadoop的节点,然后按以下命令执行
spark-submit \
--class WordCount \
--conf inPath=hdfs:///user/zhangykun0508/exe.log outPath=hdfs:///user/zhangykun0508 \
--master yarn \
--deploy-mode cluster \
./sparkextract.jar \
10
-- 命令解析
spark-submit \ # 执行spark-submit应用
--class WordCount \ # 指定本次任务的Main方法所在的类, 如果你的程序比较规范,记得要输入包名,如: com.zyk.sparktest.WordCount
--master yarn \ # 指定任务提交的方式为yarn
--deploy-mode cluster \ # 指定yarn的部署方式为 cluster, 即由yarn创建的 ApplicationMaster来运行创建driver
./sparkextract.jar \ # 指定你要执行的jar包
10 # 设置默认的任务数量
最新文章
- linux 下压缩大批量文件
- Linux常用命令(一)
- 利用反卷积神经网络可视化CNN
- spring学习遇到的问题汇总
- SmartZoneOCR识别控件免费下载地址
- Session的实现与存储
- ubuntu service
- noip 2009 细胞分裂
- Currency 货币 filter
- js面向对象小结(工厂模式,构造函数,原型方法,继承)
- c语言学习基础:[1]开发工具介绍
- HTML基础上
- dedecsm系统(企业简介)类单栏目模版如何修改和调用整理
- ORA-00471: DBWR process terminated with error案例
- MM-委外业务
- Linux 使用nexus搭建maven私服
- sublime lincense for linux
- Redis 常用监控信息命令总结
- 转csdn某位同学的 感谢bmfont
- Mysql(五) JDBC