论文解读(SCGC))《Simple Contrastive Graph Clustering》
论文信息
论文标题:Simple Contrastive Graph Clustering
论文作者:Yue Liu, Xihong Yang, Sihang Zhou, Xinwang Liu
论文来源:2022,arXiv
论文地址:download
论文代码:download
1 Introduction
贡献:
- 提出了一种简单的对比深度图聚类方法,称为 $\text{SCGC}$。$\text{SCGC}$ 不需要预训练,并为网络训练节省时间和空间;
- 提出了一种新的仅在增强的属性空间中进行数据扰动的数据增强方法;
- 设计了一种新的面向邻居的对比损失,以保持跨视图的结构一致性;
2 Method
2.1 Notations and Problem Definition

其中:
- $\widehat{\mathbf{A}}=\mathbf{A}+\mathbf{I}$
- $\mathbf{L}=\mathbf{D}-\mathbf{A}$
- $\widetilde{\mathbf{L}}=\widehat{\mathbf{D}}^{-\frac{1}{2}} \widehat{\mathbf{L}} \widehat{\mathbf{D}}^{-\frac{1}{2}}$
2.2 Overall Framework
整体框架:
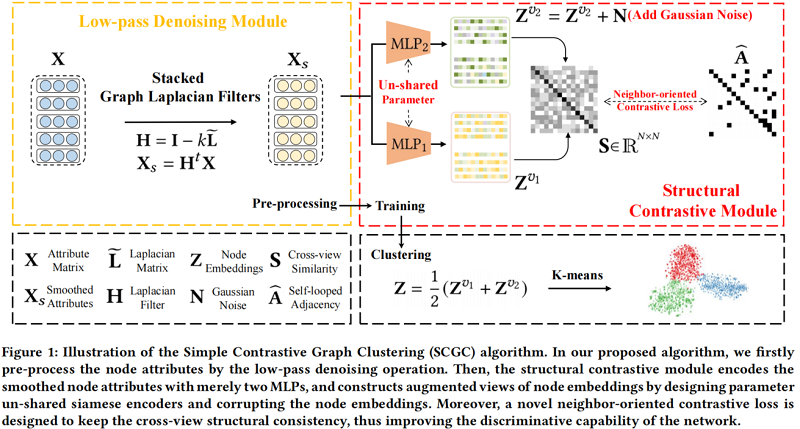
组成部分:
- low-pass denoising operation
- Structural Contrastive Module (SCM)
2.3 Low-pass Denoising Operation
[5, 18, 44] 证明了拉普拉斯滤波器可以达到与图卷积运算相同的效果。所以引入一个低通去噪操作,在训练前将邻居信息聚合作为一个独立的预处理。这样,属性中的高频噪声将被有效地过滤掉。
具体地说,采用了一个图的拉普拉斯滤波器作为公式:
$\mathbf{H}=\mathbf{I}-k \tilde{\mathbf{L}} \quad\quad\quad(1)$
$k$ 为实值,对于 $k$ 的选择,在所有实验中遵循 AGE[5] 并设置 $k=2 / 3$。随后,将 $t$ 层图拉普拉斯滤波器堆栈如下:
$\mathbf{X}_{s}=\mathbf{H}^{t} \mathbf{X} \quad\quad\quad(2)$
其中,$\widetilde{\mathbf{L}}$ 为平滑的属性矩阵。通过这种低通去噪操作,过滤掉了属性中的高频噪声,从而提高了聚类性能和训练效率。
2.4 Structural Contrastive Module
结构对比模块(SCM),保持两个不同的视图的结构一致性,从而提高网络的鉴别能力。
具体来说,首先用设计的参数非共享MLP编码器对平滑属性 $\mathbf{X}_{s}$ 进行编码,然后用 $\ell^{2}$-norm 对学习到的节点嵌入进行归一化如下
$\begin{array}{l}\mathbf{Z}^{v_{1}}=\operatorname{MLP}_{1}\left(\mathbf{X}_{s}\right), \mathbf{Z}^{v_{1}}=\frac{\mathbf{Z}^{v_{1}}}{\left\|\mathbf{Z}^{v_{1}}\right\|_{2}} \\\mathbf{Z}^{v_{2}}=\operatorname{MLP}_{2}\left(\mathbf{X}_{s}\right), \mathbf{Z}^{v_{2}}=\frac{\mathbf{Z}^{v_{2}}}{\left\|\mathbf{Z}^{v_{2}}\right\|_{2}}\end{array} \quad\quad\quad(3)$
其中,$\mathbf{Z}^{v_{1}}$ 和 $\mathbf{Z}^{v_{2}}$ 表示学习到的节点嵌入的两个增广视图。值得一提的是,$\mathrm{MLP}_{1}$ 和 $\mathrm{MLP}_{2}$ 具有相同的体系结构,但参数不共享,因此 $\mathbf{Z}^{v_{1}}$ 和 $\mathbf{Z}^{v_{2}}$ 在训练过程中会包含不同的语义信息。
此外,我们通过简单地在 $\mathbf{Z}^{v_{2}}$ 中加入随机高斯噪声,进一步保持了两种视图之间的差异:
$\mathbf{Z}^{v_{2}}=\mathbf{Z}^{v_{2}}+\mathbf{N} \quad\quad\quad(4)$
其中,$\mathbf{N} \in \mathbb{R}^{N \times d}$ 从高斯分布 $\mathcal{N}(0, \sigma)$ 中采样。总之,我们通过设计参数非共享编码器,直接破坏节点嵌入,而不是对图引入复杂的操作,构造了两个增强视图 $\mathbf{Z}^{v_{1}} $ 和 $\mathbf{Z}^{v_{2}} $,从而提高了训练效率。此外,[17,28,32]最近的研究表明,图上的复杂数据扩充,如加边、掉边和图扩散,可能会导致语义漂移。
随后,我们设计了一种新的面向邻居的对比损失来保持横视图结构的一致性。具体地,我们计算 $\mathbf{Z}^{v_{1}}$ 和 $\mathbf{Z}^{v_{2}}$ 之间的交叉视点样本相似矩阵 $\mathbf{S} \in \mathbb{R}^{N \times N} $:
$\mathbf{S}_{i j}=\mathbf{Z}_{i}^{v_{1}} \cdot\left(\mathbf{Z}_{j}^{v_{2}}\right)^{\mathrm{T}}, \forall i, j \in[1, N] \quad\quad\quad(5)$
其中,$\mathbf{S}_{i j}$ 表示第一个视图中第 $i$ 个节点嵌入与第二个视图中第 $j$ 个节点嵌入的余弦相似度。然后,我们强制交叉视图样本相似度矩阵 $\mathbf{S}$ 等于自环邻接矩阵 $\widehat{\mathbf{A}} \in \mathbb{R}^{N \times N}$,公式如下:
$\begin{aligned}\mathcal{L} &=\frac{1}{N^{2}} \sum\limits _{(\mathbf{S}-\widehat{\mathbf{A}})^{2}} \\&=\frac{1}{N^{2}}\left(\sum\limits _{i} \sum\limits _{j} \mathbb{1}_{i j}^{1}\left(\mathbf{S}_{i j}-1\right)^{2}+\sum\limits _{i} \sum\limits _{j} \mathbb{1}_{i j}^{0} \mathbf{S}_{i j}^{2}\right)\end{aligned} \quad\quad\quad(6)$
其中,$\mathbb{1}_{i j}^{1}$ 表示如果 $\widehat{\mathbf{A}}_{i j}=1$,$\mathbb{1}_{i j}^{0}$ 表示如果 $\widehat{\mathbf{A}}_{i j}=0$。在这里,我们将同一节点的交叉视图邻居视为正样本,而将其他非邻居节点视为负样本。然后我们把阳性样本拉在一起,同时推开阴性样本。更准确地说,在 $\text{Eq.6}$ 中,第一项迫使节点即使在两个不同的视图中也与它们的邻居保持一致,而第二项则使节点与其非邻居之间的一致最小化。这种面向邻居的对比目标函数通过保持交叉视图结构的一致性,增强了我们网络的鉴别能力,从而提高了聚类性能。
2.5 Fusion and Clustering
在本节中,我们首先以线性的方式融合节点嵌入的两个增强视图,公式如下:
$\mathbf{Z}=\frac{1}{2}\left(\mathbf{Z}^{v_{1}}+\mathbf{Z}^{v_{2}}\right) \quad\quad\quad(7)$
其中,$\mathbf{Z} \in \mathbb{R}^{N \times d}$ 表示生成的面向聚类的节点嵌入。然后在 $\mathbf{Z}$ 上直接执行K-means算法[10],得到聚类结果。
2.6 Algorithm

3 Experiment
数据集
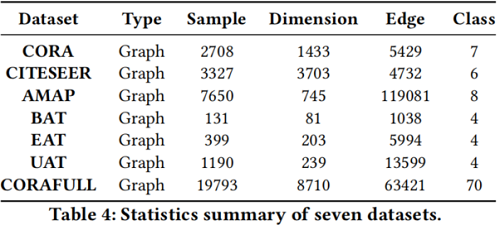
聚类实验
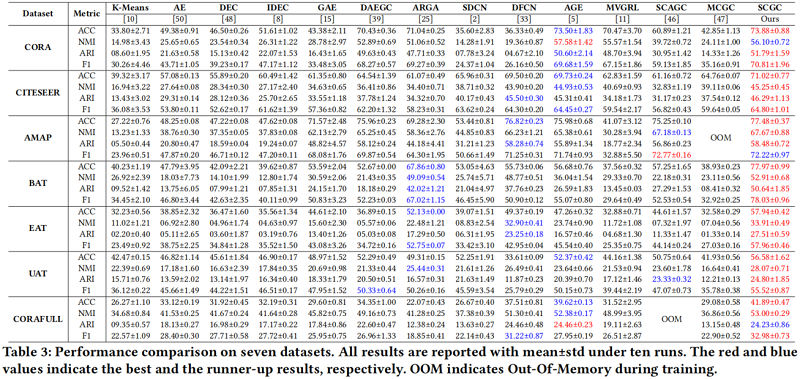
时间成本和GPU内存成本

消融实验

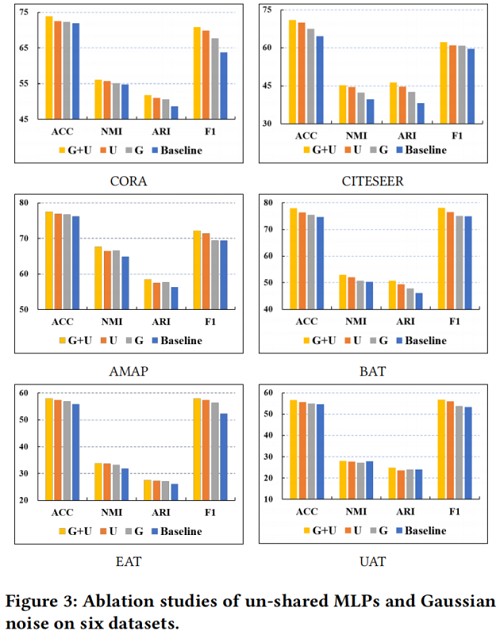
4 Conclusion
本文提出了一种对比深度图聚类方法,即简单对比图聚类(SCGC),从网络架构、数据增强和目标函数等方面改进了现有的方法。至于架构我们的网络主要包括预处理和网络骨干两个部分。具体地说,一个简单的低通去噪操作将邻居信息聚合作为一个独立的预处理。通过该操作,我们有效地过滤掉了属性中的高频噪声,从而提高了聚类性能。此外,只有两个mlp作为骨干。对于数据增强,我们通过设置参数非共享的编码器和破坏节点嵌入来构造不同的图视图,而不是在图上引入复杂的操作。此外,我们提出了一种新的面向邻居的对比损失来保持横视图结构的一致性,从而提高了网络的鉴别能力。得益于SCGC的简单性,它不需要预训练,并且节省了网络训练的时间和空间。值得注意的是,我们的算法优于最近的对比深度聚类竞争对手,平均加速速度至少为7倍。在7个数据集上的大量实验结果证明了SCGC的有效性和优越性。今后,为大规模图数据设计深度图聚类方法是值得尝试的。
最新文章
- CSS Position 定位属性
- codeforces 446C DZY Loves Fibonacci Numbers 线段树
- PHP面向对象 三大特性
- JS魔法堂:从void 0 === undefined说起
- 解决IDEA自动重置LanguageLevel和JavaCompiler版本的问题
- 最大乘积 Maximun Product
- JSONObject简介
- 0506团队项目-Scrum 项目1.0
- js实现(全选)多选按钮
- Emacs简易教程
- Android String 转 MD5
- PKCS#12
- 深入理解 JavaScript 事件循环(二)— task and microtask
- mkfs -t ext3 错误/dev/sdxx is apparently in use by the system; 解决方法
- easyui datagrid使用按钮
- Spark入门到精通--(第八节)环境搭建(Hadoop搭建)
- centos查看自启动服务
- java学习——异常处理
- c#实战开发:以太坊钱包对接私链 (二)
- Linux的Bash Shell详解
热门文章
- 11_二阶系统的单位阶跃响应_详细数学推导部分_2nd order system unit step response
- Solution Architect
- InfoQ Trends Report
- React 和 ES6 工作流之 Webpack的使用(第六部分)
- JavaScript 遍历对象、数组总结
- html显示与隐藏元素的几种方式
- 《手把手教你》系列基础篇(八十七)-java+ selenium自动化测试-框架设计基础-Log4j 2实现日志输出-上篇(详解教程)
- Jx.Cms开发笔记(一)-Jx.Cms介绍
- Postman+newman+jenkins+git实战
- acwing刷题-放养又没有完全放养