Hash冲突以及解决
2024-10-17 13:25:53
哈希函数:它把一个大范围的数字哈希(转化)成一个小范围的数字,这个小范围的数对应着数组的下标。使用哈希函数向数组插入数据后,这个数组就是哈希表。
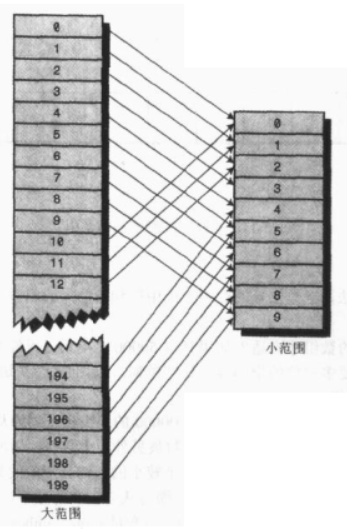
冲突
当冲突产生时,一个方法是通过系统的方法找到数组的一个空位,并把这个单词填入,而不再用哈希函数得到数组的下标,这种方法称为开放地址法。
组的每个数据项都创建一个子链表或子数组,那么数组内不直接存放单词,当产生冲突时,新的数据项直接存放到这个数组下标表示的链表中,这种方法称为链地址法。
开放地址法
线性探测: 它沿着数组下标一步一步顺序的查找空白单元。
二次探测: 思想是探测相距较远的单元,而不是和原始位置相邻的单元。
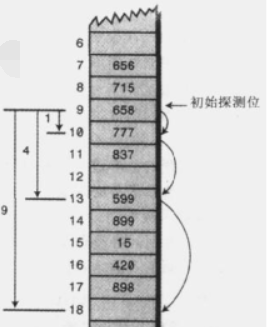
再哈希法:再来一次Hash找位置
链地址法
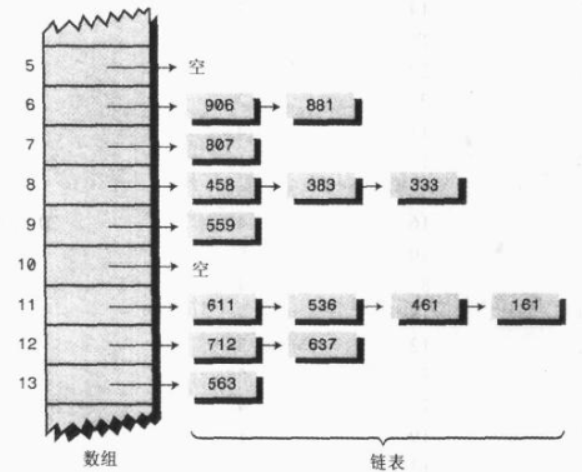
自己写“Hash”
线性探测
public class MyHashTable {
private DataItem[] hashArray; //DataItem类,表示每个数据项信息
private int arraySize;//数组的初始大小
private int itemNum;//数组实际存储了多少项数据
private DataItem nonItem;//用于删除数据项
public MyHashTable(int arraySize){
this.arraySize = arraySize;
hashArray =new DataItem[arraySize];
nonItem =new DataItem(-1);//删除的数据项下标为-1
}
//判断数组是否存储满了
public boolean isFull(){
return (itemNum == arraySize);
}
//判断数组是否为空
public boolean isEmpty(){
return (itemNum ==0);
}
//打印数组内容
public void display(){
System.out.println("Table:");
for(int j =0 ; j < arraySize ; j++){
if(hashArray[j] !=null){
System.out.print(hashArray[j].getKey() +" ");
}else{
System.out.print("** ");
}
}
}
//通过哈希函数转换得到数组下标
public int hashFunction(int key){
return key%arraySize;
}
//插入数据项
public void insert(DataItem item){
if(isFull()){
//扩展哈希表
System.out.println("哈希表已满,重新哈希化...");
extendHashTable();
}
int key = item.getKey();
int hashVal = hashFunction(key);
while(hashArray[hashVal] !=null && hashArray[hashVal].getKey() != -1){
++hashVal;
hashVal %= arraySize;
}
hashArray[hashVal] = item;
itemNum++;
}
/**
* 数组有固定的大小,而且不能扩展,所以扩展哈希表只能另外创建一个更大的数组,然后把旧数组中的数据插到新的数组中。
* 但是哈希表是根据数组大小计算给定数据的位置的,所以这些数据项不能再放在新数组中和老数组相同的位置上。
* 因此不能直接拷贝,需要按顺序遍历老数组,并使用insert方法向新数组中插入每个数据项。
* 这个过程叫做重新哈希化。这是一个耗时的过程,但如果数组要进行扩展,这个过程是必须的。
*/
public void extendHashTable(){
int num = arraySize;
itemNum =0;//重新计数,因为下面要把原来的数据转移到新的扩张的数组中
arraySize *=2;//数组大小翻倍
DataItem[] oldHashArray = hashArray;
hashArray =new DataItem[arraySize];
for(int i =0 ; i < num ; i++){
insert(oldHashArray[i]);
}
}
//删除数据项
public DataItem delete(int key){
if(isEmpty()){
System.out.println("Hash Table is Empty!");
return null;
}
int hashVal = hashFunction(key);
while(hashArray[hashVal] !=null){
if(hashArray[hashVal].getKey() == key){
DataItem temp = hashArray[hashVal];
hashArray[hashVal] = nonItem;//nonItem表示空Item,其key为-1
itemNum--;
return temp;
}
++hashVal;
hashVal %= arraySize;
}
return null;
}
//查找数据项
public DataItem find(int key){
int hashVal = hashFunction(key);
while(hashArray[hashVal] !=null){
if(hashArray[hashVal].getKey() == key){
return hashArray[hashVal];
}
++hashVal;
hashVal %= arraySize;
}
return null;
}
public static class DataItem{
private int iData;
public DataItem(int iData){
this.iData = iData;
}
public int getKey(){
return iData;
}
}
}
再Hash
public class HashDouble {
private DataItem[] hashArray; //DataItem类,表示每个数据项信息
private int arraySize;//数组的初始大小
private int itemNum;//数组实际存储了多少项数据
private DataItem nonItem;//用于删除数据项
public HashDouble(){
this.arraySize =13;
hashArray =new DataItem[arraySize];
nonItem =new DataItem(-1);//删除的数据项下标为-1
}
//判断数组是否存储满了
public boolean isFull(){
return (itemNum == arraySize);
}
//判断数组是否为空
public boolean isEmpty(){
return (itemNum ==0);
}
//打印数组内容
public void display(){
System.out.println("Table:");
for(int j =0 ; j < arraySize ; j++){
if(hashArray[j] !=null){
System.out.print(hashArray[j].getKey() +" ");
}else{
System.out.print("** ");
}
}
}
//通过哈希函数转换得到数组下标
public int hashFunction1(int key){
return key%arraySize;
}
public int hashFunction2(int key){
return 5 - key%5;
}
//插入数据项
public void insert(DataItem item){
if(isFull()){
//扩展哈希表
System.out.println("哈希表已满,重新哈希化...");
extendHashTable();
}
int key = item.getKey();
int hashVal = hashFunction1(key);
int stepSize = hashFunction2(key);//用第二个哈希函数计算探测步数
while(hashArray[hashVal] !=null && hashArray[hashVal].getKey() != -1){
hashVal += stepSize;
hashVal %= arraySize;//以指定的步数向后探测
}
hashArray[hashVal] = item;
itemNum++;
}
/**
* 数组有固定的大小,而且不能扩展,所以扩展哈希表只能另外创建一个更大的数组,然后把旧数组中的数据插到新的数组中。
* 但是哈希表是根据数组大小计算给定数据的位置的,所以这些数据项不能再放在新数组中和老数组相同的位置上。
* 因此不能直接拷贝,需要按顺序遍历老数组,并使用insert方法向新数组中插入每个数据项。
* 这个过程叫做重新哈希化。这是一个耗时的过程,但如果数组要进行扩展,这个过程是必须的。
*/
public void extendHashTable(){
int num = arraySize;
itemNum =0;//重新计数,因为下面要把原来的数据转移到新的扩张的数组中
arraySize *=2;//数组大小翻倍
DataItem[] oldHashArray = hashArray;
hashArray =new DataItem[arraySize];
for(int i =0 ; i < num ; i++){
insert(oldHashArray[i]);
}
}
//删除数据项
public DataItem delete(int key){
if(isEmpty()){
System.out.println("Hash Table is Empty!");
return null;
}
int hashVal = hashFunction1(key);
int stepSize = hashFunction2(key);
while(hashArray[hashVal] !=null){
if(hashArray[hashVal].getKey() == key){
DataItem temp = hashArray[hashVal];
hashArray[hashVal] = nonItem;//nonItem表示空Item,其key为-1
itemNum--;
return temp;
}
hashVal += stepSize;
hashVal %= arraySize;
}
return null;
}
//查找数据项
public DataItem find(int key){
int hashVal = hashFunction1(key);
int stepSize = hashFunction2(key);
while(hashArray[hashVal] !=null){
if(hashArray[hashVal].getKey() == key){
return hashArray[hashVal];
}
hashVal += stepSize;
hashVal %= arraySize;
}
return null;
}
public static class DataItem{
private int iData;
public DataItem(int iData){
this.iData = iData;
}
public int getKey(){
return iData;
}
}
}
参考链接
https://www.cnblogs.com/ysocean/p/8032656.html
最新文章
- 从零3D基础入门XNA 4.0(1)——3D开发基础
- Nginx中FastCGI配置优化
- 我所理解的SoC
- GridView的 OnRowDataBound 事件用法
- 根据屏幕的宽度使用不同的css-文件
- Java完成最简单的WebService创建及使用(REST方式,Jersey框架)
- linux文件复制与权限赋值
- 20145225唐振远 实验二 "Java面向对象程序设计"
- AppCan相关网站
- int21 h
- 怎样使用pyinstaller打包
- php这样实现伪静态
- Gulp思维——Gulp高级技巧
- linux公社的大了免费在线android资料
- 在分布式数据库中CAP原理CAP+BASE
- GitHub下载克隆clone指定的分支tag代码
- Python基础之元组和字典
- python数据类型之内置方法
- 【ZeroMQ】1、ZeroMQ(java)入门之Requerst/Response模式
- 【struts2】<package>的配置
热门文章
- 面向对象编程(C++篇3)——析构
- CVE-2021-3129:Laravel远程代码漏洞复现分析
- 从SpringBoot到SpringCloudAlibaba简明教程(一):初识SpringBoot及其基础项目构建
- 【SVN】Please execute the 'Cleanup' command.
- bzoj5315/luoguP4517 [SDOI2018]战略游戏(圆方树,虚树)
- C++11移动语义之一(基本概念)
- java实现稀疏矩阵的压缩与解压
- redis整理:常用命令,雪崩击穿穿透原因及方案,分布式锁实现思路,分布式锁redission(更新中)
- 深入理解RPC—序列化
- React算法复杂度优化?