吴恩达老师机器学习课程chapter11——大规模机器学习
2024-10-21 06:09:35
吴恩达老师机器学习课程chapter11——大规模机器学习
本文是非计算机专业新手的自学笔记,高手勿喷。
本文仅作速查备忘之用,对应吴恩达(AndrewNg)老师的机器学期课程第十七章。
这是这次整理笔记的最后一次整理。
吴恩达老师的课程现在看来大部分很通俗易懂,但是代价就是缺少许多数学证明。
许多部分用来学习了解入门就比较合适,但是想要深究就不得不离开严格证明了,这就是这门课的局限了。
这门课后面还有一些没有整理,因为那部分更多是简单介绍,更缺少深入分析,就不整理了。
目录
在进行大规模机器学习之前,应该先通过学习曲线判断是否需要增加更多的样本。
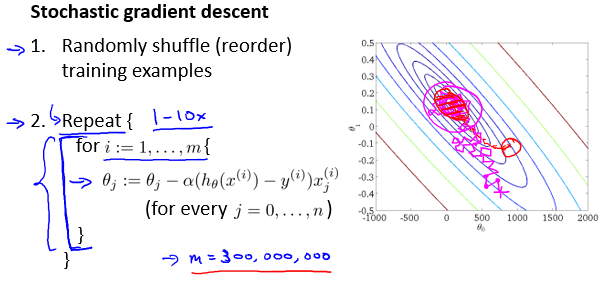
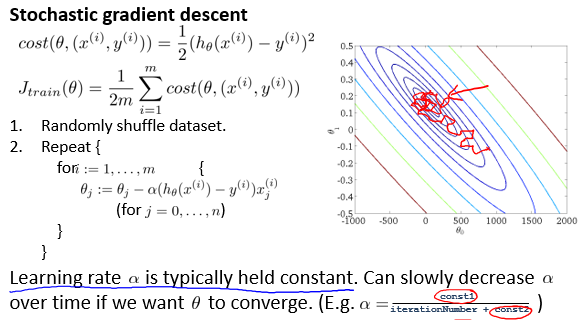
随机梯度下降(Stochastic gradient descent)
批量梯度下降法(Batch gradient descent):

“批量”是指每一次迭代都要考虑所有数据。
随机梯度下降法则避免了大规模累加操作,节省了时间。每一次迭代中只针对一个样本,每次都会改进一点。其优化轨迹并不总是指向最优解,会曲折迂回的向最优解收敛。
小批量梯度下降法(Mini-batch gradient descent)
与随机梯度法不一样的是,随机梯度法每次迭代只针对一个样本,而小批量梯度下降法每次针对一小组样本。

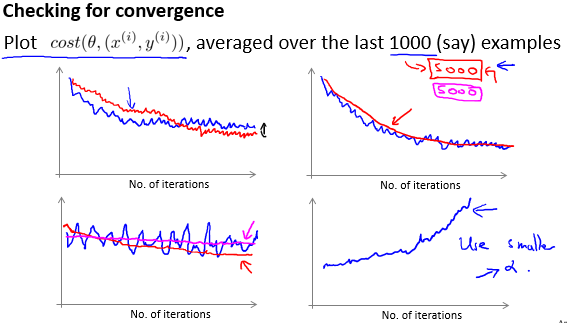
梯度下降是否收敛?
针对梯度下降法, 在实际工作中,可以通过绘图的方法查看是否收敛。

在随机梯度下降法中,举例来说,可以在每1000次迭代之后,计算前1000次的代价函数值,依次绘出函数图像,依次判断学习率大小是否合适。
可也以让学习率随着迭代增加而减少,保证收敛效果。
最新文章
- javascript的window.ActiveXObject对象,区别浏览器的方法
- .NET操作Xml类
- QTP全选页面的复选框
- tengine-2.1.0 + GraphicsMagick-1.3.20
- jenkins+git实现docker持续部署
- [复变函数]第15堂课 4.3 解析函数的 Taylor 展式
- delphi 712 Word 2
- 【原】Hadoop伪分布模式的安装
- Selenium html之于ul标志代码分析与使用
- Linux用户root忘记密码的解决(unbuntu16.04)
- Silk Mobile – 缩短移动应用的测试周期
- db2安装要设置tcp、ip
- Unity遮挡透明渐变
- js中替换字符串(replace方法最简单的应用)
- 基于LoadRunner11,以wifi热点方式录制APP脚本简单指导
- 【JavaWeb】图书管理系统【总结】
- MySQL/MariaDB的锁
- archlinux下安装acroread打开pdf
- Monkey脚本API
- luogu3702-[SDOI2017]序列计数