Scrapy爬取人人网
Scrapy发送Post请求


防止爬虫被反主要有以下几个策略
动态设置User-Agent(随机切换User-Agent,模拟不同用户的浏览器信息)
禁用Cookies(也就是不启用cookies middleware,不向Server发送cookies,有些网站通过cookie的使用发现爬虫行为)
可以通过COOKIES_ENABLED 控制 CookiesMiddleware 开启或关闭
设置延迟下载(防止访问过于频繁,设置为 2秒 或更高)
Google Cache 和 Baidu Cache:如果可能的话,使用谷歌/百度等搜索引擎服务器页面缓存获取页面数据。
使用IP地址池:VPN和代理IP,现在大部分网站都是根据IP来的。
Request/Response重要参数
request
url: 就是需要请求,并进行下一步处理的url
callback: 指定该请求返回的Response,由那个函数来处理。
method: 请求一般不需要指定,默认GET方法,可设置为"GET", "POST", "PUT"等,且保证字符串大写
headers: 请求时,包含的头文件。一般不需要
meta: 比较常用,在不同的请求之间传递数据使用的。字典dict型
encoding: 使用默认的 'utf-8' 就行。
dont_filter: 表明该请求不由调度器过滤。这是当你想使用多次执行相同的请求,忽略重复的过滤器。默认为False
Response
status: 响应码
_set_body(body): 响应体
_set_url(url):响应url
logging设置
通过在setting.py中进行以下设置可以被用来配置logging:
LOG_ENABLED 默认: True,启用logging
LOG_ENCODING 默认: 'utf-8',logging使用的编码
LOG_FILE 默认: None,在当前目录里创建logging输出文件的文件名
LOG_LEVEL 默认: 'DEBUG',log的最低级别
LOG_STDOUT 默认: False 如果为 True,进程所有的标准输出(及错误)将会被重定向到log中。例如,执行 print "hello" ,其将会在Scrapy log中显示。
开发工作中经常会加上以下两行:
LOG_FILE = “文件名.log"
LOG_LEVEL = "INFO"
爬取人人网
1.创建project
2.spider文件
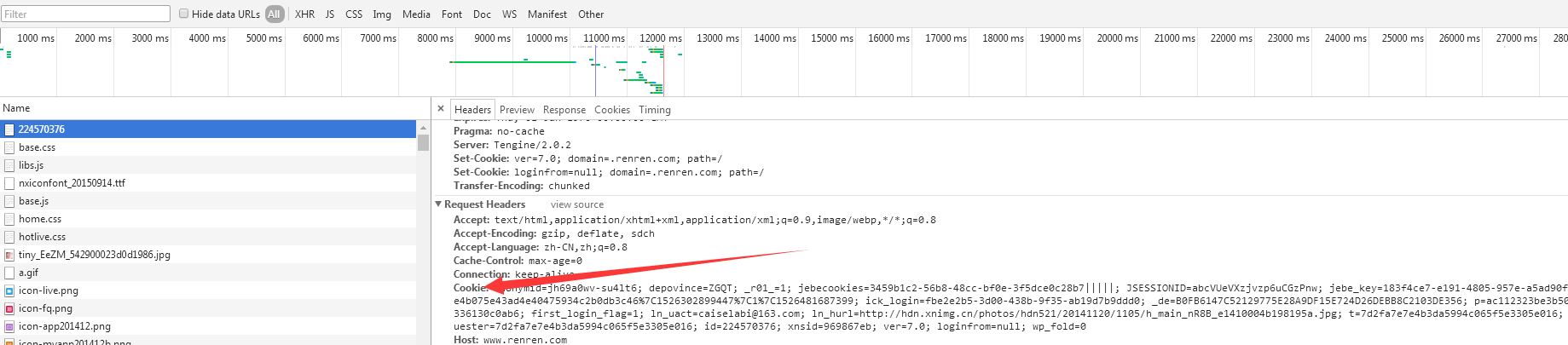

# -*- coding: utf-8 -*-
import scrapy class RenSpider(scrapy.Spider):
name = 'ren'
allowed_domains = ['renren.com']
start_urls = ['http://www.renren.com/224570376']
#
# def parse(self, response):
# pass
cookies ={
"anonymid":"jh7sb9et-4tc38k",
"depovince":"ZGQT",
"_r01_":"",
"JSESSIONID":"abchwEf-VGdFQ9MRUpKnw",
"ick_login":"aa78cdea-7fa6-4f6f-a5d4-1506323cb55e",
"jebecookies":"3b7201da-0aba-40b3-ad00-6b9d5808875e|||||",
"_de":"B0FB6147C52129775E28A9DF15E724D26DEBB8C2103DE356",
"p":"8353bac56f02e1e0172b6833946ea0076",
"first_login_flag":"",
"ln_uact":"caiselabi@111.com",
"ln_hurl":"http://hdn.xnimg.cn/photos/hdn521/20141120/1105/h_main_nR8B_e1410004b198195a.jpg",
"t":"ac38040778d340717a703a4900c225c46",
"societyguester":"ac38040778d340717a703a4900c225c46",
"id":"",
"xnsid":"9bb6c227",
"ver":"7.0",
"loginfrom":"null",
"jebe_key":"912e89dc-2c29-4be9-9ba4-1c5582b12e1d%7C8e4b075e43ad4e40475934c2b0db3c46%7C1526395913348%7C1%7C1526395915790",
"wp_fold":0
} def start_requests(self):
for url in self.start_urls:
yield scrapy.FormRequest(url=url,cookies=self.cookies,callback=self.parse) def parse(self, response):
print(response.body.decode()) # 打印源码文本
name = response.xpath('//p[@class="status"]/text()').extract_first()
with open('renren.txt','w',encoding='utf-8') as f:
f.write(name)
# name_element = '//p[@class="status]/text()'
# friend_element = '//div[@class="userhead"]/span/text()'
#
# def start_requests(self):
# url = "http://www.renren.com/PLogin.do"
#
# yield scrapy.FormRequest(
# url=url,
# formdata={"email":"caiselabi@111.com","password":"111111"},
# callback=self.parse
# )
# print('*'*30)
#
#
# def parse(self, response):
# print(response.body.decode()) # 打印源码文本
# name = response.xpath('//p[@class="status"]/text()').extract_first()
# print(name)
# friend =response.xpath('//div[@class="userhead"]/span/text()').extract_first()
# print(friend)
# # with open('renren.txt','w',encoding='utf-8') as f:
# # # f.write(name)
3.settings
BOT_NAME = 'renren' SPIDER_MODULES = ['renren.spiders']
NEWSPIDER_MODULE = 'renren.spiders' # Crawl responsibly by identifying yourself (and your website) on the user-agent
USER_AGENT = 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.221 Safari/537.36 SE 2.X MetaSr 1.0' # Obey robots.txt rules
ROBOTSTXT_OBEY = True # log日志
LOG_ENABLED = True # 默认: True,启用logging
LOG_FILE = 'renren.log'
LOG_LEVEL = 'DEBUG'
LOG_ENCODING = 'utf-8'
LOG_DATEFORMAT='%m/%d/%Y %H:%M:%S %p'
LOG_STDOUT = True
# 默认: False 如果为 True,进程所有的标准输出(及错误)将会被重定向到log中。例如,执行 print "hello" ,其将会在Scrapy log中显示
4.运行
scrapy crawl ren
最新文章
- sqlserver事务隔离小结
- js小例子(简单模糊匹配输入信息)
- 1. windows下作为应用程序启动apache的方法
- JKXY的视频内容下载工具类
- 3d touch 应用 2 -备用
- 通过Java字节码发现有趣的内幕之String篇(上)(转)
- 微软2017MVP大礼包拆箱攻略
- python----------装饰器应用练习
- Ubuntu(Linux)下如何用源码文件安装软件
- HDU - 1175 bfs
- Java课程设计常见技术问题(程序部署、数据库、JSP)
- Python开发【第二篇】运算符
- SQLServer无法打开用户默认数据库 登录失败错误4064的解决方法
- (转)Windows10下的docker安装与入门 (一)使用docker toolbox安装docker
- laravel框架一次请求的生命周期
- JS实现异步编程的4种方法
- jzoj2941
- SpringMVC中文件上传
- springboot项目启动报错
- 【BZOJ】1646: [Usaco2007 Open]Catch That Cow 抓住那只牛(bfs)