Lucene系列五:Lucene索引详解(IndexWriter详解、Document详解、索引更新)
一、IndexWriter详解
问题1:索引创建过程完成什么事?
分词、存储到反向索引中
1. 回顾Lucene架构图:

介绍我们编写的应用程序要完成数据的收集,再将数据以document的形式用lucene的索引API创建索引、存储。 这里重点要强调应用代码负责做什么,lucene负责做什么。
2. Lucene索引创建API 图示
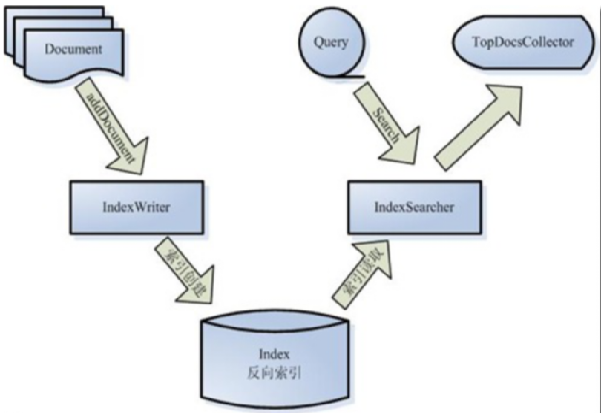
通过该图介绍lucene创建索引的核心API:Document、IndexWriter
Lucene中要索引的文档、数据记录以document表示,应用程序通过IndexWirter将Document加入到索引中。
3. Lucene索引创建代码示例
public static void main(String[] args) throws IOException {
// 创建使用的分词器
Analyzer analyzer = new IKAnalyzer4Lucene7(true);
// 索引配置对象
IndexWriterConfig config = new IndexWriterConfig(analyzer);
// 设置索引库的打开模式:新建、追加、新建或追加
config.setOpenMode(OpenMode.CREATE_OR_APPEND);
// 索引存放目录
// 存放到文件系统中
Directory directory = FSDirectory
.open((new File("f:/test/indextest")).toPath());
// 存放到内存中
// Directory directory = new RAMDirectory();
// 创建索引写对象
IndexWriter writer = new IndexWriter(directory, config);
// 创建document
Document doc = new Document();
// 往document中添加 商品id字段
doc.add(new StoredField("prodId", "p0001"));
// 往document中添加 商品名称字段
String name = "ThinkPad X1 Carbon 20KH0009CD/25CD 超极本轻薄笔记本电脑联想";
doc.add(new TextField("name", name, Store.YES));
// 将文档添加到索引
writer.addDocument(doc);
// .....
// 刷新
writer.flush();
// 提交
writer.commit();
// 关闭 会提交
writer.close();
directory.close();
}
上面示例代码对应的类图展示:

4. IndexWriterConfig 写索引配置:
使用的分词器,
如何打开索引(是新建,还是追加)。
还可配置缓冲区大小、或缓存多少个文档,再刷新到存储中。
还可配置合并、删除等的策略。
注意:
用这个配置对象创建好IndexWriter对象后,再修改这个配置对象的配置信息不会对IndexWriter对象起作用。
如要在indexWriter使用过程中修改它的配置信息,通过 indexWriter的getConfig()方法获得 LiveIndexWriterConfig 对象,在这个对象中可查看该IndexWriter使用的配置信息,可进行少量的配置修改(看它的setter方法)
5. Directory 指定索引数据存放的位置
内存
文件系统
数据库

保存到文件系统用法: Directory directory = FSDirectory.open(Path path); // path指定目录
保存到内存中用法:Directory directory = new RAMDirectory();
6. IndexWriter 用来创建、维护一个索引 。它的API使用流程:
// 创建索引写对象
IndexWriter writer = new IndexWriter(directory, config); // 创建document // 将文档添加到索引
writer.addDocument(doc); // 删除文档
//writer.deleteDocuments(terms); //修改文档
//writer.updateDocument(term, doc); // 刷新
writer.flush(); // 提交
writer.commit();
注意:IndexWriter是线程安全的。 如果你的业务代码中有其他的同步控制,请不要使用IndexWriter作为锁对象,以免死锁。
IndexWriter涉及类图示:

问题2: 索引库中会存储反向索引数据,会存储document吗?
索引库会存储一下关键的document信息
问:在百度、天猫上进行搜索,展示的列表中的数据来自哪里?源DB、FS 吗?
存在索引库里
二、Document详解
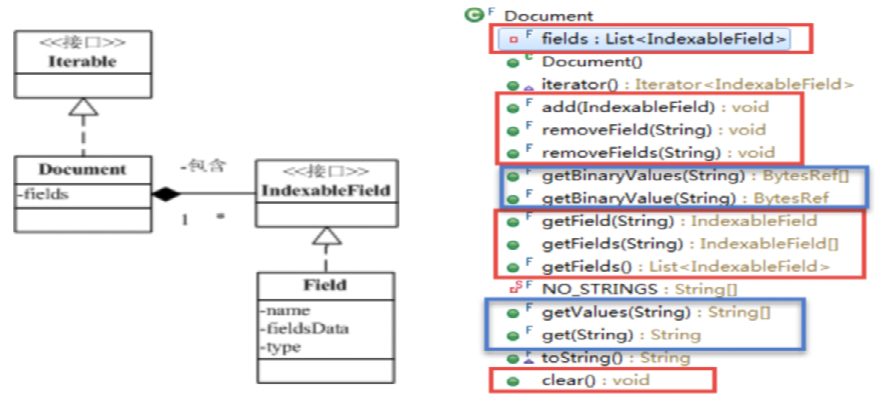
1. Document 文档
要索引的数据记录、文档在lucene中的表示,是索引、搜索的基本单元。一个Document由多个字段Field构成。就像数据库的记录-字段。
IndexWriter按加入的顺序为Document指定一个递增的id(从0开始),称为文档id。反向索引中存储的是这个id,文档存储中正向索引也是这个id。 业务数据的主键id只是文档的一个字段。
Document API
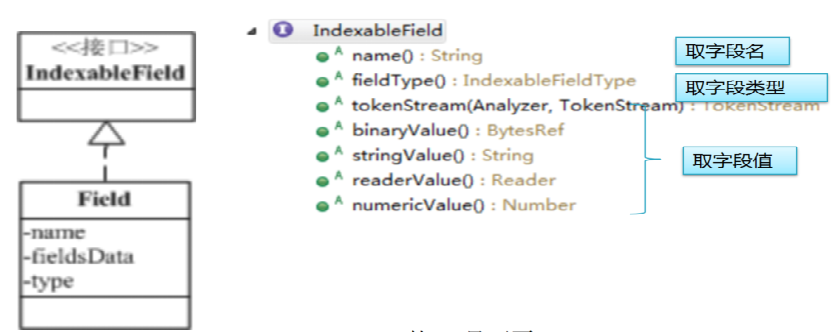
2. Field
字段:由字段名name、字段值value(fieldsData)、字段类型 type 三部分构成。
字段值可以是文本(String、Reader 或 预分析的 TokenStream)、二进制值(byte[])或数值。
IndexableField Field API

3. Document—Field 数据举例
新闻:新闻id,新闻标题、新闻内容、作者、所属分类、发表时间
网页搜索的网页:标题、内容、链接地址
商品: id、名称、图片链接、类别、价格、库存、商家、品牌、月销量、详情…
问题1:我们收集数据创建document对象来为其创建索引,数据的所有属性是否都需要加入到document中?如数据库表中的数据记录的所有字段是否都需要放到document中?哪些字段应加入到document中?
看具体的业务,只有需要被搜索和展示的字段才需要被加入到document中
问题2:是不是所有加入的字段都需要进行索引?是不是所有加入的字段都要保存到索引库中?什么样的字段该被索引?什么样的字段该被存储?
看具体的业务,需要被搜索的字段才该被索引,需要被展示的字段该被存储
问题3:各种要被索引的字段该以什么样的方式进行索引,全都是分词进行索引,还是有不同区别?
看是模糊查询还是精确查询,模糊查询的话就需要被分词索引,精确查询的话就不需要被分词索引
4. IndexableFieldType
字段类型:描述该如何索引存储该字段。
字段可选择性地保存在索引中,这样在搜索结果中,这些保存的字段值就可获得。
一个Document应该包含一个或多个存储字段来唯一标识一个文档。为什么?
为从原数据中拿完整数据去展示
5. Document 类关系
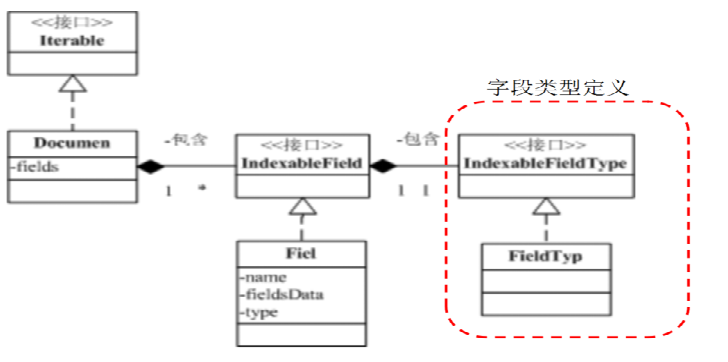
IndexableFieldType API 说明

6. IndexOptions 索引选项说明:
NONE:Not indexed 不索引
DOCS: 反向索引中只存储了包含该词的 文档id,没有词频、位置
DOCS_AND_FREQS: 反向索引中会存储 文档id、词频
DOCS_AND_FREQS_AND_POSITIONS:反向索引中存储 文档id、词频、位置
DOCS_AND_FREQS_AND_POSITIONS_AND_OFFSETS :反向索引中存储 文档id、词频、位置、偏移量
package com.study.lucene.indexdetail; import java.io.File;
import java.io.IOException; import org.apache.lucene.analysis.Analyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.document.Field;
import org.apache.lucene.document.FieldType;
import org.apache.lucene.index.IndexOptions;
import org.apache.lucene.index.IndexWriter;
import org.apache.lucene.index.IndexWriterConfig;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.FSDirectory; import com.study.lucene.ikanalyzer.Integrated.IKAnalyzer4Lucene7; /**
* 索引选项选择
*
* @author THINKPAD
*
*/
public class IndexOptionsDemo { public static void main(String[] args) {
// 创建使用的分词器
Analyzer analyzer = new IKAnalyzer4Lucene7(true); // 索引配置对象
IndexWriterConfig config = new IndexWriterConfig(analyzer); try ( // 索引存放到文件系统中
Directory directory = FSDirectory.open((new File("f:/test/indextest")).toPath()); // 创建索引写对象
IndexWriter writer = new IndexWriter(directory, config);) { // 准备document
Document doc = new Document();
// 字段content
String name = "content";
String value = "张三说的确实在理";
FieldType type = new FieldType();
// 设置是否存储该字段
type.setStored(true); // 请试试不存储的结果
// 设置是否对该字段分词
type.setTokenized(true); // 请试试不分词的结果
// 设置该字段的索引选项
type.setIndexOptions(IndexOptions.DOCS_AND_FREQS_AND_POSITIONS_AND_OFFSETS); // 请尝试不同的选项的效果
type.freeze(); // 使不可更改 Field field = new Field(name, value, type);
// 添加字段
doc.add(field);
// 加入到索引中
writer.addDocument(doc); } catch (IOException e) {
e.printStackTrace();
}
}
}
问题4:如果要在搜索结果中做关键字高亮,需要什么信息?如果要实现短语查询、临近查询(跨度查询),需要什么信息?
如 要搜索包含“张三” “李四”,且两词之间跨度不超过5个字符 。
需要位置和偏移量
问题5:位置、偏移数据在反向索引中占的存储量占比大不大?

看分词的数据量
问题6:如果某个字段不需要进行短语查询、临近查询,那么在反向索引中就不需要保存位置、偏移数据。这样是不是可以降低反向索引的数据量,提升效率?但是如果该字段要做高亮显示支持,该怎么办?。
为了提升反向索引的效率,这样的字段的位置、偏移数据是不应该保存到反向索引中的。这也你前面看到 IndexOptions为什么有那些选项的原因。
一个字段分词器分词后,每个词项会得到一系列属性信息,如 出现频率、位置、偏移量等,这些信息构成一个词项向量 termVectors
7. IndexableFieldType API
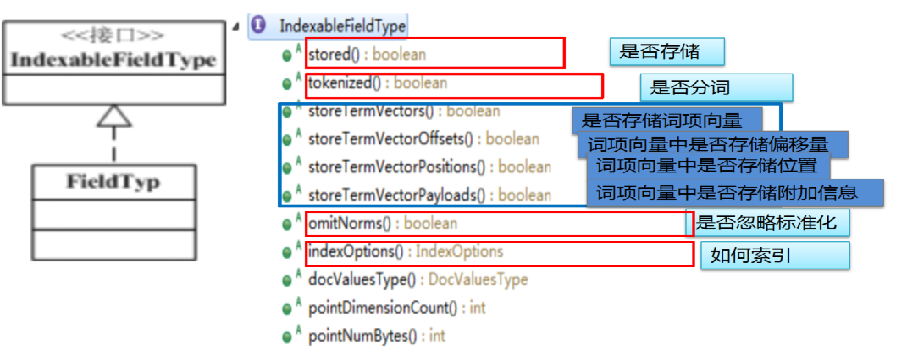
storeTermVectors:
对于不需要在搜索反向索引时用到,但在搜索结果处理时需要的位置、偏移量、附加数据(payLoad) 的字段,我们可以单独为该字段存储(文档id词项向量)的正向索引。
示例代码:
package com.study.lucene.indexdetail; import java.io.File;
import java.io.IOException; import org.apache.lucene.analysis.Analyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.document.Field;
import org.apache.lucene.document.FieldType;
import org.apache.lucene.index.IndexOptions;
import org.apache.lucene.index.IndexWriter;
import org.apache.lucene.index.IndexWriterConfig;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.FSDirectory; import com.study.lucene.ikanalyzer.Integrated.IKAnalyzer4Lucene7; /**
* 词向向量
* @author THINKPAD
*
*/
public class IndexTermVectorsDemo { public static void main(String[] args) {
// 创建使用的分词器
Analyzer analyzer = new IKAnalyzer4Lucene7(true); // 索引配置对象
IndexWriterConfig config = new IndexWriterConfig(analyzer); try ( // 索引存放到文件系统中
Directory directory = FSDirectory
.open((new File("f:/test/indextest")).toPath()); // 创建索引写对象
IndexWriter writer = new IndexWriter(directory, config);) { // 准备document
Document doc = new Document();
// 字段content
String name = "content";
String value = "张三说的确实在理";
FieldType type = new FieldType();
// 设置是否存储该字段
type.setStored(true); // 请试试不存储的结果
// 设置是否对该字段分词
type.setTokenized(true); // 请试试不分词的结果
// 设置该字段的索引选项
type.setIndexOptions(IndexOptions.DOCS); // 反向索引中只保存词项 // 设置为该字段保存词项向量
type.setStoreTermVectors(true);
type.setStoreTermVectorPositions(true);
type.setStoreTermVectorOffsets(true);
type.setStoreTermVectorPayloads(true); type.freeze(); // 使不可更改 Field field = new Field(name, value, type);
// 添加字段
doc.add(field);
// 加入到索引中
writer.addDocument(doc); } catch (IOException e) {
e.printStackTrace();
}
}
}
请为商品记录建立索引,字段信息如下:
商品id:字符串,不索引、但存储
String prodId = "p0001";
商品名称:字符串,分词索引(存储词频、位置、偏移量)、存储
String name = “ThinkPad X1 Carbon 20KH0009CD/25CD 超极本轻薄笔记本电脑";
图片链接:仅存储
String imgUrl = "http://www.cnblogs.com/leeSmall/";
商品简介:字符串,分词索引(不需要支持短语、临近查询)、存储,结果中支持高亮显示
String simpleIntro = "集成显卡 英特尔 酷睿 i5-8250U 14英寸";
品牌:字符串,不分词索引,存储
String brand = "ThinkPad";
package com.study.lucene.indexdetail; import java.io.File;
import java.io.IOException; import org.apache.lucene.analysis.Analyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.document.Field;
import org.apache.lucene.document.FieldType;
import org.apache.lucene.index.IndexOptions;
import org.apache.lucene.index.IndexWriter;
import org.apache.lucene.index.IndexWriterConfig;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.FSDirectory;
import org.apache.lucene.util.NumericUtils; import com.study.lucene.ikanalyzer.Integrated.IKAnalyzer4Lucene7; /**
* 为商品记录建立索引
* @author THINKPAD
*
*/
public class ProductIndexExercise { public static void main(String[] args) {
// 创建使用的分词器
Analyzer analyzer = new IKAnalyzer4Lucene7(true); // 索引配置对象
IndexWriterConfig config = new IndexWriterConfig(analyzer); try (
// 索引存放目录
// 存放到文件系统中
Directory directory = FSDirectory
.open((new File("f:/test/indextest")).toPath()); // 存放到内存中
// Directory directory = new RAMDirectory(); // 创建索引写对象
IndexWriter writer = new IndexWriter(directory, config);) { // 准备document
Document doc = new Document();
// 商品id:字符串,不索引、但存储
String prodId = "p0001";
FieldType onlyStoredType = new FieldType();
onlyStoredType.setTokenized(false);
onlyStoredType.setIndexOptions(IndexOptions.NONE);
onlyStoredType.setStored(true);
onlyStoredType.freeze();
doc.add(new Field("prodId", prodId, onlyStoredType)); // 商品名称:字符串,分词索引(存储词频、位置、偏移量)、存储
String name = "ThinkPad X1 Carbon 20KH0009CD/25CD 超极本轻薄笔记本电脑联想";
FieldType indexedAllStoredType = new FieldType();
indexedAllStoredType.setStored(true);
indexedAllStoredType.setTokenized(true);
indexedAllStoredType.setIndexOptions(
IndexOptions.DOCS_AND_FREQS_AND_POSITIONS_AND_OFFSETS);
indexedAllStoredType.freeze();
doc.add(new Field("name", name, indexedAllStoredType)); // 图片链接:仅存储
String imgUrl = "http://www.cnblogs.com/leeSmall/";
doc.add(new Field("imgUrl", imgUrl, onlyStoredType)); // 商品简介:文本,分词索引(不需要支持短语、临近查询)、存储,结果中支持高亮显示
String simpleIntro = "集成显卡 英特尔 酷睿 i5-8250U 14英寸";
FieldType indexedTermVectorsStoredType = new FieldType();
indexedTermVectorsStoredType.setStored(true);
indexedTermVectorsStoredType.setTokenized(true);
indexedTermVectorsStoredType
.setIndexOptions(IndexOptions.DOCS_AND_FREQS);
indexedTermVectorsStoredType.setStoreTermVectors(true);
indexedTermVectorsStoredType.setStoreTermVectorPositions(true);
indexedTermVectorsStoredType.setStoreTermVectorOffsets(true);
indexedTermVectorsStoredType.freeze(); doc.add(new Field("simpleIntro", simpleIntro,
indexedTermVectorsStoredType)); // 价格,整数,单位分,不索引、存储
int price = 2999900;
// Field 类有整数类型值的构造方法吗?
// 用字节数组来存储试试,还是转为字符串?
byte[] result = new byte[Integer.BYTES];
NumericUtils.intToSortableBytes(price, result, 0); doc.add(new Field("price", result, onlyStoredType)); writer.addDocument(doc); } catch (IOException e) {
e.printStackTrace();
} } }
问题7 :我们往往需要对搜索的结果支持按不同的字段进行排序,如商品搜索结果按价格排序、按销量排序等。以及对搜索结果进行按某字段分组统计,如按品牌统计。
存储的文档数据中(文档是行式存储) 就得把搜到的所有文档加载到内存中,来获取价格,再按价格排序。 如果搜到的文档列表量很大,会有什么问题没? 费内存 效率低 我们往往对结果列表是分页处理,并不需要把所有文档数据加载。
空间换时间:对这种需要排序、分组、聚合的字段,为其建立独立的文档->字段值的正向索引、列式存储。这样我们要加载搜中文档的这个字段的数据就快很多,耗内存少。
IndexableFieldType 中的 docValuesType方法 就是让你来为需要排序、分组、聚合的字段指定如何为该字段创建文档->字段值的正向索引的。
DocValuesType 选项说明:
NONE 不开启docvalue
NUMERIC 单值、数值字段,用这个
BINARY 单值、字节数组字段用
SORTED 单值、字符字段用, 会预先对值字节进行排序、去重存储
SORTED_NUMERIC 单值、数值数组字段用,会预先对数值数组进行排序
SORTED_SET 多值字段用,会预先对值字节进行排序、去重存储
具体使用选择:
字符串+单值 会选择SORTED作为docvalue存储
字符串+多值 会选择SORTED_SET作为docvalue存储
数值或日期或枚举字段+单值 会选择NUMERIC作为docvalue存储
数值或日期或枚举字段+多值 会选择SORTED_SET作为docvalue存储
注意:需要排序、分组、聚合、分类查询(面查询)的字段才创建docValues
8. 扩展整型Field
通过查看Filed的构造方法,发现里面没有设置整型数值的方法,所以需要我们自己来扩展

扩展的方法如下:
1. 扩展Field,提供构造方法传入数值类型值,赋给字段值字段;
2. 改写binaryValue() 方法,返回数值的字节引用。
package com.study.lucene.indexdetail.extendfield; import org.apache.lucene.document.Field;
import org.apache.lucene.document.FieldType;
import org.apache.lucene.util.BytesRef;
import org.apache.lucene.util.NumericUtils; /**
*
* @Description: 扩展整型Field
* @author liguangsheng
* @date 2018年5月11日
*
*/
public class ExtendIntField extends Field {
public ExtendIntField(String fieldName, int value, FieldType type) {
super(fieldName, type);
this.fieldsData = Integer.valueOf(value);
} @Override
public BytesRef binaryValue() {
byte[] bs = new byte[Integer.BYTES];
NumericUtils.intToSortableBytes((Integer) this.fieldsData, bs, 0);
return new BytesRef(bs);
}
}
9. Lucene预定义的字段子类

package com.study.lucene.indexdetail; import java.io.File;
import java.io.IOException; import org.apache.lucene.analysis.Analyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.document.Field;
import org.apache.lucene.document.Field.Store;
import org.apache.lucene.document.FieldType;
import org.apache.lucene.document.NumericDocValuesField;
import org.apache.lucene.document.SortedDocValuesField;
import org.apache.lucene.document.StringField;
import org.apache.lucene.index.DocValuesType;
import org.apache.lucene.index.IndexOptions;
import org.apache.lucene.index.IndexWriter;
import org.apache.lucene.index.IndexWriterConfig;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.FSDirectory;
import org.apache.lucene.util.BytesRef;
import org.apache.lucene.util.NumericUtils; import com.study.lucene.ikanalyzer.Integrated.IKAnalyzer4Lucene7; /**
* 索引的创建
*
* @author THINKPAD
*
*/
public class IndexWriteDemo { public static void main(String[] args) {
// 创建使用的分词器
Analyzer analyzer = new IKAnalyzer4Lucene7(true); // 索引配置对象
IndexWriterConfig config = new IndexWriterConfig(analyzer); try (
// 索引存放目录
// 存放到文件系统中
Directory directory = FSDirectory.open((new File("f:/test/indextest")).toPath()); // 存放到内存中
// Directory directory = new RAMDirectory(); // 创建索引写对象
IndexWriter writer = new IndexWriter(directory, config);) { // 准备document
Document doc = new Document();
// 商品id:字符串,不索引、但存储
String prodId = "p0001";
FieldType onlyStoredType = new FieldType();
onlyStoredType.setTokenized(false);
onlyStoredType.setIndexOptions(IndexOptions.NONE);
onlyStoredType.setStored(true);
onlyStoredType.freeze();
doc.add(new Field("prodId", prodId, onlyStoredType)); // 等同下一行
// doc.add(new StoredField("prodId", prodId)); // 商品名称:字符串,分词索引(存储词频、位置、偏移量)、存储
String name = "ThinkPad X1 Carbon 20KH0009CD/25CD 超极本轻薄笔记本电脑联想";
FieldType indexedAllStoredType = new FieldType();
indexedAllStoredType.setStored(true);
indexedAllStoredType.setTokenized(true);
indexedAllStoredType.setIndexOptions(IndexOptions.DOCS_AND_FREQS_AND_POSITIONS_AND_OFFSETS);
indexedAllStoredType.freeze(); doc.add(new Field("name", name, indexedAllStoredType)); // 图片链接:仅存储
String imgUrl = "http://www.cnblogs.com/aaa";
doc.add(new Field("imgUrl", imgUrl, onlyStoredType)); // 商品简介:文本,分词索引(不需要支持短语、临近查询)、存储,结果中支持高亮显示
String simpleIntro = "集成显卡 英特尔 酷睿 i5-8250U 14英寸";
FieldType indexedTermVectorsStoredType = new FieldType();
indexedTermVectorsStoredType.setStored(true);
indexedTermVectorsStoredType.setTokenized(true);
indexedTermVectorsStoredType.setIndexOptions(IndexOptions.DOCS_AND_FREQS);
indexedTermVectorsStoredType.setStoreTermVectors(true);
indexedTermVectorsStoredType.setStoreTermVectorPositions(true);
indexedTermVectorsStoredType.setStoreTermVectorOffsets(true);
indexedTermVectorsStoredType.freeze(); doc.add(new Field("simpleIntro", simpleIntro, indexedTermVectorsStoredType)); // 价格,整数,单位分,不索引、存储、要支持排序
int price = 999900;
FieldType numericDocValuesType = new FieldType();
numericDocValuesType.setTokenized(false);
numericDocValuesType.setIndexOptions(IndexOptions.NONE);
numericDocValuesType.setStored(true);
numericDocValuesType.setDocValuesType(DocValuesType.NUMERIC);
numericDocValuesType.setDimensions(1, Integer.BYTES);
numericDocValuesType.freeze(); doc.add(new MyIntField("price", price, numericDocValuesType)); // 与下两行等同
// doc.add(new StoredField("price", price));
// doc.add(new NumericDocValuesField("price", price)); // 类别:字符串,索引不分词,不存储、支持分类统计,多值
FieldType indexedDocValuesType = new FieldType();
indexedDocValuesType.setTokenized(false);
indexedDocValuesType.setIndexOptions(IndexOptions.DOCS);
indexedDocValuesType.setDocValuesType(DocValuesType.SORTED_SET);
indexedDocValuesType.freeze(); doc.add(new Field("type", "电脑", indexedDocValuesType) {
@Override
public BytesRef binaryValue() {
return new BytesRef((String) this.fieldsData);
}
});
doc.add(new Field("type", "笔记本电脑", indexedDocValuesType) {
@Override
public BytesRef binaryValue() {
return new BytesRef((String) this.fieldsData);
}
}); // 等同下四行
// doc.add(new StringField("type", "电脑", Store.NO));
// doc.add(new SortedSetDocValuesField("type", new BytesRef("电脑")));
// doc.add(new StringField("type", "笔记本电脑", Store.NO));
// doc.add(new SortedSetDocValuesField("type", new
// BytesRef("笔记本电脑"))); // 商家 索引(不分词),存储、按面(分类)查询
String fieldName = "shop";
String value = "联想官方旗舰店";
doc.add(new StringField(fieldName, value, Store.YES));
doc.add(new SortedDocValuesField(fieldName, new BytesRef(value))); // 上架时间:数值,排序需要
long upShelfTime = System.currentTimeMillis();
doc.add(new NumericDocValuesField("upShelfTime", upShelfTime)); writer.addDocument(doc); } catch (IOException e) {
e.printStackTrace();
} } public static class MyIntField extends Field { public MyIntField(String fieldName, int value, FieldType type) {
super(fieldName, type);
this.fieldsData = Integer.valueOf(value);
} @Override
public BytesRef binaryValue() {
byte[] bs = new byte[Integer.BYTES];
NumericUtils.intToSortableBytes((Integer) this.fieldsData, bs, 0);
return new BytesRef(bs);
}
} }
三、索引更新
IndexWriter 索引更新 API

说明:
Term 词项 指定字段的词项
删除流程:根据Term、Query找到相关的文档id、同时删除索引信息,再根据文档id删除对应的文档存储。
更新流程:先删除、再加入新的doc
注意:只可根据索引的字段进行更新。
package com.study.lucene.indexdetail; import java.io.File;
import java.io.IOException; import org.apache.lucene.analysis.Analyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.document.Field;
import org.apache.lucene.document.FieldType;
import org.apache.lucene.index.IndexOptions;
import org.apache.lucene.index.IndexWriter;
import org.apache.lucene.index.IndexWriterConfig;
import org.apache.lucene.index.Term;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.FSDirectory; import com.study.lucene.ikanalyzer.Integrated.IKAnalyzer4Lucene7; /**
* @Description: 索引更新
* @author liguangsheng
* @date 2018年5月11日
*
*/ public class IndexUpdateDemo { public static void main(String[] args) {
// 创建使用的分词器
Analyzer analyzer = new IKAnalyzer4Lucene7(true); // 索引配置对象
IndexWriterConfig config = new IndexWriterConfig(analyzer); try (
// 索引存放目录
// 存放到文件系统中
Directory directory = FSDirectory.open((new File("f:/test/indextest")).toPath()); // 存放到内存中
// Directory directory = new RAMDirectory(); // 创建索引写对象
IndexWriter writer = new IndexWriter(directory, config);) { // Term term = new Term("prodId", "p0001");
Term term = new Term("type", "笔记本电脑"); // 准备document
Document doc = new Document();
// 商品id:字符串,不索引、但存储
String prodId = "p0003";
FieldType onlyStoredType = new FieldType();
onlyStoredType.setTokenized(false);
onlyStoredType.setIndexOptions(IndexOptions.NONE);
onlyStoredType.setStored(true);
onlyStoredType.freeze();
doc.add(new Field("prodId", prodId, onlyStoredType)); writer.updateDocument(term, doc); // Term term = new Term("name", "笔记本电脑");
// writer.deleteDocuments(term); writer.flush(); writer.commit();
System.out.println("执行更新完毕。"); } catch (IOException e) {
e.printStackTrace();
} }
}
源码获取地址:
https://github.com/leeSmall/SearchEngineDemo
最新文章
- Yii2 基于RESTful架构的 advanced版API接口开发 配置、实现、测试 (转)
- JS存取Cookie值
- 添加AppWidget功能
- CSS hack的写法
- poj 1459 Power Network
- support vector regression与 kernel ridge regression
- Ext.Net学习笔记16:Ext.Net GridPanel 折叠/展开行
- [转]非常好的vsftpd安装于配置
- 全数字锁相环(DPLL)的原理简介以及verilog设计代码
- 检验身份证的正确性(C语言版本)
- Mac和Windows系统下Mysql数据库的导入导出
- 事务处理操作(COMMIT,ROLLBACK)。复制表。更新操作UPDATE实际工作中一般都会有WHERE子句,否则更新全表会影响系统性能引发死机。
- scrapy分布式的几个重点问题
- LeetCode 929.Unique Email Addresses
- Java中的super()使用注意
- Java基础_0304:构造方法
- PKCS 15 个标准
- 常用命令-python篇
- python之路-python字符编码
- K.O. -------- Eclipse中Maven的报错处理