解析导航栏的url
2024-09-12 21:39:16
前段时间做ui自动化测试的时候,导航栏菜单始终有点问题,最后只好直接获取到url,然后直接使用driver.get(url)进入页面;
包括做压测的时候,比如我要找出所有报表菜单的url,这样不可能手动去一个一个找出来,然后复制,这样浪费时间,并且也容易漏掉,所以我就写了个脚本来干这事;
首先说下思路:登录-->获取所有的a标签-->筛选掉不用的标签-->打印或者保存到文件中
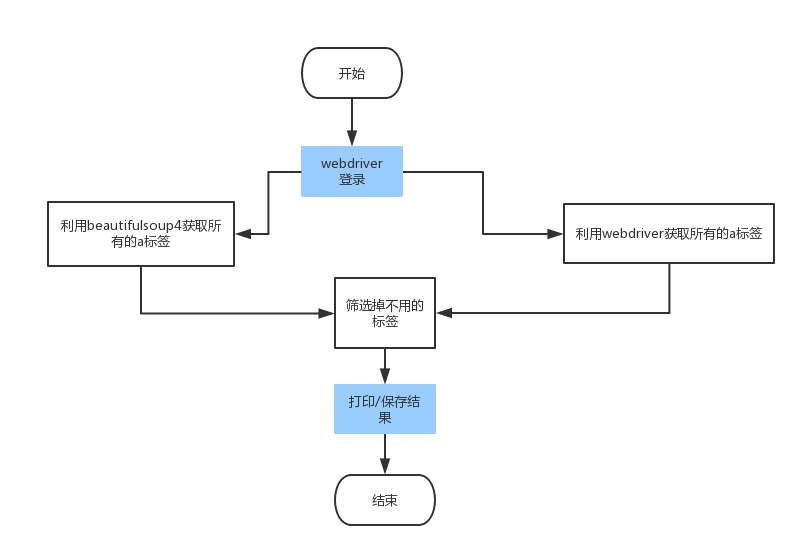
其中我获取页面所有的标签使用了两种方法,webdriver和beautifulsoup4,两种的区别:1、beautifulsoup4来解析的时候,比较稳定,并且速度快,2、webdriver可能简单一点吧,我推荐是用beautifulsoup4;之所以是用webdriver登录,是因为用webdriver登录简单,不像requests来请求的话,第一次还要分析url,参数之类的,用webdriver的话,只需要定位几个元素就ok了,何乐而不为呢。。。
下面我将两种方式的运行时间、最终的解析结果:

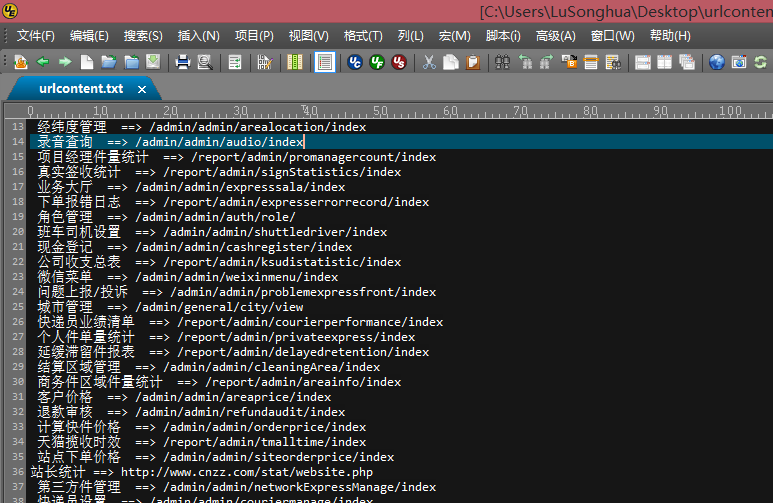
下面的是第一种方式:使用beautifulsoup4来解析:

1 #coding=utf-8
2
3 """
4 是为了获取XXX系统菜单的url
5 使用的是selenium登录,获取网页的内容,然后用beautifulsoup来解析
6 """
7 import unittest
8 import time
9 from selenium import webdriver
10 from bs4 import BeautifulSoup
11
12 # 登录url
13 url = 'http://XXXX.XXXX.com/' # 系统的url
14 username = 'XXXX'
15 password = 'XXXXX'
16
17 class GetUrl(unittest.TestCase):
18 def setUp(self):
19 self.dr = webdriver.Chrome()
20 self.dr.get(url)
21
22 def tearDown(self):
23 self.dr.quit()
24
25 def _login(self):
26 self.dr.find_element_by_id('username').send_keys(username) # 输入用户名
27 self.dr.find_element_by_id('password').send_keys(password) # 输入密码
28 # self.dr.find_element_by_id('verifycode').send_keys('XXXXX') 这里原来是需要验证码的,后来取消掉了
29 self.dr.find_element_by_id('weblogin').click() # 点击登录按钮
30 time.sleep(3)
31
32 def _gethtmlcontent(self):
33 """获取当前页面的html的所有内容"""
34 content = self.dr.page_source # 将该页面的内容 返回给content保存起来方便后面解析
35 return content
36
37 def _geturl(self,pagesource):
38 """
39 找出所有的a标签,然后筛选掉非导航连接的a标签。返回的是一个dict
40 """
41 result = dict()
42 soup = BeautifulSoup(pagesource, "lxml")
43 eles = soup.find_all("a")
44 flag = 0
45 for ele in eles:
46 if '#' in ele['href']:
47 continue
48 tmp = ele.string
49 if tmp is not None and '@' not in tmp:
50 flag += 1
51 ele_url = ele['href'].split('?')[0]
52 # print('{0} ==> {1}'.format(tmp,ele_url))
53 result[tmp] = ele_url
54
55 # print('Find out {0} datas.'.format(len(result)))
56 return result
57
58 def _writetotxt(self,contents):
59 """
60 将结果写入文件中
61 """
62 print('写入开始')
63 with open('urlcontent.txt','w') as f:
64 for title,value in contents.items():
65 f.write('{0} ==> {1}\n'.format(title,value))
66 print('写入完毕')
67
68 def test_run(self):
69 self._login()
70 pagesources = self._gethtmlcontent()
71 result = self._geturl(pagesources)
72 self._writetotxt(result)
73
74
75 if __name__ == '__main__':
76 unittest.main()
第二种全都是使用webdriver来解析的:
1 #coding=utf-8
2
3 """
4 是为了获取XXX系统菜单的url
5 使用的是selenium登录,查找元素,获取元素的属性
6 """
7 from selenium import webdriver
8 import unittest
9 import time
10
11 # 登录url
12 url = 'http://XXX.XXX.com/'
13 username = 'XXX'
14 password = 'XXX'
15
16 class GetUrl(unittest.TestCase):
17 def setUp(self):
18 self.dr = webdriver.Chrome()
19 self.dr.get(url)
20
21 def tearDown(self):
22 self.dr.quit()
23
24 def _login(self):
25 # time.sleep(2)
26 self.dr.find_element_by_id('username').send_keys(username)
27 self.dr.find_element_by_id('password').send_keys(password)
28 # self.dr.find_element_by_id('verifycode').send_keys('XXXXX')
29 self.dr.find_element_by_id('weblogin').click()
30 time.sleep(3)
31
32 def _geturl(self):
# 这里返回的是一个list,然后里面是一个个字典
33 result = list()
34 eles = self.dr.find_elements_by_css_selector('menu.u-menu a')
35 for ele in eles:
36 tmp = dict()
37 href = ele.get_attribute('href').split('?')[0]
38 # 获取菜单 的名称
39 name = ele.get_attribute('innerHTML')
40 if "<i>" not in name:
41 tmp['name'] = name.strip()
42 tmp['href'] = href
43 result.append(tmp)
44 # print('name: {0},href: {1}'.format(name,href))
45 return result
46
47 def _writetotxt(self,contents):
48 print("一共{0}条数据".format(len(contents)))
49 print('写入开始')
50 with open('urlcontent.txt','w') as f:
51 for content in contents:
52 f.write('{0} ==> {1}\n'.format(content['name'],content['href']))
53 print('写入完毕')
54
55 def test_run(self):
56 self._login()
57 self._writetotxt(self._geturl())
58
59
60 if __name__ == '__main__':
61 unittest.main()
好了,就到这里吧。。。
最新文章
- eclipse 搭建python环境
- 使用dom元素和jquery元素实现简单增删改的练习
- 使用HtmlAgilityPack抓取网页数据
- scrollView滚动(通过代码)
- 51nod贪心算法入门-----活动安排问题2
- Python学习入门教程,字符串函数扩充详解
- TNS-00512: Address already in use-TNS-12542: TNS:address already in use
- Struts2动态方法调用
- 读 Zepto 源码之内部方法
- QT制作一个图片播放器
- string [] 去除重复字符两个方法
- 补习系列(14)-springboot redis 整合-数据读写
- nginx 配置 HTTPS 及http 强制跳转https.
- centos通过Supervisor配置.net core守护进程
- Mybatis自动生成实体类,映射文件,dao
- 参数 out
- Python中网络编程对socket accept函数的理解
- SQL利用Case When Then多条件
- 点集转线python最优代码
- Best Time to Buy and Sell Stock leetcode java