step5: 编写spider爬取
2024-08-29 16:27:35
改写parse函数
实现功能:
1.获取文章列表页中的文章url并交给scrapy下载后,交给解析函数进行具体字段的解析
2.获取下一页的url并交给scrapy进行下载,下载完成后交给parse
提取一页列表中的文章url
#解析列表页中所有文章的url,遍历出来
def parse(self, response):
# 解析列表页中的所有url并交给scrapy下载后进行解析
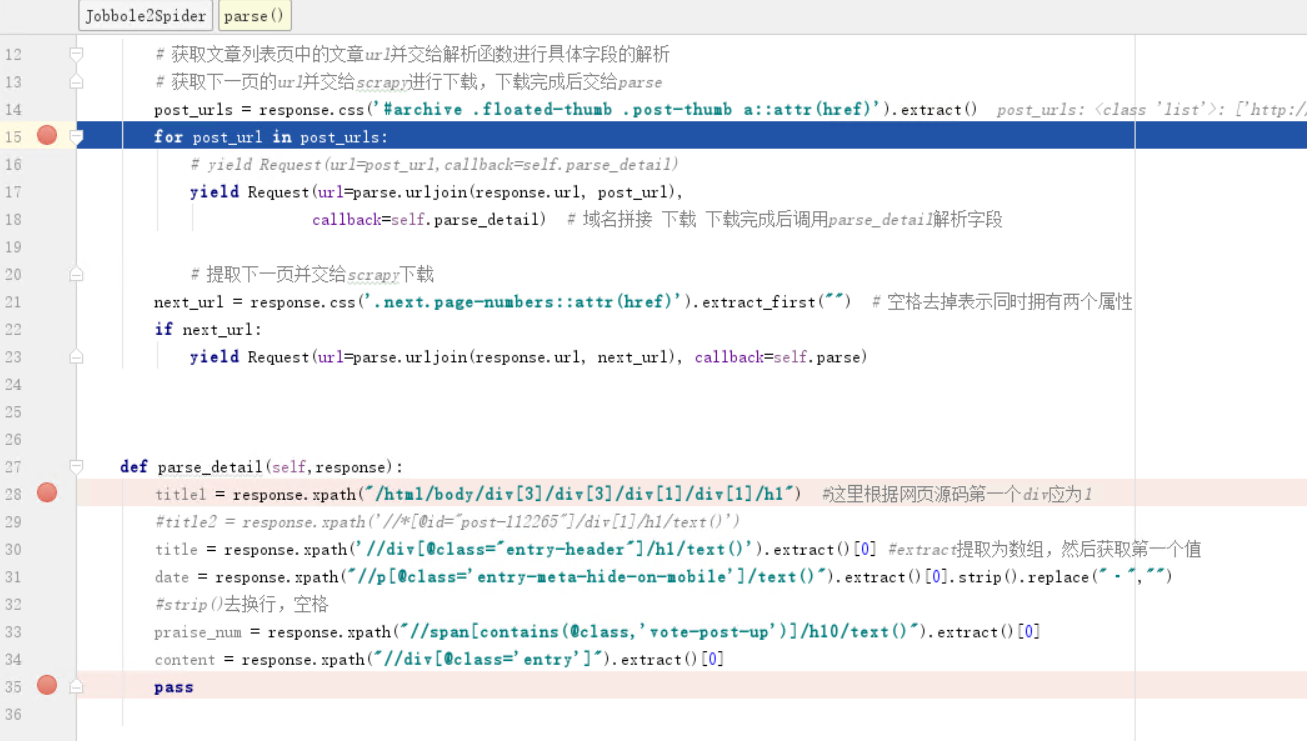
post_urls = response.css('#archive .floated-thumb .post-thumb a::attr(href)').extract()
for post_url in post_urls:
print(post_url)
调试输出结果

如何让scrapy进行下载
引入request对象
from scrapy.http import Request
修改提取字段类类名为parse_detail,引入parse类进行域名拼接,yield下载
from urllib import parse
def parse(self, response):
#获取文章列表页中的文章url并交给解析函数进行具体字段的解析
#获取下一页的url并交给scrapy进行下载,下载完成后交给parse
post_urls = response.css('#archive .floated-thumb .post-thumb a::attr(href)').extract()
for post_url in post_urls:
#yield Request(url=post_url,callback=self.parse_detail)
yield Request(url=parse.urljoin(response.url, post_url),callback=self.parse_detail) #域名拼接 下载 下载完成后调用parse_detail解析字段
获取下一页并交给scrapy进行下载
#提取下一页并交给scrapy下载
next_url = response.css('.next.page-numbers::attr(href)').extract_first("")#空格去掉表示同时拥有两个属性
if next_url:
yield Request(url=parse.urljoin(response.url, next_url), callback=self.parse) #继续调用parse解析出列表页中具体文章的url
调试前修改start_url为all-posts
调试结果
最新文章
- BMW
- mysql学习笔记 第六天
- Oracle语句优化之一
- ffmpeg-20160517-git-bin-v2
- json数据实际应用
- js 新窗口打开
- Codeforces Educational Codeforces Round 15 C. Cellular Network
- Swing多线程编程(转)
- 让Xcode Lua 语法高亮
- .dll 文件编写和使用
- 【原创】Android AOP面向切面编程AspectJ
- 用m4 macros创建文本文件
- Oracle和Mysql获取uuid的方法对比
- 黑盒测试实践-day02
- HTTP的Referrer和Referrer Policy设置
- CentOS系统中文改英文
- zabbix3.4.7 饼图显示问题
- 2018.09.14 codeforces364D(随机化算法)
- 【python】列出http://www.cnblogs.com/xiandedanteng中所有博文的标题
- spring boot 使用thymeleaf模版 报错:org.thymeleaf.exceptions.TemplateInputException
热门文章
- Replication--Alwayson+复制发布
- google chrome 调试技巧:监控 DOM 元素被修改
- Razor TagHelper实现Markdown转HTML
- 在.net Core中使用StackExchange.Redis 2.0
- sql 统计常用的sql
- MySQL不带where条件的UPDATE和DELETE 限制操作说明
- 【《Effective C#》提炼总结】提高Unity中C#代码质量的22条准则
- How to Mount a Remote Folder using SSH on Ubuntu
- 【转】【C++专题】C++ sizeof 使用规则及陷阱分析
- 2016级算法第一次练习赛-C.斐波那契进阶