海量推荐系统:mapreduce的方法
2024-10-21 02:57:38
1. Motivation
2. MapReduce
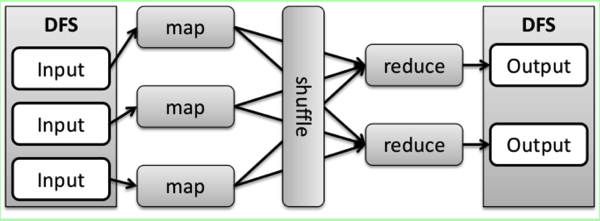
MapReduce是一种数据密集型并行计算框架。
待处理数据以“块”为单位存储在集群机器文件系统中(HDFS),并以(key, value)的键值对形式保存。
当任务启动时,系统将计算任务分配给存储数据的相应机器。
MapReduce计算任务可以划分为两个阶段:
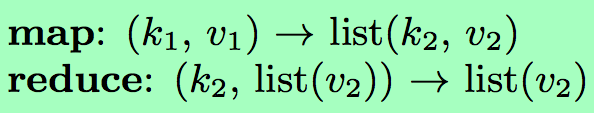
MapReduce数据流图
3. scalable similarity-based neighborhood
3.1 user-based 推荐
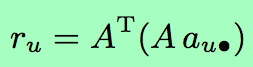
说明:
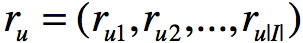 :user对商品的评分
:user对商品的评分
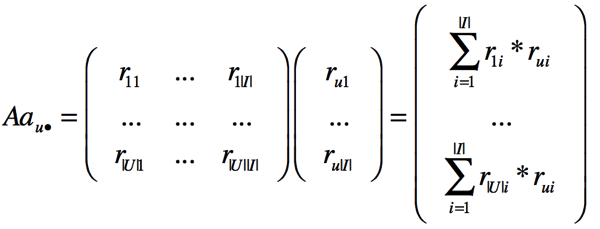 :得到了用户u与其他用户的相似度
:得到了用户u与其他用户的相似度
最后,对于某一商品i,根据其他用户的评分以及用户相似度加权和来得到本用户的预测评分。
之所以称之为user-based方法,算法基于计算用户间的相似度。
3.2 item-based推荐
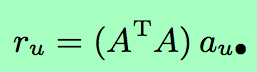
说明:
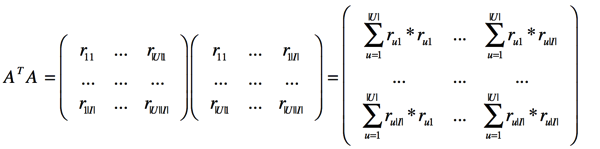
得到了物品的相似度矩阵。最后,用户u对物品i的打分就等于用户对物品的打分与物品i相似度的加权和。
因此,推荐系统的核心在于计算相似度矩阵
3.3 scalable计算方法
传统的相似度计算,基于标准的矩阵乘法。
不足之处:
1、在每一个map任务中,要初始化评分矩阵A,map时将输入的item与A的每一列做点乘。当矩阵A巨大时,内存消耗巨大。
2、传统计算方法复杂度与item数的平方成正比。并且,不能利用user评分稀疏性的性质。
改进的方法
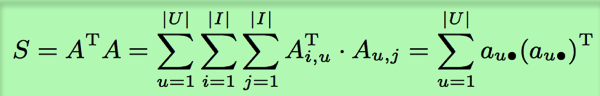
其中,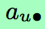 为列向量,为用户u的打分向量
为列向量,为用户u的打分向量
具体方法:
首先对每一个用户的评分向量做乘积。
然后将这些乘积相加,就得到了相似度矩阵。这样,就可以以A的行向量为单位进行数据的划分。
mapreduce计算框架

参考文献:
[1] Scalable Similarity-Based Neighborhood Methods with MapReduce
最新文章
- 上门洗车APP --- Androidclient开发 之 项目结构介绍
- Linus Torvalds来自开发商的消息:成就,不定
- java转发和重定向
- MFC中PeekMessage的使用,非阻塞消息循环
- php 常用代码段
- html自定义调控
- 在Linux系统上获取命令帮助信息和划分man文档
- Matlab:如何读取CSV文件以及如何读取带有字符串数据项的CSV文件
- SSM框架和SSH框架的区别
- IDEA主类文件需要放置在SRC文件下,非包内
- Mybatis数据源
- Rikka with Subset HDU - 6092 (DP+组合数)
- LeetCode - Word Subsets
- Java中的静态变量、静态方法问题
- Java基础-语法定义
- 【three.js练习程序】创建简单物理地形
- vdp配置
- Axios 使用采坑经验
- wireMock快速伪造restful服务
- Subversion Self Signed Certificates
热门文章
- 前端项目使用module.exports文件一定要Webpack编译吗?请问gulp可以编译这种文件吗
- 页面报错Uncaught SyntaxError: Unexpected identifier
- Xml日志记录文件最优方案(附源代码)
- Logstash详解之——input模块
- 开启 intel vt-d
- (转)C#程序开发中经常遇到的10条实用的代码
- GWT异步更改cellTable中cell的数据显示
- POJ 1276 Cash Machine(单调队列优化多重背包)
- 二叉搜索树的结构(30 分) PTA 模拟+字符串处理 二叉搜索树的节点插入和非递归遍历
- Java-API:java.util.list