sparkStreamming原理
一、Spark Streamming 是基于spark流式处理引擎,基本原理是将实时输入的数据以时间片(秒级)为单位进行拆分,然后经过spark引擎以类似批处理的方式处理每个时间片数据。
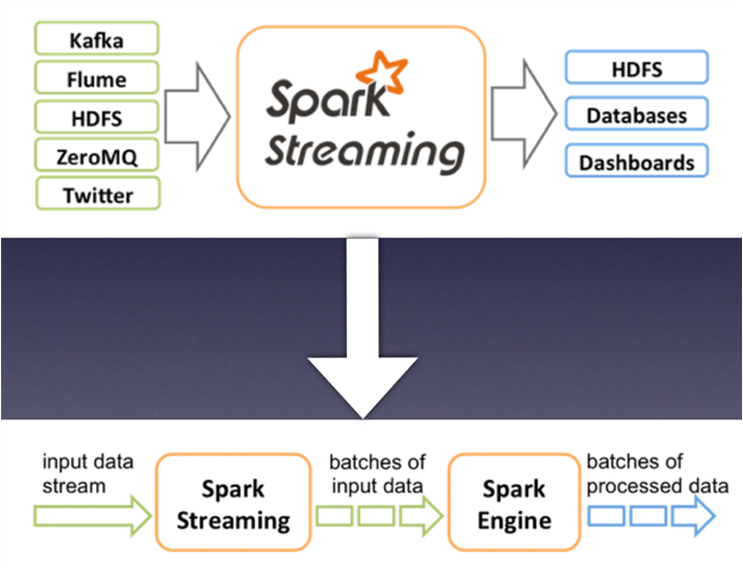
二、SparkStreamming作业流程
1、客户端提交作业后,启动Driver(Driver是spark作业的Master)
2、每个作业包含多个Excutor,每个Excutor都是以进程的方式运行Task,Spark Streamming至少包含一个Receiver task.
3、Receiver收到数据后生存Block,并把Block汇报给Driver,然后备份另外一个Excutor上面。
4、Receiver Tracker维护Receiver汇报的BlockId.
5、Driver定时自动JobGernerator,根据DS的关系生成逻辑RDD,然后创建jobSet,交给JobSchedule。
6、JobSchedule负责调度jobset,交给DAGSchedule, DAG Schedule根据逻辑RDD,生成对应的stages,每一个Stage包含一个或者多个Task。
7、Task Schedule负责吧Task调度到Excutor上,并维护Task的运行状态。
8、当Task,Stages, jobSet完成后,单个batch才算完成。
三、spark Streamming和Storm
流式系统的特点
低延迟,秒级或者更短的时间。
高性能。
分布式
可扩展,伴随着业务发展,数据量,计算量可能会越来越大,所以要求是可扩展的。
容错,分布式系统中的通用问题,一个节点挂了不能影响应用。
两者之间区别
同一套系统,安装spark之后,一切都有了。
spark有较强的容错能力,storm使用更广泛,更稳定。
storm是使用Clojure语言去写的,它的很多扩展都是使用Java完成的。
任务执行方面与storm的区别。
spark streamming 数据进来是一小段的RDD,数据进行切分成一小块,一小块进行批处理。
Storm是基于record形式来的,进来的是一个个的Tuple,进来一条就会处理一条。
中间过程实质上就是spark引擎,只不是spark streamming在spark之后引擎动了一些手脚,对进入spark引擎之前的数据进行了一个封装,方便进行基于时间片的小批量作业,交给spark进行计算。
最新文章
- 微信小程序-视图视图引用
- EBS中配置OAF
- Android Http请求
- T-SQL 语句创建Database的SQL mirroring关系
- EF6 Database First (DbContext) - Change Schema at runtime
- overflow之锚点技术实现选项卡
- C++ template随笔
- 核心基础以及Fragment与Activity传递数据完整示例
- python 密码学编程 -- 2
- python_控制台输出带颜色的文字方法
- PHP基础入门详解(一)【世界上最好用的编程语言】
- webapi 利用webapiHelp和swagger生成接口文档
- WebForm文件上传
- time模块的用法和转化关系
- 今日头条移动app广告激活数据API对接完整Java代码实现供大家参考》》》项目随记
- String、StringBuffer、StringBuilder区别
- centos7学习笔记-安装后的一些配置
- C#使用Xamarin开发Android应用程序 -- 系列文章
- Codeforces292D(SummerTrainingDay06-L 前缀并查集)
- ElasticSearch无法启动