Mysql数据实时同步
企业运维的数据库最常见的是 mysql;但是 mysql 有个缺陷:当数据量达到千万条的时候,mysql 的相关操作会变的非常迟缓; 如果这个时候有需求需要实时展示数据;对于 mysql 来说是一种灾难;而且对于 mysql 来说,同一时间还要给多个开发人员和用户操作; 所以经过调研,将 mysql 数据实时同步到 hbase 中;
最开始使用的架构方案:
Mysql---logstash—kafka---sparkStreaming---hbase---web
Mysql—sqoop---hbase---web
但是无论使用 logsatsh 还是使用 kafka,都避免不了一个尴尬的问题:
他们在导数据过程中需要去 mysql 中做查询操作:
比如 logstash:
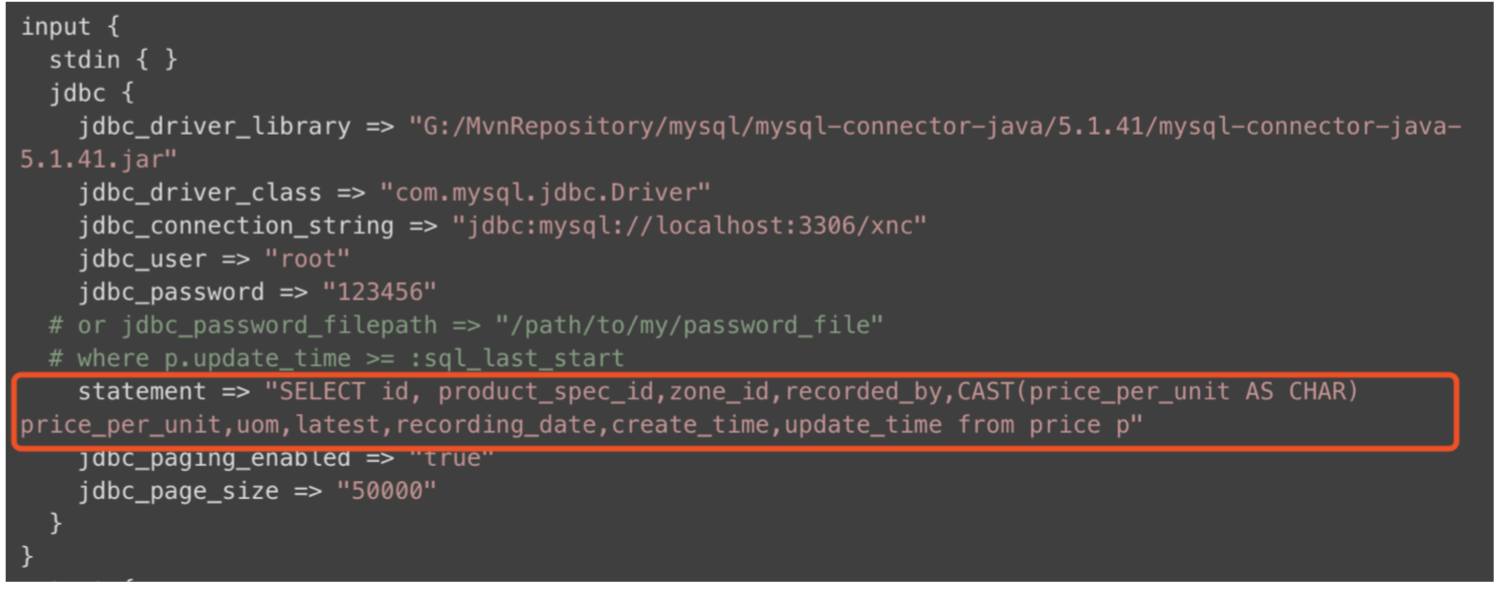
比如 sqoop:

不可避免的,都需要去 sql 中查询出相关数据,然后才能进行同步;这样对于 mysql 来说本身就是增加负荷操作; 所以我们真正需要考虑的问题是:有没有什么方法,能将 mysql 数据实时同步到 hbase;但是不增加 mysql 的负担; 答案是有的:可以使用 canal 或者 maxwell 来解析 mysql 的 binlog 日志
那么之前的架构就需要改动了:
Mysql---canal—kafka—flink—hbase—web
第一步:开启 mysql 的 binlog 日志
Mysql 的 binlog 日志作用是用来记录 mysql 内部增删等对 mysql 数据库有更新的内容的 记录(对数据库的改动),对数据库的查询 select 或 show 等不会被 binlog 日志记录;主 要用于数据库的主从复制以及增量恢复。
mysql 的 binlog 日志必须打开 log-bin 功能才能生存 binlog 日志
-rw-rw---- 1 mysql mysql 669 5 月 10 21:29 mysql-bin.000001
-rw-rw---- 1 mysql mysql 126 5 月 10 22:06 mysql-bin.000002
-rw-rw---- 1 mysql mysql 11799 5 月 15 18:17 mysql-bin.000003
(1):修改/etc/my.cnf,在里面添加如下内容
log-bin=/var/lib/mysql/mysql-bin 【binlog 日志存放路径】
binlog-format=ROW 【⽇日志中会记录成每⼀一⾏行行数据被修改的形式】
server_id=1 【指定当前机器的服务 ID(如果是集群,不能重复)】
(2):配置完毕之后,登录 mysql,输入如下命令:
show variables like ‘%log_bin%’

出现如下形式,代表 binlog 开启;
第二步:安装 canal
Canal 介绍 canal 是阿里巴巴旗下的一款开源项目,纯 Java 开发。基于数据库增量日志解析,提供增量数据订阅&消费,目前主要支持了 MySQL(也支持 mariaDB)。
起源:早期,阿里巴巴 B2B 公司因为存在杭州和美国双机房部署,存在跨机房同步的业务需求。不过早期的数据库同步业务,主要是基于 trigger 的方式获取增量变更,不过从 2010 年开始,阿里系公司开始逐步的尝试基于数据库的日志解析,获取增量变更进行同步,由此衍生出了增量订阅 &消费的业务,从此开启了一段新纪元。
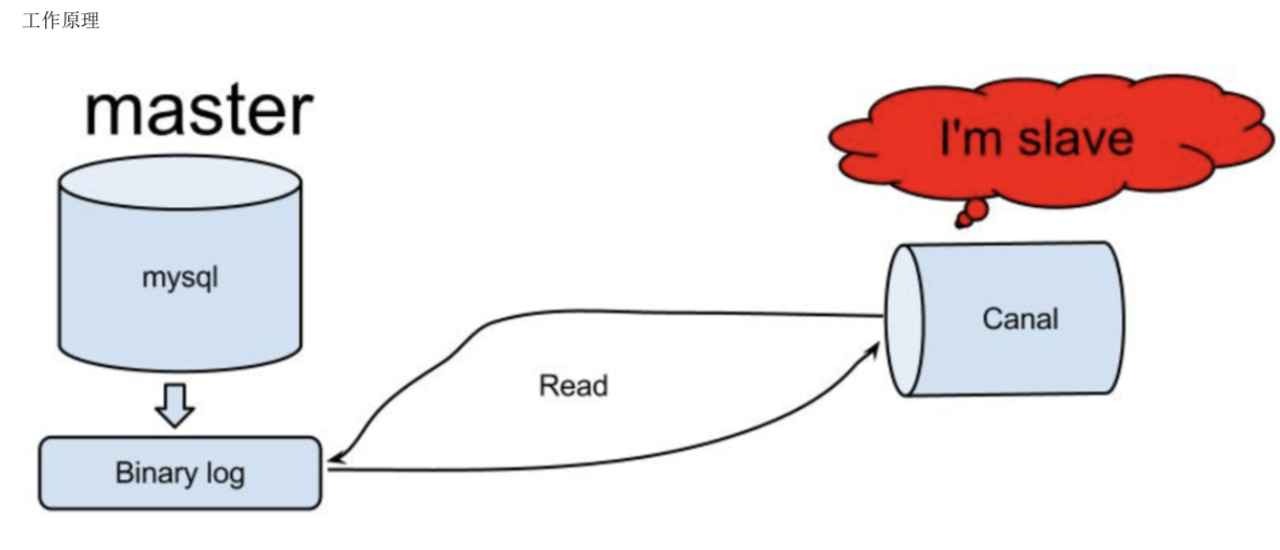
原理相对比较简单:
1、canal 模拟 mysql slave 的交互协议,伪装自己为 mysql slave,向 mysql master 发送 dump 协议
2、mysql master 收到 dump 请求,开始推送 binary log 给 slave(也就是 canal) 3、canal 解析 binary log 对象(原始为 byte 流)
使用 canal 解析 binlog,数据落地到 kafka
(1):解压安装包:canal.deployer-1.0.23.tar.gz
tar -zxvf canal.deployer-1.0.23.tar.gz -C /export/servers/canal 修改配置文件:
vim /export/servers/canal/conf/example/instance.properties

(2):编写 canal 代码
仅仅安装了 canal 是不够的;canal 从架构的意义上来说相当于 mysql 的“从库”,此时还并不能将 binlog 解析出来实时转发到 kafka 上,因此需 要进一步开发 canal 代码;
Canal 已经帮我们提供了示例代码,只需要根据需求稍微更改即可;
Canal 提供的代码:
上面的代码中可以解析出 binlog 日志,但是没有将数据落地到 kafka 的代码逻辑,所以我们还需要添加将数据落地 kafka 的代码; Maven 导入依赖:
<groupId>com.alibaba.otter</groupId> <artifactId>canal.client</artifactId>
<version>1.0.23</version>
</dependency> <!-- https://mvnrepository.com/artifact/org.apache.kafka/kafka -->
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka_2.11</artifactId>
<version>0.9.0.1</version>
</dependency>
测试 canal 代码
1、 启动 kafka 并创建 topic
/export/servers/kafka/bin/kafka-server-start.sh /export/servers/kafka/config/server.properties >/dev/null 2>&1 & /export/servers/kafka/bin/kafka-topics.sh --create --zookeeper hadoop01:2181 --replication-factor 1 --partitions 1 --topic mycanal
2、 启动 mysql 的消费者客户端,观察 canal 是否解析 binlog
/export/servers/kafka/bin/kafka-console-consumer.sh --zookeeper hadoop01:2181 --from-beginning --topic mycanal 2、启动 mysql:service mysqld start
3、启动 canal:canal/bin/startup.sh
4、进入 mysql:mysql -u 用户 -p 密码;然后进行增删改
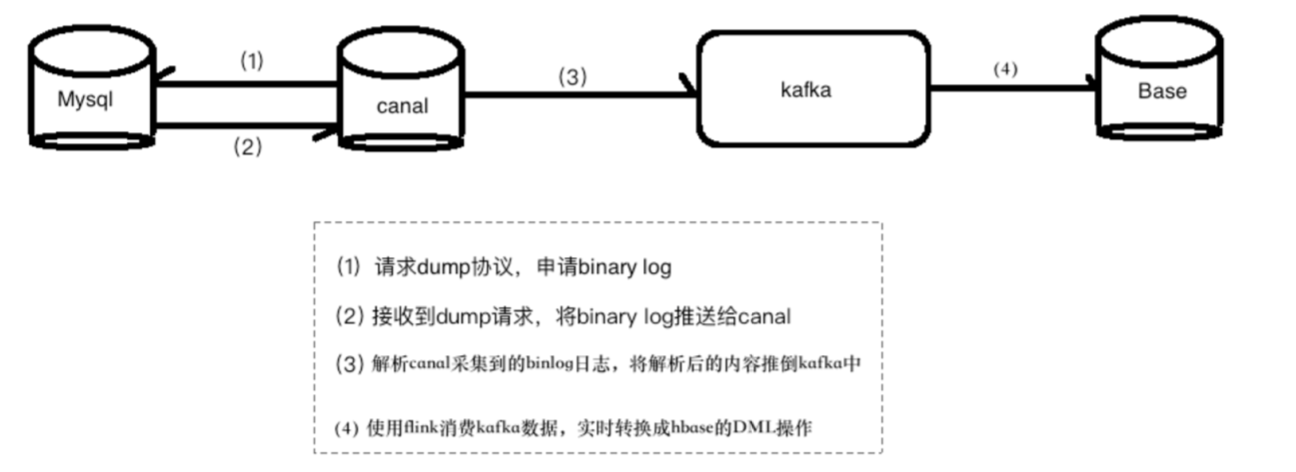
使用 flink 将 kafka 中的数据解析成 Hbase 的 DML 操作
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<zookeeper.version>3.4.5</zookeeper.version>
<scala.version>2.11.5</scala.version>
<hadoop.version>2.6.1</hadoop.version>
<flink.version>1.5.0</flink.version>
</properties> <dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>${scala.version}</version>
</dependency> <dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-scala_2.11</artifactId>
<version>${flink.version}</version>
</dependency> <dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-scala_2.11</artifactId>
<version>${flink.version}</version>
</dependency> <dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients_2.11</artifactId>
<version>${flink.version}</version>
</dependency> <dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table_2.11</artifactId>
<version>${flink.version}</version>
</dependency> <dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>${hadoop.version}</version>
<exclusions>
<exclusion>
<groupId>com.google.protobuf</groupId>
<artifactId>protobuf-java</artifactId>
</exclusion>
</exclusions>
</dependency> <dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka-0.9_2.11</artifactId>
<version>${flink.version}</version>
</dependency> <dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-hbase_2.11</artifactId>
<version>${flink.version}</version>
</dependency>
代码:
import java.util
import java.util.Properties
import org.apache.commons.lang3.StringUtils
import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer09
import org.apache.flink.streaming.util.serialization.SimpleStringSchema
import org.apache.flink.api.scala._
import org.apache.flink.runtime.state.filesystem.FsStateBackend
import org.apache.flink.streaming.api.{CheckpointingMode, TimeCharacteristic}
import org.apache.hadoop.hbase.{HBaseConfiguration, HColumnDescriptor, HTableDescriptor, TableName}
import org.apache.hadoop.hbase.client.{ConnectionFactory, Delete, Put}
import org.apache.hadoop.hbase.util.Bytes /**
* Created by angel;
*/
//[uname, spark, true], [upassword, 11122221, true]
case class UpdateFields(key:String , value:String) //(fileName , fileOffset , dbName , tableName ,eventType, columns , rowNum)
case class Canal(fileName:String ,
fileOffset:String,
dbName:String ,
tableName:String ,
eventType:String ,
columns:String ,
rowNum:String
)
object DataExtraction {
//1指定相关信息
val zkCluster = "hadoop01,hadoop02,hadoop03"
val kafkaCluster = "hadoop01:9092,hadoop02:9092,hadoop03:9092"
val kafkaTopicName = "canal"
val hbasePort = "2181"
val tableName:TableName = TableName.valueOf("canal")
val columnFamily = "info" def main(args: Array[String]): Unit = {
//2.创建流处理环境
val env = StreamExecutionEnvironment.getExecutionEnvironment
env.setStateBackend(new FsStateBackend("hdfs://hadoop01:9000/flink-checkpoint/checkpoint/"))
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime)
env.getConfig.setAutoWatermarkInterval(2000)//定期发送
env.getCheckpointConfig.setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE)
env.getCheckpointConfig.setCheckpointInterval(6000)
System.setProperty("hadoop.home.dir", "/");
//3.创建kafka数据流
val properties = new Properties()
properties.setProperty("bootstrap.servers", kafkaCluster)
properties.setProperty("zookeeper.connect", zkCluster)
properties.setProperty("group.id", kafkaTopicName)
val kafka09 = new FlinkKafkaConsumer09[String](kafkaTopicName, new SimpleStringSchema(), properties)
//4.添加数据源addSource(kafka09)
val text = env.addSource(kafka09).setParallelism(1)
//5、解析kafka数据流,封装成canal对象
val values = text.map{
line =>
val values = line.split("#CS#")
val valuesLength = values.length
//
val fileName = if(valuesLength > 0) values(0) else ""
val fileOffset = if(valuesLength > 1) values(1) else ""
val dbName = if(valuesLength > 2) values(2) else ""
val tableName = if(valuesLength > 3) values(3) else ""
val eventType = if(valuesLength > 4) values(4) else ""
val columns = if(valuesLength > 5) values(5) else ""
val rowNum = if(valuesLength > 6) values(6) else ""
//(mysql-bin.000001,7470,test,users,[uid, 18, true, uname, spark, true, upassword, 1111, true],null,1)
Canal(fileName , fileOffset , dbName , tableName ,eventType, columns , rowNum)
} //6、将数据落地到Hbase
val list_columns_ = values.map{
line =>
//处理columns字符串
val strColumns = line.columns
println(s"strColumns --------> ${strColumns}")
//[[uid, 22, true], [uname, spark, true], [upassword, 1111, true]]
val array_columns = packaging_str_list(strColumns)
//获取主键
val primaryKey = getPrimaryKey(array_columns)
//拼接rowkey DB+tableName+primaryKey
val rowkey = line.dbName+"_"+line.tableName+"_"+primaryKey
//获取操作类型INSERT UPDATE DELETE
val eventType = line.eventType
//获取触发的列:inser update val triggerFileds: util.ArrayList[UpdateFields] = getTriggerColumns(array_columns , eventType)
// //因为不同表直接有关联,肯定是有重合的列,所以hbase表=line.dbName + line.tableName
// val hbase_table = line.dbName + line.tableName
//根据rowkey删除数据
if(eventType.equals("DELETE")){
operatorDeleteHbase(rowkey , eventType)
}else{
if(triggerFileds.size() > 0){
operatorHbase(rowkey , eventType , triggerFileds)
} }
}
env.execute() } //封装字符串列表
def packaging_str_list(str_list:String):String ={
val substring = str_list.substring(1 , str_list.length-1) substring
} //获取每个表的主键
def getPrimaryKey(columns :String):String = {
// [uid, 1, false], [uname, abc, false], [upassword, uabc, false]
val arrays: Array[String] = StringUtils.substringsBetween(columns , "[" , "]")
val primaryStr: String = arrays(0)//uid, 13, true
primaryStr.split(",")(1).trim
} //获取触发更改的列
def getTriggerColumns(columns :String , eventType:String): util.ArrayList[UpdateFields] ={
val arrays: Array[String] = StringUtils.substringsBetween(columns , "[" , "]")
val list = new util.ArrayList[UpdateFields]()
eventType match {
case "UPDATE" =>
for(index <- 1 to arrays.length-1){
val split: Array[String] = arrays(index).split(",")
if(split(2).trim.toBoolean == true){
list.add(UpdateFields(split(0) , split(1)))
}
}
list
case "INSERT" =>
for(index <- 1 to arrays.length-1){
val split: Array[String] = arrays(index).split(",")
list.add(UpdateFields(split(0) , split(1)))
}
list
case _ =>
list }
}
//增改操作
def operatorHbase(rowkey:String , eventType:String , triggerFileds:util.ArrayList[UpdateFields]): Unit ={
val config = HBaseConfiguration.create();
config.set("hbase.zookeeper.quorum", zkCluster);
config.set("hbase.master", "hadoop01:60000");
config.set("hbase.zookeeper.property.clientPort", hbasePort);
config.setInt("hbase.rpc.timeout", 20000);
config.setInt("hbase.client.operation.timeout", 30000);
config.setInt("hbase.client.scanner.timeout.period", 200000);
val connect = ConnectionFactory.createConnection(config);
val admin = connect.getAdmin
//构造表描述器
val hTableDescriptor = new HTableDescriptor(tableName)
//构造列族描述器
val hColumnDescriptor = new HColumnDescriptor(columnFamily)
hTableDescriptor.addFamily(hColumnDescriptor)
if(!admin.tableExists(tableName)){
admin.createTable(hTableDescriptor);
}
//如果表存在,则开始插入数据
val table = connect.getTable(tableName)
val put = new Put(Bytes.toBytes(rowkey))
//获取对应的列[UpdateFields(uname, spark), UpdateFields(upassword, 1111)]
for(index <- 0 to triggerFileds.size()-1){
val fields = triggerFileds.get(index)
val key = fields.key
val value = fields.value
put.addColumn(Bytes.toBytes(columnFamily) , Bytes.toBytes(key) , Bytes.toBytes(value))
}
table.put(put)
}
//删除操作
def operatorDeleteHbase(rowkey:String , eventType:String): Unit ={
val config = HBaseConfiguration.create();
config.set("hbase.zookeeper.quorum", zkCluster);
config.set("hbase.zookeeper.property.clientPort", hbasePort);
config.setInt("hbase.rpc.timeout", 20000);
config.setInt("hbase.client.operation.timeout", 30000);
config.setInt("hbase.client.scanner.timeout.period", 200000);
val connect = ConnectionFactory.createConnection(config);
val admin = connect.getAdmin
//构造表描述器
val hTableDescriptor = new HTableDescriptor(tableName)
//构造列族描述器
val hColumnDescriptor = new HColumnDescriptor(columnFamily)
hTableDescriptor.addFamily(hColumnDescriptor)
if(admin.tableExists(tableName)){
val table = connect.getTable(tableName)
val delete = new Delete(Bytes.toBytes(rowkey))
table.delete(delete)
}
} }
打包scala程序
将上述的maven依赖红色标记处修改成:
<**sourceDirectory**>**src/main/scala**</**sourceDirectory**> <**mainClass**>scala的驱动类</**mainClass**>
运行canal代码
java -jar canal.jar -Xms100m -Xmx100m
运行flink代码
/opt/cdh/flink-1.5.0/bin/flink run -m yarn-cluster -yn 2 -p 1 /home/elasticsearch/flinkjar/SynDB-1.0-SNAPSHOT.jar
最新文章
- 立即执行函数表达式(IIFE)
- ASP.NET MVC5+EF6+EasyUI 后台管理系统(27)-权限管理系统-分配用户给角色
- H5 Notes:PostMessage Cross-Origin Communication
- dataTables获取当前行json格式数据
- 比Ansible更吊的自动化运维工具,自动化统一安装部署_自动化部署udeploy 1.0
- Ganglia安装扩容
- IoC实践--用Autofac实现MVC5.0的IoC控制反转方法
- 【BZOJ】1089: [SCOI2003]严格n元树(递推+高精度/fft)
- gcj_2016_Round1_B
- Codeforces 424 B Megacity【贪心】
- QUrl不同版本之间的坑
- IE下常见的js兼容问题
- java基础(七)-----深入剖析Java中的装箱和拆箱
- 关于ajax 进行post提交 json数据到controller
- 如何理解JavaScript中的原型和原型链
- silverlight属性改变事件通知
- 【刷题】BZOJ 1413 [ZJOI2009]取石子游戏
- nuxt.js实战之开发环境配置
- Luogu P4009 汽车加油行驶问题
- UE4联机编译光照