【Python】Python重新学习
<python基础教程(第二版)>
http://www.cnblogs.com/fnng/category/454439.html
- 分片(后面取的是前一位)
eg:
>>> numbers = [0,1,2,3,4,5,6,7,8,9]
>>> numbers[7:-1]
===================================
- tuple函数的功能与list函数基本上一样:以一个序列作为参数并把它转换为元组。
[] --> 列表
()--> 元组
===================================
- join 方法是非常重要的字符串方法,它是split方法的逆方法,用来在队列中添加元素:
dict函数
可以用dict 函数,通过其他映射(比如其他字典)或(键,值)这样的序列对建立字典。
eg:
>>> items = [('name','gumby'),('age',42)]
>>> d = dict(items)
>>> d
{'age': 42, 'name': 'gumby'}
>>> d['name']
'gumby'
===================================
- >>> import math as foobar #为整个模块提供别名 >>> foobar.sqrt(4) 2.0 >>> from math import sqrt as foobar #为函数提供别名 >>> foobar(4) 2.0
- 可以获取或删除字典中任意的键-值对,可以使用popitem方法(每次pop一对出来)
>>> scoundrel ={'name':'robin','girlfriend':'marion'}
>>> key,value = scoundrel.popitem()
>>> key
'name'
>>> value
'robin'
- elif 子句,它是“else if”的简写
- input 用户数字输入,raw_input用户文字等输入。
>>> x += 1 #(x=x+1)
>>> x *= 2 #(x=x*2)- key表示名称,d[key]表示该名称对应的值
d = {'x':1,'y':2,'z':3}
for key in d:
print key,'corresponds to',d[key]
#输出
>>>
y corresponds to 2
x corresponds to 1
z corresponds to 3
- break 用来结束循环,假设找100以内最大平方数,那么程序可以从100往下迭代到0,步长为-1
from math import sqrt
for n in range(99,0,-1):
root = sqrt(n)
if root == int(root):
print n
break
#输出
>>>
81
==========================================================================================
- 局部变量 当函数定义生命变量的时候,函数内所生命的变理只在其函数内有效,与函数外具有相同名称的其他变量没有任何关系
默认参数 对于一些参数,我们希望它的一些参数是可选的,如果用户不想要为这些参数提供值的话,这些参数就使用默认值。
- 注意:只有在形参表末尾的那些参数可以有默认参数,如def func(a=5,b) 是无效的。
def say(message,times=1):
print message*times say('Hello')
say('World',5)
#输出
>>>
Hello
WorldWorldWorldWorldWorld
- 关键参数 如果某个函数有许多参数,而我们只想指定其中的一部分,那么可以使用名字(关键字)而不是位置来给函数指定实参。----这被称作 关键参数
def func(a,b=5,c=10):
print 'a is',a, 'and b is',b,'and c is',c func(3,7)
func(24,c=32)
func(c=23,a=14)
- 有用的递归函数包含以下几个部分:
- 当函数直接返回值时有基本实例(最小可能性问题)
- 递归实例,包括一个或者多个问题最小部分的递归调用。
=======================================================
- 多态意思是“有多种形式”。多态意味着就算不知道变量所引用的对象类是什么,还是能对它进行操作,而它也会根据对象(或类)类型的不同而表现出不同的行为。
>>> def add(x,y):
return x+y >>> add(1,2)
3
>>> add('hello.','world')
'hello.world'
- len函数用于计算长度,repr用于放置函数的内容;repr函数是多态特性的代表之一---可以对任何东西使用。
>>> def length_message(x):
print"The length of " , repr(x),"is",len(x)
>>> length_message('chongshi')
The length of 'chongshi' is 8
- 如果想要查看一个类是否是另一个的子类。可以使用内建的issubclass函数:issubclass(子类名, 父类名)
==================================================================
- Python常用的内建异常类:

- 我们可以使用 try/except 来实现异常的捕捉处理。
try:
x = input('Enter the first number: ')
y = input('Enter the second number: ')
print x/y
except ZeroDivisionError:
print "输入的数字不能为0!"
- 假如,我们在调试的时候引发异常会好些,如果在与用户的进行交互的过程中又是不希望用户看到异常信息的。那如何开启/关闭 “屏蔽”机制?
class MuffledCalulator:
muffled = False #这里默认关闭屏蔽
def calc(self,expr):
try:
return eval(expr)
except ZeroDivisionError:
if self.muffled:
print 'Divsion by zero is illagal'
else:
raise #运行程序:
>>> calculator = MuffledCalulator()
>>> calculator.calc('10/2')
5
>>> calculator.clac('10/0') Traceback (most recent call last):
File "<pyshell#30>", line 1, in <module>
calculator.clac('10/0')
AttributeError: MuffledCalulator instance has no attribute 'clac' #异常信息被输出了 >>> calculator.muffled = True #现在打开屏蔽
>>> calculator.calc('10/0')
Divsion by zero is illagal
- 多个except 子句
try:
x = input('Enter the first number: ')
y = input('Enter the second number: ')
print x/y
except ZeroDivisionError:
print "输入的数字不能为0!"
except TypeError: # 对字符的异常处理
print "请输入数字!"
- 一个块捕捉多个异常
try:
x = input('Enter the first number: ')
y = input('Enter the second number: ')
print x/y
except (ZeroDivisionError,TypeError,NameError):
print "你的数字不对!" - 捕捉全部异常
try:
x = input('Enter the first number: ')
y = input('Enter the second number: ')
print x/y
except:
print '有错误发生了!'
====================================
- 为了确保类是新型类,应该把 _metaclass_=type 入到你的模块的最开始。
构造方法
构造方法与其的方法不一样,当一个对象被创建会立即调用构造方法。创建一个python的构造方法很简答,只要把init方法,从简单的init方法,转换成魔法版本的_init_方法就可以了。
class FooBar:
def __init__(self):
self.somevar = 42 >>> f =FooBar()
>>> f.somevar
42
- 重写是继承机制中的一个重要内容,对一于构造方法尤其重要。
调用未绑定的超类构造方法

使用super函数
super函数只能在新式类中使用。当前类和对象可以作为super函数的参数使用,调用函数返回的对象的任何方法都是调用超类的方法,而不是当前类的方法。那就可以不同在SongBird的构造方法中使用Bird,而直接使用super(SongBird,self)。
... super(SongBird,self).__init__() ...
- 属性
def __init__(self):
self.width = 0
self.height = 0 - property 函数(根据调用的格式,去调用对应的函数)

=========================================================
迭代器(无限循环)
- 迭代器规则
迭代的意思是重复做一些事很多次---就像在循环中做的那样。__iter__ 方法返回一个迭代器,所谓迭代器就是具有next方法的对象,在调用next方法时,迭代器会返回它的下一个值。如果next方法被调用,但迭代器没有值可以返回,就会引发一个StopIteration异常。
class Fibs:
def __init__(self):
self.a = 0
self.b = 1
def next(self):
self.a , self.b = self.b , self.a + self.b
return self.a
def __iter__(self):
return self >>> fibs = Fibs()
>>> for f in fibs:
if f > 1000:
print f
break #因为设置了break ,所以循环在这里停止。 1597
- 从迭代器得到序列
class TestIterator:
value = 0
def next(self):
self.value += 1
if self.value > 10: raise StopIteration
return self.value
def __iter__(self):
return self >>> ti = TestIterator()
>>> list(ti)
[1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
- 生成器
生成器也叫 简单生成器,生成器可以帮助读者写出非常优雅的代码,当然,编写任何程序时不使用生成器也是可以的。
>>> def flatten(nested):
for sublist in nested:
for element in sublist:
yield element >>> nested = [[1,2],[3,4],[5]]
#使用for循环
>>> for num in flatten(nested):
print num 1
2
3
4
5
- 生成器方法
生成器新属性是在开始运行后为生成器提供值的能力。表现为生成器和“外部世界”进行交流的渠道:
* 外部作用域访问生成器的send方法,就像访问next 方法一样,只不过前者使用一个参数(发送的“消息”---任意对象)
* 在内部则挂起生成器,yield现在作为表达式而不是语句使用,换句话说,当生成器重新运行的时候,yield方法返回一个值,也就是外部通过send方法发送的值。如果next 方法被使用,那么yield方法返回None.
下面简单的方例子来说明这种机制:
def repeater(value):
while True:
new =(yield value)
if new is not None:value = new >>> r = repeater(42)
>>> r.next()
42
>>> r.send("hello, world!")
'hello, world!'
生成器的另两个方法:
* throw方法(使用异常类型调用,还有可选的值以及回溯对象)用于在生成器内引发一个异常(在yield表达式中)
* close 方法(调用时不用参数)用于停止生成器。
- 模块
>>> import sys
>>> sys.path.append('c:/python')
>>> import hello
hello,world!
- f __name__ == '__nain__' 解释:
python文件的后缀为.py ,.py文件可以用来直接运行,就像一个独立的小程序;也可以用来作为模块被其它程序调用。
__name__是模块的内置属性,如果等于'__main__' 侧表示直接被使用,那么将执行方法test()方法;如果是被调用则不执行 if 判断后面的test()方法。
- 时间模块
time.asctime()
'Thu May 16 00:00:08 2013'
- random模块
random模块包括返回随机的函数,可以用于模拟或者用于任何产生随机输出的程序。
random模块中的一些重要函数:

- 正则表达式
** 通配符
正则表达式可以匹配多于一个的字符串,你可以使用一些特殊字符创建这类模式。比如点号(.)可以匹配任何字符。在我们用window 搜索时用问号(?)匹配任意一位字符,作用是一样的。那么这类符号就叫 通配符。
** 对特殊字符进行转义
使用“python\\.org”,这样就只会匹配“python.org”了
** 字符集
我们可以使用中括号([ ])括住字符串来创建字符集。可以使用范围,比如‘[a-z]’能够匹配a到z的任意一个字符,还可以通过一个接一个的方式将范围联合起来使用,比如‘[a-zA-Z0-9]’能够匹配任意大小写字母和数字。
反转字符集,可以在开头使用^字符,比如‘[^abc]’可以匹配任何除了a、b、c之外的字符。
** 选择符
有时候只想匹配字符串’python’ 和 ’perl’ ,可以使用选择项的特殊字符:管道符号(|) 。因此, 所需模式可以写成’python|perl’ 。
** 子模式(加括号)
但是,有些时候不需要对整个模式使用选择符---只是模式的一部分。这时可以使用圆括号起需要的部分,或称子模式。 前例可以写成 ‘p(ython | erl)’
** 可选项
在子模式后面加上问号,它就变成了可选项。它可能出现在匹配字符串,但并非必须的。
** 重复子模式
(pattern)* : 允许模式重复0次或多次
(pattern)+ : 允许模式重复1次或多次
(pattern){m,n} : 允许模式重复m~ n 次
- re模块的内容
re模块中一些重要的函数:
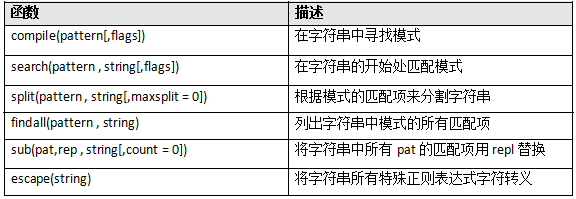
re.split 会根据模式的匹配项来分割字符串。
re. findall以列表形式返回给定模式的所有匹配项。
re.sub的作用在于:使用给定的替换内容将匹配模式的子符串(最左端并且重叠子字符串)替换掉。
re.escape 函数,可以对字符串中所有可能被解释为正则运算符的字符进行转义的应用函数。如果字符串很长且包含很多特殊字符,而你又不想输入一大堆反斜线,可以使用这个函数。
- 匹配对象和组
简单来说,组就是放置在圆括号里内的子模块,组的序号取决于它左侧的括号数。
re 匹配对象的重要方法

=========================================================
- 打开文件
open函数中模式参数的常用值

- f.readline()
readline返回一行的字符串, readlines返回包含文件所有内容的字符串列表, 每个元素是一行的字符串。
pprint 模块的pprint方法将内容分成每个小项单行显示。
- 更改某行内容
>>> f = open(r'I:\python\test.txt')
>>> lines = f.readlines()
>>> lines[1] = "isn't a\n"
>>> f = open(r'I:\python\test.txt','w')
>>> f.writelines(lines)
>>> f.close() - 对文件内容进行迭代
>>> first,second,third = open(r'I:\python\test.txt')
>>> first
'First line\n'
>>> second
'Second line\n'
>>> third
'Third line\n'
===========================================================================================================
图形用户界面
- 创建并显示一个框架
import wx # 需要导入wx模块
app = wx.App()
win = wx.Frame(None)
win.Show()
app.MainLoop()
- 添加事件处理(在GUI术语中,用户执行的动作(比如 点击按钮)叫做事件。我们需要让程序注意这些事件并且作出反应。)
假设写了一个负责打开文件的函数,并将其命令为load ,然后就可以像下面这样将函数作为loadButton的事件处理函数:
loadButton.Bind(wx.EVT_BUTTON,load)
================================================================
- 多线程Thread
什么是进程?
计算机程序只不过是磁盘中可执行的,二进制(或其它类型)的数据。它们只有在被读取到内存中,被操作系统调用的时候才开始它们的生命期。进程(有时被称为重量级进程)是程序的一次执行。每个进程都有自己的地址空间,内存,数据栈以及其它记录其运行轨迹的辅助数据。操作系统管理在其上运行的所有进程,并为这些进程公平地分配时间。
什么是线程?
线程(有时被称为轻量级进程)跟进程有些相似,不同的是,所有的线程运行在同一个进程中,共享相同的运行环境。我们可以想像成是在主进程或“主线程”中并行运行的“迷你进程”。
- Python通过两个标准库thread和threading提供对线程的支持。thread提供了低级别的、原始的线程以及一个简单的锁。threading基于Java的线程模型设计。锁(Lock)和条件变量(Condition)在Java中是对象的基本行为(每一个对象都自带了锁和条件变量),而在Python中则是独立的对象。
thread模块
- start_new_thread()要求一定要有前两个参数。所以,就算我们想要运行的函数不要参数,我们也要传一个空的元组。
thread.allocate_lock()
返回一个新的锁定对象。
acquire() /release()
一个原始的锁有两种状态,锁定与解锁,分别对应acquire()和release() 方法。
thread.start_new_thread(loop0, ())
#coding=utf-8
import thread
from time import sleep, ctime loops = [4,2] def loop(nloop, nsec, lock):
print 'start loop', nloop, 'at:', ctime()
sleep(nsec)
print 'loop', nloop, 'done at:', ctime()
#解锁
lock.release() def main():
print 'starting at:', ctime()
locks =[]
#以loops数组创建列表,并赋值给nloops
nloops = range(len(loops)) for i in nloops:
lock = thread.allocate_lock()
#锁定
lock.acquire()
#追加到locks[]数组中
locks.append(lock) #执行多线程
for i in nloops:
thread.start_new_thread(loop,(i,loops[i],locks[i])) for i in nloops:
while locks[i].locked():
pass print 'all end:', ctime() if __name__ == '__main__':
main()
__init__()
方法在类的一个对象被建立时运行。这个方法可以用来对你的对象做一些初始化。
apply()
apply(func [, args [, kwargs ]]) 函数用于当函数参数已经存在于一个元组或字典中时,间接地调用函数。args是一个包含将要提供给函数的按位置传递的参数的元组。如果省略了args,任何参数都不会被传递,kwargs是一个包含关键字参数的字典。
apply() 用法:
#不带参数的方法
>>> def say():
print 'say in' >>> apply(say)
say in #函数只带元组的参数
>>> def say(a,b):
print a,b >>> apply(say,('hello','虫师'))
hello 虫师 #函数带关键字参数
>>> def say(a=1,b=2):
print a,b >>> def haha(**kw):
apply(say,(),kw) >>> haha(a='a',b='b')
a b
===================================
- Urllib 模块提供了读取web页面数据的接口,我们可以像读取本地文件一样读取www和ftp上的数据
re.compile() 可以把正则表达式编译成一个正则表达式对象.
re.findall() 方法读取html 中包含 imgre(正则表达式)的数据。
- urllib.urlretrieve()方法,直接将远程数据下载到本地。
#coding=utf-8
import urllib
import re def getHtml(url):
page = urllib.urlopen(url)
html = page.read()
return html def getImg(html):
reg = r'src="(.+?\.jpg)" pic_ext'
imgre = re.compile(reg)
imglist = re.findall(imgre,html)
x = 0
for imgurl in imglist:
urllib.urlretrieve(imgurl,'%s.jpg' % x)
x+=1 html = getHtml("http://tieba.baidu.com/p/2460150866") print getImg(html)
=================================================
什么是xml?
xml即可扩展标记语言,它可以用来标记数据、定义数据类型,是一种允许用户对自己的标记语言进行定义的源语言。
从结构上,它很像我们常见的HTML超文本标记语言。但他们被设计的目的是不同的,超文本标记语言被设计用来显示数据,其焦点是数据的外观。它被设计用来传输和存储数据,其焦点是数据的内容。
- 首先,它是有标签对组成,<aa></aa>
- 标签可以有属性:<aa id=’123’></aa>
- 标签对可以嵌入数据:<aa>abc</aa>
- 标签可以嵌入子标签(具有层级关系):
<aa>
<bb></bb>
</aa>
最新文章
- Microsoft Visual Studio 2013 — Project搭载IIS配置的那些事
- MySQL查询分析器EXPLAIN或DESC
- canvas知识点
- create()创建的控件不能映射消息函数的解决
- django 2
- 最新版Intel HD4000 桌面右键菜单去除方法
- 越狱Season 1-Episode 11: And Then There Were 7-M
- Bootstrap: 样式CSS:carousel轮换 图片的使用
- [转] Android LocalService与RemoteService理解
- HDU 5869 Different GCD Subarray Query
- videojs双击全屏幕观看,videojs动态加载视频
- 新概念英语(1-105)Full Of Mistakes
- Boyer-Moore算法
- 配置 RIPv1 和 RIPv2
- [R]统计工具包
- CentOS 7关闭图形桌面开启文本界面
- python的接口
- img 边距的问题
- 【NLP】主题识别文档
- block高级功能