ItemCF_基于物品的协同过滤
2024-08-25 21:39:11
ItemCF_基于物品的协同过滤
1. 概念

2. 原理
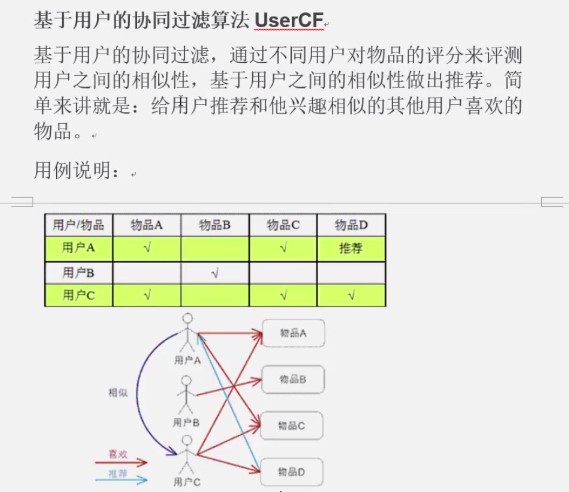
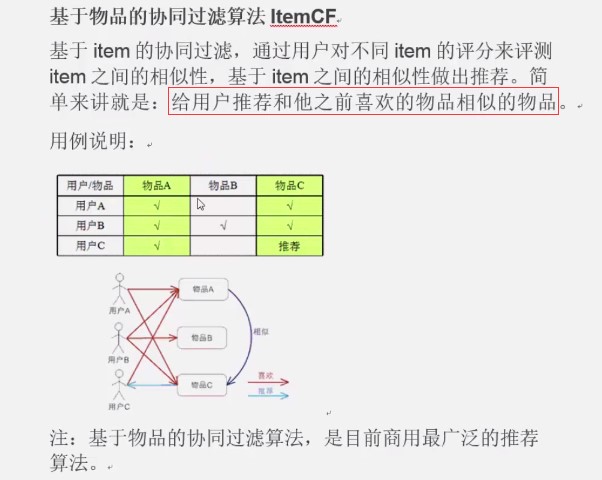

如何给用户推荐?
给用户推荐他没有买过的物品--103
3. java代码实现思路
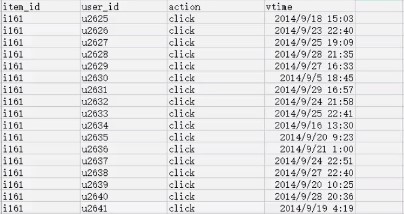
数据集:
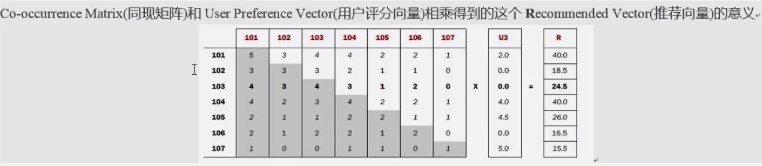
第一步:构建物品的同现矩阵
第二步:构建用户的得分矩阵
第三步:同现矩阵*评分矩阵
第四步:拿到最终结果,排序,得到给用户的推荐列表
问题一:物品同现矩阵和用户得分矩阵如何构建?
问题二:矩阵相乘如何来做?
六个MapReduce
step1_第一个MapReduce: 目的-->去重去除数据集中重复的数据
第一个MapReduce最终运行的结果:
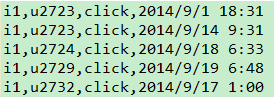
Mapper端:key:LongWritable(偏移量) value:一行数据
步骤一:context.write(value, NullWritable.get());
Reducer端:key:一行数据 value:NullWritable
步骤一:context.write(key, NullWritable.get());
step2_第二个MapReduce:目的-->按用户分组,计算所有物品出现的组合列表,得到用户对物品的喜爱度得分矩阵
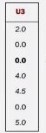
第二个MapReduce最终运行的结果:
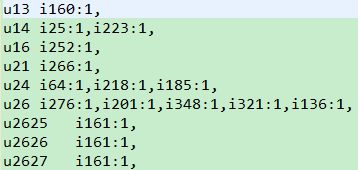
Mapper端:key:LongWritable(偏移量) value:i1,u2723,click,2014/9/14 9:31 || i1,u2723,pay,2014/9/14 9:31
步骤一:按照“,”切割,得到item(i1), user(u2723), action(click)
步骤二:构建输出的key和value(key:user, value:item:物品的得分【根据用户action得到】)
步骤三:输出key,value
Reducer端:key:user(u2723) value:{i1:1, i1:2, i3:2}
步骤一:遍历{i1:1, i1:2, i3:2},对于迭代器中的每一个Text(i1:1),按照“:”切割,分别得到item(i1)和action(1),对同一物品的action进行累加,将结果存储到map对象中(map.put(item, action))
步骤二:构建StringBuffer,key:user(u2723),value:{i1:3, i2:4, i3:5}, 并输出
step3_第三个MapReduce:目的-->对物品组合列表进行计数,建立物品的同现矩阵
第三个MapReduce最终运行的结果:
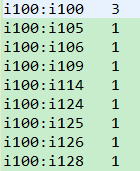
Mapper端:key:LongWritable(偏移量) value:u26 i276:1,i201:1,i348:1,i321:1,i136:1,
步骤一:切割"\t",得到tokens[1]
步骤二:双重for循环,得到每一个物品和其他物品的同现的次数
步骤三:输出,(key=itemA:itemB,value=1)这里只是得到了单用户的物品同现,在Reducer端得到的是所有用户--同一物品对其他物品的同现次数
Reducer端:第一种--key:itemA:itemB value:{1,1,1}
步骤一:对Iterable<IntWritable>遍历,统计sum,得到itemA:itemB同现的次数
step4_第四个MapReduce:目的-->把物品同现矩阵和用户得分矩阵相乘
第四个MapReduce最终运行的结果:
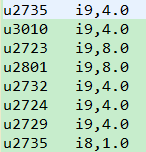
Mapper端:key:LongWritable(偏移量) value: u14 i25:1,i223:1 || i100:i105 1
步骤一:因为Mapper读取了第二次输出(用户得分矩阵)和第三次输出的结果(物品同现矩阵),所以要对maptask所对应的split进行判断,判读所读的数据集属于哪一个,这里采用了重写了setup(Context context)方法,定义了flag来进行标识
步骤二:
如果为同现矩阵(step3)// 样本: i100:i181 1
key:i100 value:A:i181,1 输出
如果为得分矩阵(step2)// 样本: u24 i64:1,i218:1,i100:2,
遍历得分矩阵--key:i100 value:B:u24,2, 输出
Reducer端:key:i100 value: {A:i181,1, A:i180,1 A:i167,3} || {B:u24,2,B:u25,3, B:u26,3}
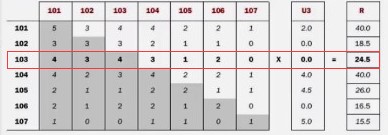
步骤一:因为value中的A:B:标识同现矩阵,得分矩阵
val.startWith("A:")
某一个物品i100,针对它和其他物品的同现次数,存在mapA-->value: {A:i181,1, A:i180,1 A:i167,3} mapA.put(i181,1),map.put(i180,1)...
val.startWith("B:")
该物品(key中的itemID),所有用户的推荐权重分数mapB--{B:u24,2,B:u25,3, B:u26,3}
mapB.put(u24,2),mapB.put(u25,3)...
步骤二:进行矩阵相乘运算,对于物品i100,它的同现商品以及对应的次数存放到了mapA,而物品对于i100,所有用户的评分已经存放到了mapB,只需要遍历mapA,将其中同现的每一个商品乘以对应的mapB中每一个用户对i100的评分
步骤三:输出,key=userId, value=itemId,result (u24 i101,8.0)
step5_第五个MapReduce:目的-->把相乘后的矩阵相加,获得结果矩阵
第五个MapReduce最终运行的结果:

Mapper端:key:LongWritable(偏移量) value:u13 i9,5.0
步骤一:key=u13,value=i9,5.0 输出
Reducer端:key:u13 value:{i101,2.0, i103,4.5, i101, 5.7}
步骤一:利用map对同一itemId矩阵求和
步骤二:输出,key=userId, value=itemId,score(样本: u13 i9,5.0)
step6_第六个MapReduce:目的-->按照推荐得分降序排序,取前十条(二次排序)
第六个MapReduce最终运行的结果:

Mapper端:key:LongWritable(偏移量) value:u13 i9,5.0
步骤一:将用户id,物品和得分封装到一个对象 PairWritable,
步骤二:输出,key:(PairWritable) value:(item:num)
Shuffle中Sort:
注意: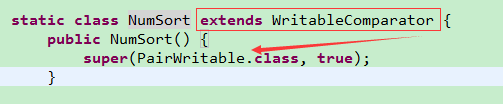
重写compare()方法,先比较Uid,相等的话,再比较Num
Shuffle中Group:
注意:
重写compare()方法,Uid相同的为一组
Reducer端:key: PairWritable value:Text{i160:58.0,i352:9.0,i192:8.0,i455:7.0...}
步骤一:取前十个,利用StringBuffer拼接
步骤二:输出,key=uid,value=sb.toString()
最新文章
- 地图中插入表格——ArcMap篇
- POJ 1014 Dividing
- ECshop 快捷登录插件 支持QQ 支付宝 微博
- Struts
- Hacker communities collection
- 我的Github之旅(一)
- [学习笔记]概率&期望
- mysql已有数据字符集转换
- 使用mysqlbinlog server远程备份binlog的脚本
- c# UDP通信 列子
- 【多媒体封装格式详解】---MP4【4】
- Linux项目一
- Android 之 自定义标签 和 自定义组件
- java.lang.NoClassDefFoundError: Could not initialize class net.sf.json.util.JSONUtils
- Jedis操作redis(转)
- Echarts折线图表断点如何补全
- 基于Vue全家桶制作的的高仿美团APP
- jfinal 源码学习
- ABP官方文档翻译 6.1.3 异常处理
- Day20 Django的使用_基础
热门文章
- Eclipse的黑色主题背景(github)
- Ubuntu系统升级内核方法
- iOS- 关于AVAudioSession的使用——后台播放音乐
- 剖析Vue原理&实现双向绑定MVVM-1
- Java容器深入浅出之String、StringBuffer、StringBuilder
- 第80天:jQuery插件使用
- 【Python】Python对象类型及其运算
- Android性能优化:布局优化 详细解析(含<include>、<ViewStub>、<merge>讲解 )
- 洛谷 P4721 【模板】分治 FFT 解题报告
- Redis的String、Hash类型命令