scrapy 开发流程
2024-10-08 14:31:56
一、Spider 开发流程
实现一个 Spider 子的过程就像是完成一系列的填空题,Scrapy 框架提出以下问题让用户在Spider 子类中作答:
1、爬虫从哪个或者那些页面开始爬取?
2、对于一个已下载的页面,提取其中的那些数据?
3、爬取完当前页面后,接下来爬取哪个或那些页面?
上面问题的答案包含了一个爬虫最重要的逻辑,回答了这些问题,一个爬虫也就开发出来了。
实现一个Spider 只需要完成下面4个步骤:
步骤 01: 继承 scrapy.Spider
import scrapy class BooksSpider(scrapy.Spider):
...
步骤 02:为 Spider 取名;
import scrapy class BooksSpider(scrapy.Spider):
name = "book"
...
步骤 03:设定起始爬取点;
class BooksSpider(scrapy.Spider):
...
start_url = ['http://books.toscrape.com/']
...
start_url 同常被实现成一个列表,其中放入所有的其实爬去点的 url (例子中只有一个其实点)。看到这里,大家可能会想,请求页面下载不是一定要提交 Request 对象么? 而我们仅定义了 url 列表,是谁暗中构造并提交了 Request 对象呢? 通过阅读 Spider 基类源码可以找到答案,相关代码如下:
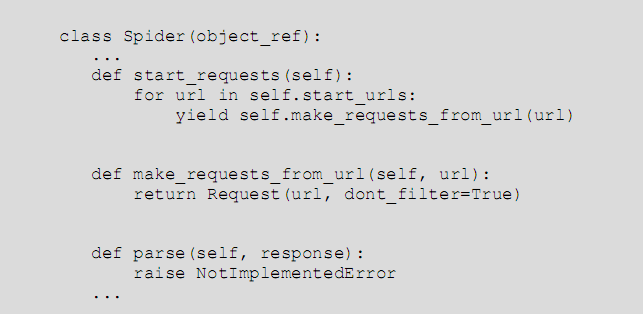
步骤 04:实现页面解析函数;
页面解析函数也就是构造 Request 对象是通过 callback 参数指定的回调函数(或默认的 parse 方法)。页面解析函数是实现 Spider 中最核心的部分,它需要完成以下两项工作:
1、使用选择器提取页面中的数据,将数据封装后 (Item 或字典)提交给 Scrapy 引擎。
2、使用选择器或 LinkExtractor 提取页面中的连接,用其构造新的Request 对象并提交给 Scrapy 引擎(下载连接页面)。
一个页面中可能包含多项数据以及多个连接,因此页面解析函数被要求返回一个可迭代对象(通常被实现成一个生成器函数),每次迭代返回一项数据(Item或字典)或一个 Request 对象。
最新文章
- Lucene系列-FieldCache
- Apache Tomcat配置
- Euler's totient function
- LightOj1074 - Extended Traffic(SPFA最短路)
- 【转】DataGridView之为每行前面添加序号
- NGUI学习笔记(四):动态加载UI和NGUI事件
- zip格式压缩、解压缩(C#)
- SpringMVC中Controller
- rm 命令详解
- C#历年来最受欢迎功能
- 第一节: Timer的定时任务的复习、Quartz.Net的入门使用、Aop思想的体现
- Prometheus部署监控容器
- centos7安装git
- Python Django install Error
- c++ 实现拓扑排序
- K8s(7)-安装Web UI
- vue router history模式开发ngnix配置
- shell+curl监控网站页面(域名访问状态),并利用sendemail发送邮件
- 18.1利用socket .io 实现 editor间代码的同步
- TClientDataSet 的Filename 和 open方法