K-MEANS算法及sklearn实现
2024-10-06 22:47:13
K-MEANS算法
聚类概念:
1.无监督问题:我们手里没有标签
2.聚类:相似的东西分到一组
3.难点:如何评估,如何调参
4.要得到簇的个数,需要指定K值
5.质心:均值,即向量各维取平均即可
6.距离的度量:常用欧几里得距离和余弦相似度
7.优化目标:min$$ min \sum_{i=0}^k \sum_{C_j=0} dist(c_i,x)^2$$
工作流程:
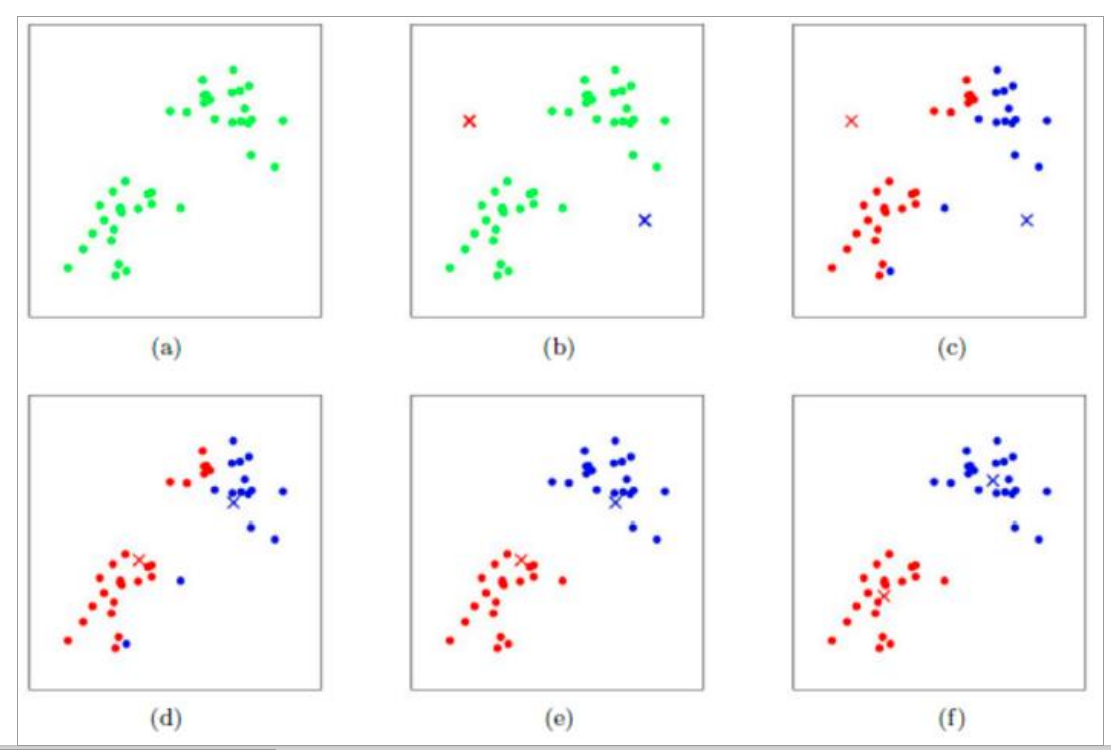
(a)读入数据
(b)随机初始化两个点
(c)计算每个点到质心的距离,离那个质心距离近,就暂时归为那类
(d)重新计算评估指标,更新质心,执行c动作
(e)重新更新质心
(f)重新计算质心的距离,进行分类,直到质心不在发生变化
优势:
简单、快速、适合常规数据集
劣势:
K值难确定
复杂度与样本呈线性关系
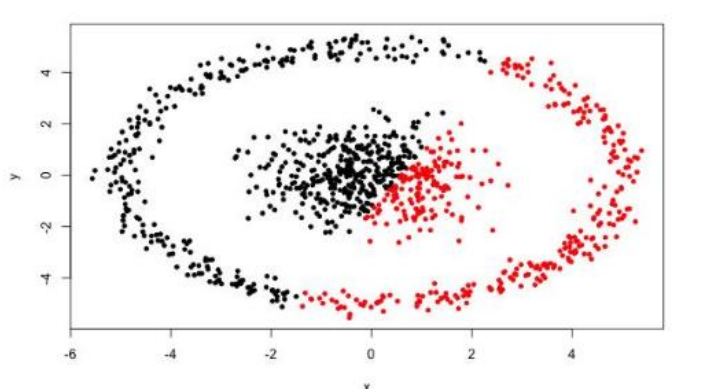
很难发现任意形状的簇,如下图:
sklearn实现
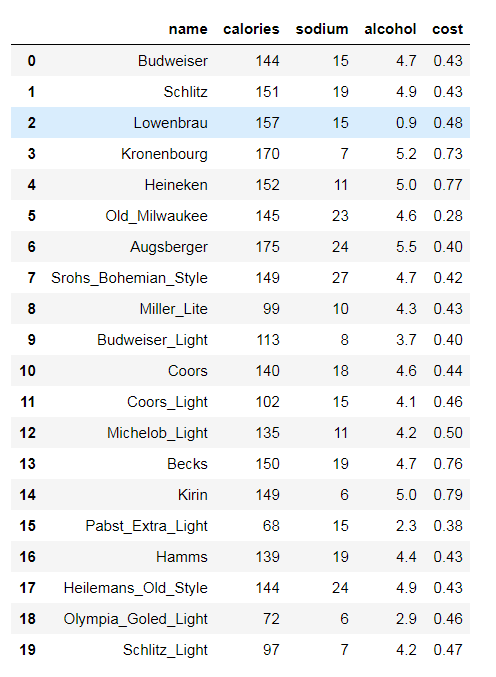
#数据读入
# beer dataset
import pandas as pd
beer = pd.read_csv('data.txt',sep=' ')
beer
X = beer[["calories","sodium","alcohol","cost"]]
from sklearn.cluster import KMeans
km = KMeans(n_clusters = 3).fit(X)
km2 = KMeans(n_clusters = 2).fit(X)
print(km.labels_)
array([0, 0, 0, 0, 0, 0, 0, 0, 2, 2, 0, 2, 0, 0, 0, 1, 0, 0, 1, 2])
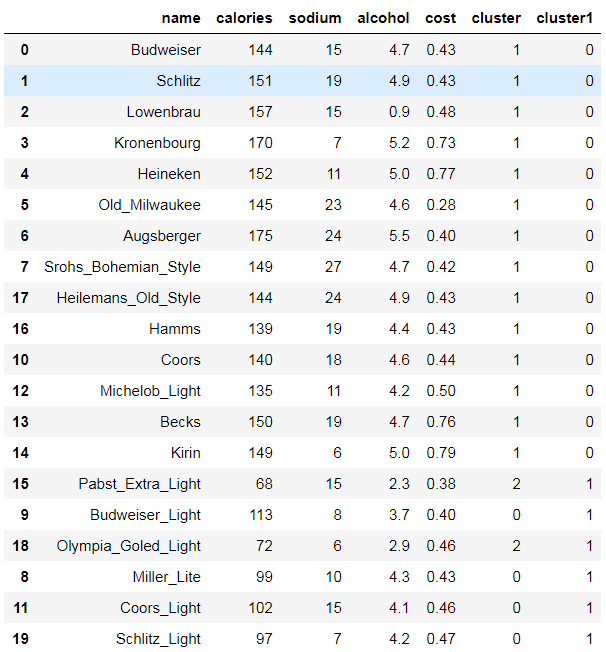
beer['cluster'] = km.labels_
beer['cluster1'] = km2.labels_
beer.sort_values('cluster')
beer.sort_values('cluster1')
最新文章
- 关于nfs共享目录的使用技巧
- 写字节流转换String 代码示例
- Trumbowyg - 轻量的 WYSIWYG 编辑器
- 关于oracle的rowid
- golang学习遭遇错误原因分析续
- 将fastjson元素转化为String[]
- COJ 1006 树上操作
- Lining Up(在一条直线上的最大点数目,暴力)
- Hadoop源代码导入Eclipse
- Ajax - 在函数中使用Ajax怎么使用返回值 - Ajax赋值给全局变量异常的解决方法
- LeetCode18:4Sum
- day3 自定义指令详解
- BZOJ_2600_[Ioi2011]ricehub_二分答案
- 包建强的培训课程(17):Java代码敏捷之道
- Nginx正反向代理、负载均衡等功能实现配置
- Codeforces 542A Place Your Ad Here
- iOS 集成极光推送
- SpringBoot 整合 Logback
- 关于在eclipse Oxygen 2017环境下spring3.2 asm的异常
- 常用MySQL函数