集合(四) Hashtable
2.Hashtable
Hashtable,顾名思义,哈希表,本来是已经被淘汰的内容,但在某一版本的Java将其实现了Map接口,因此也成为常用的集合类,但是hashtable由于和hashmap十分相似,因此据说也成为“面试经典题”。由于两者的区别网上实在太多太多,我就不自己在摸索了直接拷贝过来用于借鉴:
- HashMap可以接受为null的键值(key)和值(value),而Hashtable则不行。
- HashMap是非synchronized,而Hashtable是synchronized,这意味着Hashtable是线程安全的,多个线程可以共享一个Hashtable;而如果没有正确的同步的话,多个线程是不能共享HashMap的。Java 提供了ConcurrentHashMap,它解决了HashMap的线程不安全的问题和Hashtable效率低的问题。
- 由于Hashtable是线程安全的也是synchronized,所以在单线程环境下它比HashMap要慢。如果你不需要同步,只需要单一线程,那么使用HashMap性能要好过Hashtable。
- 还有一点,算不上区别吧,HashMap是继承实现了Map接口的虚类AbstractMap,而Hashtable继承Dictionary类,并且实现Map接口。
至于前三点可以说是最多被提及的,当然HashMap可以通过下面的语句进行同步:
Map m = Collections.synchronizeMap(hashMap);
然后我们来深入讨论一下其他的的几个区别
- 是HashMap的迭代器(Iterator)是fail-fast迭代器,而Hashtable的enumerator迭代器不仅仅是fail-fast的,还使用了Enumeration的方式。所以当有其它线程改变了HashMap的结构(增加或者移除元素),将会抛出ConcurrentModificationException,但迭代器本身的remove()方法移除元素则不会抛出ConcurrentModificationException异常。但这并不是一个一定发生的行为,要看JVM。这条同样也是Enumeration和Iterator的区别。
前面咱们已经讨论过HashMap的一些遍历方式,可以确定的是HashMap的遍历方式Hashtable都有,但是Hashtable在此基础上还有Enumeration的方式,我们直接以实例来展示:
public static void main(String [] args)
{
Hashtable ht = new Hashtable<String, Integer>();
for(int i=100;i<105;i++)
{
ht.put(String.valueOf(i)+"th",i);
}
System.out.println(ht);
Enumeration enu = ht.keys();
while(enu.hasMoreElements()) {
System.out.println(enu.nextElement());
} }
结果如下:
{102th=102, 104th=104, 101th=101, 103th=103, 100th=100}
102th
104th
101th
103th
100th
也证明Hashtable或者HashMap不是所谓的有序排列。keys()遍历Hashtable的键,同样的elements()也会遍历Hashtable的值。
为了内容的延续性我们放到后面来讲fail-fast机制。接下来还是看两个集合的区别。
- 扩容机制不同
在此之前,先看一下Hashtable的构造函数:
public Hashtable(int initialCapacity, float loadFactor) {
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal Capacity: "+
initialCapacity);
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal Load: "+loadFactor);
if (initialCapacity==0)
initialCapacity = 1;
this.loadFactor = loadFactor;
table = new Entry<?,?>[initialCapacity];
threshold = (int)Math.min(initialCapacity * loadFactor, MAX_ARRAY_SIZE + 1);
}
public Hashtable(int initialCapacity) {
this(initialCapacity, 0.75f);
}
public Hashtable() {
this(11, 0.75f);
}
public Hashtable(Map<? extends K, ? extends V> t) {
this(Math.max(2*t.size(), 11), 0.75f);
putAll(t);
}
Hashtable Construction Functions
可以看到Hashtable的默认capacity是11,而不是HashMap的16。而当参数是Map时,选择11与Map2倍的size较大的一个。而扩容的方法在rehash()方法中:
protected void rehash() {
int oldCapacity = table.length;
Entry<?,?>[] oldMap = table;
// overflow-conscious code
int newCapacity = (oldCapacity << 1) + 1;
if (newCapacity - MAX_ARRAY_SIZE > 0) {
if (oldCapacity == MAX_ARRAY_SIZE)
// Keep running with MAX_ARRAY_SIZE buckets
return;
newCapacity = MAX_ARRAY_SIZE;
}
Entry<?,?>[] newMap = new Entry<?,?>[newCapacity];
modCount++;
threshold = (int)Math.min(newCapacity * loadFactor, MAX_ARRAY_SIZE + 1);
table = newMap;
for (int i = oldCapacity ; i-- > 0 ;) {
for (Entry<K,V> old = (Entry<K,V>)oldMap[i] ; old != null ; ) {
Entry<K,V> e = old;
old = old.next;
int index = (e.hash & 0x7FFFFFFF) % newCapacity;
e.next = (Entry<K,V>)newMap[index];
newMap[index] = e;
}
}
}
rehash function
仔细分块来看:
int oldCapacity = table.length;
Entry<?,?>[] oldMap = table; // overflow-conscious code
int newCapacity = (oldCapacity << 1) + 1;
if (newCapacity - MAX_ARRAY_SIZE > 0) {
if (oldCapacity == MAX_ARRAY_SIZE)
// Keep running with MAX_ARRAY_SIZE buckets
return;
newCapacity = MAX_ARRAY_SIZE;
}
前两句是为了存储旧集合及其length(不是某个类的域,请回忆起Java最初求数组长度的方法)。接着新容量(newCapacity)等于旧容量*2+1,判断新容量是否超过最大值,如果超过的情况下判断旧容量是否等于最大值,如果旧容量已经等于最大值,那说明容量已经扩无可扩,直接返回。否则就扩到所允许的最大值。
一直使用最大值来替代常量MAX_ARRAY_SIZE是为了方便,设置这个值是为了防止out of memory,它等于Integer.MAX_VALUE - 8;
Entry<?,?>[] newMap = new Entry<?,?>[newCapacity];
modCount++;
threshold = (int)Math.min(newCapacity * loadFactor, MAX_ARRAY_SIZE + 1);
table = newMap;
Hashtable采用了直接申请一个新的数组的方法,重新计算阈值,newCapacity不是小于MAX_ARRAY_SIZE吗?为什么还要从这里面选一个较小的?事实上,loadFactor不一定小于1,可以设置大于1,因此就会出现前者大于后者的情况。
for (int i = oldCapacity ; i-- > 0 ;) {
for (Entry<K,V> old = (Entry<K,V>)oldMap[i] ; old != null ; ) {
Entry<K,V> e = old;
old = old.next;
int index = (e.hash & 0x7FFFFFFF) % newCapacity;
e.next = (Entry<K,V>)newMap[index];
newMap[index] = e;
}
}
这段代码将旧的数据结构转移到新的数据结构中,首先从后向前的遍历链表数组,对于其第i个元素(一个链表)来说,将其赋值给old,然后开始遍历old,对于old的每一个节点计算出它在新的下标值,然后插入。注意插入的两句代码,e.next = (Entry<K,V>)newMap[index]; 是指将新哈希表中这个位置的元素头节点置于e(等价于old)之后;而newMap[index] = e; 代表将e称为这个下标位置的新节点。
计算下标的公式是(e.hash & 0x7FFFFFFF) % newCapacity 表示计算出该节点的哈希值与0x7FFFFFFF相位与,而这个十六进制的数转换为二进制就是31个1,而hash值应该是32位的,因此这部操作的目的就是保持哈希值为正,即首位为0.
在HashMap中的扩容方法是resize()方法:
final Node<K,V>[] resize() {
Node<K,V>[] oldTab = table;
int oldCap = (oldTab == null) ? 0 : oldTab.length;
int oldThr = threshold;
int newCap, newThr = 0;
if (oldCap > 0) {
if (oldCap >= MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return oldTab;
}
else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&
oldCap >= DEFAULT_INITIAL_CAPACITY)
newThr = oldThr << 1; // double threshold
}
else if (oldThr > 0) // initial capacity was placed in threshold
newCap = oldThr;
else { // zero initial threshold signifies using defaults
newCap = DEFAULT_INITIAL_CAPACITY;
newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);
}
if (newThr == 0) {
float ft = (float)newCap * loadFactor;
newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ?
(int)ft : Integer.MAX_VALUE);
}
threshold = newThr;
@SuppressWarnings({"rawtypes","unchecked"})
Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];
table = newTab;
if (oldTab != null) {
for (int j = 0; j < oldCap; ++j) {
Node<K,V> e;
if ((e = oldTab[j]) != null) {
oldTab[j] = null;
if (e.next == null)
newTab[e.hash & (newCap - 1)] = e;
else if (e instanceof TreeNode)
((TreeNode<K,V>)e).split(this, newTab, j, oldCap);
else { // preserve order
Node<K,V> loHead = null, loTail = null;
Node<K,V> hiHead = null, hiTail = null;
Node<K,V> next;
do {
next = e.next;
if ((e.hash & oldCap) == 0) {
if (loTail == null)
loHead = e;
else
loTail.next = e;
loTail = e;
}
else {
if (hiTail == null)
hiHead = e;
else
hiTail.next = e;
hiTail = e;
}
} while ((e = next) != null);
if (loTail != null) {
loTail.next = null;
newTab[j] = loHead;
}
if (hiTail != null) {
hiTail.next = null;
newTab[j + oldCap] = hiHead;
}
}
}
}
}
return newTab;
}
resize function
Node<K,V>[] oldTab = table; //记录旧表
int oldCap = (oldTab == null) ? 0 : oldTab.length; //计算旧的capacity
int oldThr = threshold; //记录旧阈值
int newCap, newThr = 0; //声明新capacity和threshold
if (oldCap > 0) {
if (oldCap >= MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return oldTab;
}
else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&
oldCap >= DEFAULT_INITIAL_CAPACITY)
newThr = oldThr << 1; // double threshold
}
除了一些声明之外,这段代码主要处理当旧容量不是0的时候,说明已经被初始化过,只需进行扩容操作即可,如果旧容量大于等于MAXIMUM_CAPACITY(为什么会大于这个值呢?),那么指提升阈值就好,因为容量已经无法提升,而提升阈值可以一定程度的满足不扩容的条件。否则,新容量等于旧容量的2倍,若新容量小于MAXIMUM_CAPACITY且旧容量大于DEFAULT_INITIAL_CAPACITY,阈值也相应的翻倍。
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16
static final int MAXIMUM_CAPACITY = 1 << 30;
上述是两个常量的值,至于为何要求旧容量要小于DEFAULT_INITIAL_CAPACITY才更新阈值,博主也不清楚,希望有大佬帮忙回答。
else if (oldThr > 0) // initial capacity was placed in threshold
newCap = oldThr;
else { // zero initial threshold signifies using defaults
newCap = DEFAULT_INITIAL_CAPACITY;
newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);
}
if (newThr == 0) {
float ft = (float)newCap * loadFactor;
newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ?
(int)ft : Integer.MAX_VALUE);
}
当旧阈值大于零且旧容量等于0时(因为容量不可能小于0),就将旧阈值赋予新容量,否则使用默认值,一开始真的不知道什么情况会触发这个条件,即旧容量和旧阈值都是0,我测试了构造函数容量设置为0,此时通过tablesizefor计算出的初始化阈值为1。这时我就更晕了,当我把构造函数的的容量设置为1的时候,很奇怪的就会出现的那种情况。这是我一步步的debug出来的,但是并不理解为什么参数是1容量却初始化为0。 当前面步骤执行完毕后,判断新阈值是否为0,是则执行newCap*loadFactor,之后再去除大于MAXIMUM_CAPACITY的情况,并且取整。
threshold = newThr;
@SuppressWarnings({"rawtypes","unchecked"})
Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];
table = newTab;
if (oldTab != null) { //旧集合不为空
for (int j = 0; j < oldCap; ++j) { //遍历旧集合
Node<K,V> e;
if ((e = oldTab[j]) != null) { //某桶不为空
oldTab[j] = null;
if (e.next == null) //该桶的链表只有一个元素
newTab[e.hash & (newCap - 1)] = e;
else if (e instanceof TreeNode) //不只有一个元素而且已经转成了红黑树
((TreeNode<K,V>)e).split(this, newTab, j, oldCap);
else { // preserve order //不知有一个元素但是仍是链表
Node<K,V> loHead = null, loTail = null;
Node<K,V> hiHead = null, hiTail = null;
Node<K,V> next;
do {
next = e.next;
if ((e.hash & oldCap) == 0) {
if (loTail == null)
loHead = e;
else
loTail.next = e;
loTail = e;
}
else {
if (hiTail == null)
hiHead = e;
else
hiTail.next = e;
hiTail = e;
}
} while ((e = next) != null);
if (loTail != null) {
loTail.next = null;
newTab[j] = loHead;
}
if (hiTail != null) {
hiTail.next = null;
newTab[j + oldCap] = hiHead;
}
}
}
}
}
return newTab;
这一段看起来比较长,需要耐心地看,大致地了解这一段代码的作用就是将原数据结构中的数据迁移到新的数据结构。上述的注释基本上能够理清逻辑,剩下就是链表的迁移,在此之前需要介绍一下一些里面用到的位运算的知识:
(e.hash & oldCap)这个运算其实是判断是否需要移动位置。
如果不需要移动,若新链表为空,那么直接把e设置为头节点,不为空就把e放在新链表的尾部;最后把尾节点设置为e。
如果需要移动,按照同样的步骤存储在另一个链表上。而移动的下标由j转变为oldCap+j,无需重新计算哈希。详细如图所示:
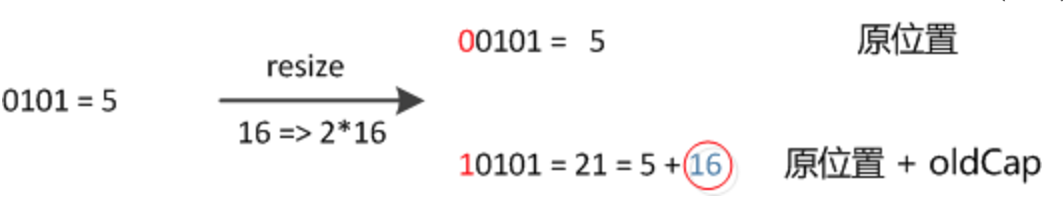
总体来说HashMap1.7查找时间复杂度从O(1)到O(N)不等,如果所有元素都映射到同一个桶中,那么哈希图退化称为链表,此时是最坏的情况O(N);1.8中红黑树查找复杂度为O(logn),性能上有一定程度的提升。
从上面分析扩容代码来看,我们仍然能找出新的不同:
- HashMap有红黑树的参与,而Hashtable没有
- Hashtable多一个contains()方法,等同于containsValue()方法。
- hash值的计算方法不同
先看一下HashMap的计算方式:
插入时计算下标位置:
if ((p = tab[i = (n - 1) & hash]) == null) hash值的来源:
hash(key) hash()方法的详情:
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
hashCode()方法是Object类中的自带方法。
插入计算下标位置: index = (hash & 0x7FFFFFFF) % tab.length; hash值的计算方法: hash = key.hashCode();
3. fail-fast机制
什么是fail-fast,它是java集合中一种错误机制,例如当某一个线程A通过iterator去遍历某集合的过程中,若该集合的内容被其他线程所改变了;那么线程A访问集合时,就会抛出ConcurrentModificationException异常,产生fail-fast事件。
解决方法,换用其他的集合,例如ArrayList换为CopyOnWriteArrayList等。ConcurrentHashMap替代HashMap,简单粗暴。
最新文章
- 跨域API
- Altera SoC与Matlab的联合---第一步 软件安装与硬件测试
- 通过爬虫代理IP快速增加博客阅读量——亲测CSDN有效!
- Eclipse插件安装
- How to Send an Email Using UTL_SMTP with Authenticated Mail Server. (文档 ID 885522.1)
- python函数abs()
- 加州理工大学公开课:机器学习与数据挖掘_线性模型 II(第IX类)
- 图像切换器(ImageSwitcer)的功能与用法
- [LeetCode] Quad Tree Intersection 四叉树相交
- BZOJ1319Sgu261Discrete Roots——BSGS+exgcd+原根与指标+欧拉定理
- 195. Spring Boot 2.0数据库迁移:Flyway
- linked-list-cycle (快慢指针判断是否有环)
- 江西财经大学第一届程序设计竞赛 F题 解方程
- 安卓个性化 Button
- js获取当前域名、Url、相对路径和参数
- Java每日编程day2
- JNI中GetStringChars函数中的isCopy
- UOJ22. 【UR #1】外星人【DP】【思维】
- 函数y=sin(1/x)曲线
- unity Socket TCP连接案例(一)