pandas melt 与pivot 函数
2024-10-07 11:43:18
(掌握这个,基本就完美无缺的任意按照自己的想法,更改列了。)
背景:
最近有个excel 数据需要转化的过程。 数据量还挺大的,大概有30多万。 需要把某些行变成列,有些列又变成行。 这个操作本身就比较烦躁。
更何况数据量达到了几十万的情况下, excel 基本就卡死了。
1 把城市合为一列
2 将空气类型type 分开为成为列
先贴样本:

转化后的结果:

苦恼了很久。
实践:
melt 函数讲解,
frame, -- 需要处理的数据集
id_vars=None, -- 不需要改变的列
value_vars=None,--需要转换的列名,如果剩下的列全部都要转换,就不用写了
var_name=None, --设置对应的维度名
value_name="value", -- 设置对应的度量值名
col_level=None, -- 不知道
first_data_2 = self.pd.melt(deal_data, id_vars=['date', 'hour', 'type'], value_vars=city_data,
var_name='city', value_name='count_clue').fillna(0)
在这里, deal_data 是需要处理数据集, id_vars 不变的列, date , hour, type , 需要转化的列 数组city_data [] , 理论上应该是不用填,下面全部转化。
对应的维度名:city , 对应合起来的度量值。count_clue。
这样就把列都合起来了 。
结果展示
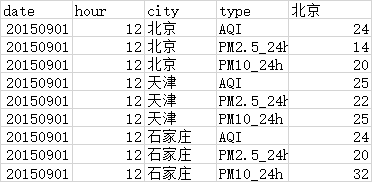
然后我们用piovt 函数,把它列 type 同样列 转变成行。
first_data_3 = self.pd.DataFrame(
self.pd.pivot_table(first_data_2, index=['date', 'hour', 'city', ], columns='type', values='count_clue'))
piovt_table ,我懂的太少了。都是照抄的
贴个链接, 以我的理解, index 是需要的列,然后columns 就是要展开的列, value 是要展开的值,就这样。
https://zhuanlan.zhihu.com/p/31952948
最新文章
- Data source rejected establishment of connection, message from server: "Too many connections"解决办法
- CMD打包文件,解压文件
- python 生成器和递归
- h-ui前端框架
- c#开发Mongo笔记第三篇
- windows上自动设置java环境变量的脚本
- 四项技术 助你提高SQL Server的性能
- 生成元(Digit Generator ,ACM/ICPC Seoul 2005 ,UVa 1583)
- 【暑假】[深入动态规划]UVa 1628 Pizza Delivery
- Installshield: custom action return value
- (原)ippicvmt.lib(ippinit.obj) : error LNK2005: _ippSetCpuFeatures@8 已经在 ippcoremt.lib(ippinit.obj) 中定义
- javascript深入之location对象和history对象
- CSSd的优先级别
- 解决SQL Server 2008无法连接127.0.0.1的问题
- window下安装itchat库
- os及os.path练习题
- Mysql读写分离方案-Amoeba环境部署记录
- mysql 权限管理 目录
- MySQL、Mariadb 复制原理
- Beta 冲刺 七