死磕 java线程系列之线程池深入解析——普通任务执行流程

(手机横屏看源码更方便)
注:java源码分析部分如无特殊说明均基于 java8 版本。
注:线程池源码部分如无特殊说明均指ThreadPoolExecutor类。
简介
前面我们一起学习了Java中线程池的体系结构、构造方法和生命周期,本章我们一起来学习线程池中普通任务到底是怎么执行的。
建议学习本章前先去看看彤哥之前写的《死磕 java线程系列之自己动手写一个线程池》那两章,有助于理解本章的内容,且那边的代码比较短小,学起来相对容易一些。
问题
(1)线程池中的普通任务是怎么执行的?
(2)任务又是在哪里被执行的?
(3)线程池中有哪些主要的方法?
(4)如何使用Debug模式一步一步调试线程池?
使用案例
我们创建一个线程池,它的核心数量为5,最大数量为10,空闲时间为1秒,队列长度为5,拒绝策略打印一句话。
如果使用它运行20个任务,会是什么结果呢?
public class ThreadPoolTest01 {
public static void main(String[] args) {
// 新建一个线程池
// 核心数量为5,最大数量为10,空闲时间为1秒,队列长度为5,拒绝策略打印一句话
ExecutorService threadPool = new ThreadPoolExecutor(5, 10,
1, TimeUnit.SECONDS, new ArrayBlockingQueue<>(5),
Executors.defaultThreadFactory(), new RejectedExecutionHandler() {
@Override
public void rejectedExecution(Runnable r, ThreadPoolExecutor executor) {
System.out.println(currentThreadName() + ", discard task");
}
});
// 提交20个任务,注意观察num
for (int i = 0; i < 20; i++) {
int num = i;
threadPool.execute(()->{
try {
System.out.println(currentThreadName() + ", "+ num + " running, " + System.currentTimeMillis());
Thread.sleep(2000);
} catch (InterruptedException e) {
e.printStackTrace();
}
});
}
}
private static String currentThreadName() {
return Thread.currentThread().getName();
}
}
构造方法的7个参数我们就不详细解释了,有兴趣的可以看看《死磕 java线程系列之线程池深入解析——构造方法》那章。
我们一起来看看一次运行的结果:
pool-1-thread-1, 0 running, 1572678434411
pool-1-thread-3, 2 running, 1572678434411
pool-1-thread-2, 1 running, 1572678434411
pool-1-thread-4, 3 running, 1572678434411
pool-1-thread-5, 4 running, 1572678434411
pool-1-thread-6, 10 running, 1572678434412
pool-1-thread-7, 11 running, 1572678434412
pool-1-thread-8, 12 running, 1572678434412
main, discard task
main, discard task
main, discard task
main, discard task
main, discard task
// 【本文由公从号“彤哥读源码”原创】
pool-1-thread-9, 13 running, 1572678434412
pool-1-thread-10, 14 running, 1572678434412
pool-1-thread-3, 5 running, 1572678436411
pool-1-thread-1, 6 running, 1572678436411
pool-1-thread-6, 7 running, 1572678436412
pool-1-thread-2, 8 running, 1572678436412
pool-1-thread-7, 9 running, 1572678436412
注意,观察num值的打印信息,先是打印了0~4,再打印了10~14,最后打印了5~9,竟然不是按顺序打印的,为什么呢?
让我们一步一步debug进去查看。
execute()方法
execute()方法是线程池提交任务的方法之一,也是最核心的方法。
// 提交任务,任务并非立即执行,所以翻译成执行任务似乎不太合适
public void execute(Runnable command) {
// 任务不能为空
if (command == null)
throw new NullPointerException();
// 控制变量(高3位存储状态,低29位存储工作线程的数量)
int c = ctl.get();
// 1. 如果工作线程数量小于核心数量
if (workerCountOf(c) < corePoolSize) {
// 就添加一个工作线程(核心)
if (addWorker(command, true))
return;
// 重新获取下控制变量
c = ctl.get();
}
// 2. 如果达到了核心数量且线程池是运行状态,任务入队列
if (isRunning(c) && workQueue.offer(command)) {
int recheck = ctl.get();
// 再次检查线程池状态,如果不是运行状态,就移除任务并执行拒绝策略
if (! isRunning(recheck) && remove(command))
reject(command);
// 容错检查工作线程数量是否为0,如果为0就创建一个
else if (workerCountOf(recheck) == 0)
addWorker(null, false);
}
// 3. 任务入队列失败,尝试创建非核心工作线程
else if (!addWorker(command, false))
// 非核心工作线程创建失败,执行拒绝策略
reject(command);
}
关于线程池状态的内容,我们这里不拿出来细讲了,有兴趣的可以看看《死磕 java线程系列之线程池深入解析——生命周期》那章。
提交任务的过程大致如下:
(1)工作线程数量小于核心数量,创建核心线程;
(2)达到核心数量,进入任务队列;
(3)任务队列满了,创建非核心线程;
(4)达到最大数量,执行拒绝策略;
其实,就是三道坎——核心数量、任务队列、最大数量,这样就比较好记了。
流程图大致如下:
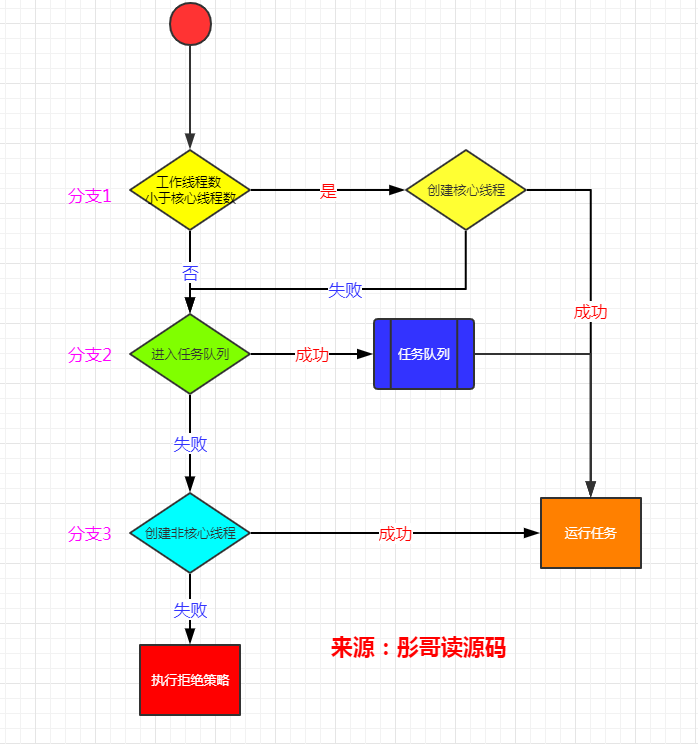
任务流转的过程我们知道了,但是任务是在哪里执行的呢?继续往下看。
addWorker()方法
这个方法主要用来创建一个工作线程,并启动之,其中会做线程池状态、工作线程数量等各种检测。
private boolean addWorker(Runnable firstTask, boolean core) {
// 判断有没有资格创建新的工作线程
// 主要是一些状态/数量的检查等等
// 这段代码比较复杂,可以先跳过
retry:
for (;;) {
int c = ctl.get();
int rs = runStateOf(c);
// 线程池状态检查
if (rs >= SHUTDOWN &&
! (rs == SHUTDOWN &&
firstTask == null &&
! workQueue.isEmpty()))
return false;
// 工作线程数量检查
for (;;) {
int wc = workerCountOf(c);
if (wc >= CAPACITY ||
wc >= (core ? corePoolSize : maximumPoolSize))
return false;
// 数量加1并跳出循环
if (compareAndIncrementWorkerCount(c))
break retry;
c = ctl.get(); // Re-read ctl
if (runStateOf(c) != rs)
continue retry;
// else CAS failed due to workerCount change; retry inner loop
}
}
// 如果上面的条件满足,则会把工作线程数量加1,然后执行下面创建线程的动作
boolean workerStarted = false;
boolean workerAdded = false;
Worker w = null;
try {
// 创建工作线程
w = new Worker(firstTask);
final Thread t = w.thread;
if (t != null) {
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
// 再次检查线程池的状态
int rs = runStateOf(ctl.get());
if (rs < SHUTDOWN ||
(rs == SHUTDOWN && firstTask == null)) {
if (t.isAlive()) // precheck that t is startable
throw new IllegalThreadStateException();
// 添加到工作线程队列
workers.add(w);
// 还在池子中的线程数量(只能在mainLock中使用)
int s = workers.size();
if (s > largestPoolSize)
largestPoolSize = s;
// 标记线程添加成功
workerAdded = true;
}
} finally {
mainLock.unlock();
}
if (workerAdded) {
// 线程添加成功之后启动线程
t.start();
workerStarted = true;
}
}
} finally {
// 线程启动失败,执行失败方法(线程数量减1,执行tryTerminate()方法等)
if (! workerStarted)
addWorkerFailed(w);
}
return workerStarted;
}
这里其实还没到任务执行的地方,上面我们可以看到线程是包含在Worker这个类中的,那么,我们就跟踪到这个类中看看。
Worker内部类
Worker内部类可以看作是对工作线程的包装,一般地,我们说工作线程就是指Worker,但实际上是指其维护的Thread实例。
// Worker继承自AQS,自带锁的属性
private final class Worker
extends AbstractQueuedSynchronizer
implements Runnable
{
// 真正工作的线程
final Thread thread;
// 第一个任务,从构造方法传进来
Runnable firstTask;
// 完成任务数
volatile long completedTasks;
// 构造方法// 【本文由公从号“彤哥读源码”原创】
Worker(Runnable firstTask) {
setState(-1); // inhibit interrupts until runWorker
this.firstTask = firstTask;
// 使用线程工厂生成一个线程
// 注意,这里把Worker本身作为Runnable传给线程
this.thread = getThreadFactory().newThread(this);
}
// 实现Runnable的run()方法
public void run() {
// 调用ThreadPoolExecutor的runWorker()方法
runWorker(this);
}
// 省略锁的部分
}
这里要能够看出来工作线程Thread启动的时候实际是调用的Worker的run()方法,进而调用的是ThreadPoolExecutor的runWorker()方法。
runWorker()方法
runWorker()方法是真正执行任务的地方。
final void runWorker(Worker w) {
// 工作线程
Thread wt = Thread.currentThread();
// 任务
Runnable task = w.firstTask;
w.firstTask = null;
// 强制释放锁(shutdown()里面有加锁)
// 这里相当于无视那边的中断标记
w.unlock(); // allow interrupts
boolean completedAbruptly = true;
try {
// 取任务,如果有第一个任务,这里先执行第一个任务
// 只要能取到任务,这就是个死循环
// 正常来说getTask()返回的任务是不可能为空的,因为前面execute()方法是有空判断的
// 那么,getTask()什么时候才会返回空任务呢?
while (task != null || (task = getTask()) != null) {
w.lock();
// 检查线程池的状态
if ((runStateAtLeast(ctl.get(), STOP) ||
(Thread.interrupted() &&
runStateAtLeast(ctl.get(), STOP))) &&
!wt.isInterrupted())
wt.interrupt();
try {
// 钩子方法,方便子类在任务执行前做一些处理
beforeExecute(wt, task);
Throwable thrown = null;
try {
// 真正任务执行的地方
task.run();
// 异常处理
} catch (RuntimeException x) {
thrown = x; throw x;
} catch (Error x) {
thrown = x; throw x;
} catch (Throwable x) {
thrown = x; throw new Error(x);
} finally {
// 钩子方法,方便子类在任务执行后做一些处理
afterExecute(task, thrown);
}
} finally {
// task置为空,重新从队列中取
task = null;
// 完成任务数加1
w.completedTasks++;
w.unlock();
}
}
completedAbruptly = false;
} finally {
// 到这里肯定是上面的while循环退出了
processWorkerExit(w, completedAbruptly);
}
}
这个方法比较简单,忽略状态检测和锁的内容,如果有第一个任务,就先执行之,之后再从任务队列中取任务来执行,获取任务是通过getTask()来进行的。
getTask()
从队列中获取任务的方法,里面包含了对线程池状态、空闲时间等的控制。
private Runnable getTask() {
// 是否超时
boolean timedOut = false;
// 死循环
for (;;) {
int c = ctl.get();
int rs = runStateOf(c);
// 线程池状态是SHUTDOWN的时候会把队列中的任务执行完直到队列为空
// 线程池状态是STOP时立即退出
if (rs >= SHUTDOWN && (rs >= STOP || workQueue.isEmpty())) {
decrementWorkerCount();
return null;
}
// 工作线程数量// 【本文由公从号“彤哥读源码”原创】
int wc = workerCountOf(c);
// 是否允许超时,有两种情况:
// 1. 是允许核心线程数超时,这种就是说所有的线程都可能超时
// 2. 是工作线程数大于了核心数量,这种肯定是允许超时的
// 注意,非核心线程是一定允许超时的,这里的超时其实是指取任务超时
boolean timed = allowCoreThreadTimeOut || wc > corePoolSize;
// 超时判断(还包含一些容错判断)
if ((wc > maximumPoolSize || (timed && timedOut))
&& (wc > 1 || workQueue.isEmpty())) {
// 超时了,减少工作线程数量,并返回null
if (compareAndDecrementWorkerCount(c))
return null;
// 减少工作线程数量失败,则重试
continue;
}
try {
// 真正取任务的地方
// 默认情况下,只有当工作线程数量大于核心线程数量时,才会调用poll()方法触发超时调用
Runnable r = timed ?
workQueue.poll(keepAliveTime, TimeUnit.NANOSECONDS) :
workQueue.take();
// 取到任务了就正常返回
if (r != null)
return r;
// 没取到任务表明超时了,回到continue那个if中返回null
timedOut = true;
} catch (InterruptedException retry) {
// 捕获到了中断异常
// 中断标记是在调用shutDown()或者shutDownNow()的时候设置进去的
// 此时,会回到for循环的第一个if处判断状态是否要返回null
timedOut = false;
}
}
}
注意,这里取任务会根据工作线程的数量判断是使用BlockingQueue的poll(timeout, unit)方法还是take()方法。
poll(timeout, unit)方法会在超时时返回null,如果timeout<=0,队列为空时直接返回null。
take()方法会一直阻塞直到取到任务或抛出中断异常。
所以,如果keepAliveTime设置为0,当任务队列为空时,非核心线程取不出来任务,会立即结束其生命周期。
默认情况下,是不允许核心线程超时的,但是可以通过下面这个方法设置使核心线程也可超时。
public void allowCoreThreadTimeOut(boolean value) {
if (value && keepAliveTime <= 0)
throw new IllegalArgumentException("Core threads must have nonzero keep alive times");
if (value != allowCoreThreadTimeOut) {
allowCoreThreadTimeOut = value;
if (value)
interruptIdleWorkers();
}
}
至此,线程池中任务的执行流程就结束了。
再看开篇问题
观察num值的打印信息,先是打印了0~4,再打印了10~14,最后打印了5~9,竟然不是按顺序打印的,为什么呢?
线程池的参数:核心数量5个,最大数量10个,任务队列5个。
答:执行前5个任务执行时,正好还不到核心数量,所以新建核心线程并执行了他们;
执行中间的5个任务时,已达到核心数量,所以他们先入队列;
执行后面5个任务时,已达核心数量且队列已满,所以新建非核心线程并执行了他们;
再执行最后5个任务时,线程池已达到满负荷状态,所以执行了拒绝策略。
总结
本章通过一个例子并结合线程池的重要方法我们一起分析了线程池中普通任务执行的流程。
(1)execute(),提交任务的方法,根据核心数量、任务队列大小、最大数量,分成四种情况判断任务应该往哪去;
(2)addWorker(),添加工作线程的方法,通过Worker内部类封装一个Thread实例维护工作线程的执行;
(3)runWorker(),真正执行任务的地方,先执行第一个任务,再源源不断从任务队列中取任务来执行;
(4)getTask(),真正从队列取任务的地方,默认情况下,根据工作线程数量与核心数量的关系判断使用队列的poll()还是take()方法,keepAliveTime参数也是在这里使用的。
彩蛋
核心线程和非核心线程有什么区别?
答:实际上并没有什么区别,主要是根据corePoolSize来判断任务该去哪里,两者在执行任务的过程中并没有任何区别。有可能新建的时候是核心线程,而keepAliveTime时间到了结束了的也可能是刚开始创建的核心线程。
Worker继承自AQS有何意义?
前面我们看了Worker内部类的定义,它继承自AQS,天生自带锁的特性,那么,它的锁是用来干什么的呢?跟任务的执行有关系吗?
答:既然是跟锁(同步)有关,说明Worker类跨线程使用了,此时我们查看它的lock()方法发现只在runWorker()方法中使用了,但是其tryLock()却是在interruptIdleWorkers()方法中使用的。
private void interruptIdleWorkers(boolean onlyOne) {
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
for (Worker w : workers) {
Thread t = w.thread;
if (!t.isInterrupted() && w.tryLock()) {
try {
t.interrupt();
} catch (SecurityException ignore) {
} finally {
w.unlock();
}
}
if (onlyOne)
break;
}
} finally {
mainLock.unlock();
}
}
interruptIdleWorkers()方法的意思是中断空闲线程的意思,它只会中断BlockingQueue的poll()或take()方法,而不会中断正在执行的任务。
一般来说,interruptIdleWorkers()方法的调用不是在本工作线程,而是在主线程中调用的,还记得《死磕 java线程系列之线程池深入解析——生命周期》中说过的shutdown()和shutdownNow()方法吗?
观察两个方法中中断线程的方法,shutdown()中就是调用了interruptIdleWorkers()方法,这里tryLock()获取到锁了再中断,如果没有获取到锁则不中断,没获取到锁只有一种情况,也就是lock()所在的地方,也就是有任务正在执行。
而shutdownNow()中中断线程则很暴力,并没有tryLock(),而是直接中断了线程,所以调用shutdownNow()可能会中断正在执行的任务。
所以,Worker继承自AQS实际是要使用其锁的能力,这个锁主要是用来控制shutdown()时不要中断正在执行任务的线程。
欢迎关注我的公众号“彤哥读源码”,查看更多源码系列文章, 与彤哥一起畅游源码的海洋。

最新文章
- Editbox之三个框框
- datatable去重
- <转>你相信外星人的存在吗
- 【转】MAPI over HTTP协议
- java 静态方法和实例方法的区别(转)
- unity初始篇 选择游戏对象
- ZooKeeper学习第八期——ZooKeeper伸缩性
- L4 如何在XCode中下进行工作
- LoadRunner - 结果分析 / Result Analysis
- 友盟分享--集成QQ和微信
- Qt在Windows下的三种编程环境搭建
- 通过 IP 访问谷歌
- 基于visual Studio2013解决面试题之1404希尔排序
- 阿里2015回顾面试招收学历(获得成功offer)
- ARP协议的基础知识
- php moungoDB
- Make a plan
- LeetCode 232:Implement Queue using Stacks
- [No0000108]Git1/9-Git简介与入门
- linux系统下邮件的发送