Flink系列之状态及检查点
Flink不同于其他实时计算的框架之处是它可以提供针对不同的状态进行编程和计算。本篇文章的主要思路如下,大家可以选择性阅读。
1. Flink的状态分类及不同点。
2. Flink针对不同的状态进行编程。
3. 检查点机制和配置。
4. 状态的存储。
- Flilnk的状态分类及不同点
Flink有两种不同的状态分类,一种是Keyed State(键状态),一种是Operator State(算子状态)。
- Keyed State
主要是针对KeyedStream中使用,当使用keyBy方法的时候进行计算。 我们都知道在计算的过程中就是将Flink按照<并行operator, key> 进行计算,每个key又归属于单个Operator,所以我们可以简单的理解为<operator, key>。也就是说首先按Operator分配到不同的实例,然后在不同的实例中,相同的Key分配到相同的组中,然后这些状态就可以在相同的组中进行获取和计算。
- Operator State
主要针对不同的算子的状态计算。按照不同的算子如Map, FlatMap,Reduce等算子去分配不同的实例群。像Kafka Connector的例子就很好的应用了这个功能,根据不同的topic去读取不同的状态,比如计算获取到topic的paritition分区和 offset偏移量。 每个算子实例会维护着这个topic的partition及offset的Map状态,这个例子就是很好的使用了Opertator的state。如果Operator并行度发生改变了的话,那么状态也会相应的分配好对应的状态。
- 可管理的及原生状态
这两种状态又分为 Managed State (可管理状态)和 Raw State (原生状态)
- Managed State : 可管理状态就是自己去定义和编写状态处理的逻辑,全部由自己和Flink进行控制。
- Raw State : 原生状态也就是在Operator算子触发 checkPoint 检查点的时候,Flink会在其数据结构中写入一部分字节码Byte,Flink只能看到其中有一些码,但是无法去进行控制。
所有的流数据功能都可以使用Managed State,这个也是Flink编程所推荐的。因为要使用Raw State的话比较底层也比较复杂,要实现算子方法时才使用。
- Flink针对不同的状态进行编程
我们只针对可管理的状态进行操作,不同的管理 Keyed State 和Operator State 状态原始方法定义可参考官网介绍。
- Keyed State
我们针对Keyed managed state进行编程。来个场景,假如Flink计算某个功能的时间,如果某个功能Key时间超过某个阈值了则进行计数,如果数据超过了设置的次数,那么直接输出到控制台。直接参考如下代码。
代码大致的思路是:
继承RichFlatMapFunction, 定义一个ListState<Long>用于记录当前的状态。
定义阈值和错误次数值,触发后直接输出控制台下。
open方法实例化ListState。在里边设置了一下状态的TTL,即状态的生命周期。
flatMap方法按key分配后的value进行判断和记录。
最后main方法进行数据准备和输出。
package myflink.state; import org.apache.commons.compress.utils.Lists;
import org.apache.flink.api.common.functions.RichFlatMapFunction;
import org.apache.flink.api.common.state.ListState;
import org.apache.flink.api.common.state.ListStateDescriptor;
import org.apache.flink.api.common.state.StateTtlConfig;
import org.apache.flink.api.common.time.Time;
import org.apache.flink.api.common.typeinfo.TypeHint;
import org.apache.flink.api.common.typeinfo.TypeInformation;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector; import java.util.ArrayList;
import java.util.List; public class ThresholdWarning extends RichFlatMapFunction<Tuple2<String, Long>, Tuple2<String, List<Long>>> { //通过ListState来存储非正常数据的状态
private transient ListState<Long> abnormalData;
//需要监控的阈值
private Long threshold;
//触发报警的次数
private Integer numberOfTimes; public ThresholdWarning(Long threshold, Integer numberOfTimes) {
this.threshold = threshold;
this.numberOfTimes = numberOfTimes;
} @Override
public void open(Configuration parameters) throws Exception { ListStateDescriptor listStateDescriptor = new ListStateDescriptor<Long>("abnormal-state",
TypeInformation.of(Long.class)); //状态存活生命周期设置TTL Time To Live
StateTtlConfig ttlConfig = StateTtlConfig
//设置有效期为10秒
.newBuilder(Time.seconds(10L))
//设置有效的更新规则,当创建和写入的时候需要重新更新为10S
.setUpdateType(StateTtlConfig.UpdateType.OnCreateAndWrite)
//设置状态的可见性,设置状态如果没有删除,那么就是可见的,另外一个值:ReturnExpiredIfNotCleanedUp ,
// 如果没有清理的话,状态会一直可见的
.setStateVisibility(StateTtlConfig.StateVisibility.NeverReturnExpired)
.build(); //设置TTL配置
listStateDescriptor.enableTimeToLive(ttlConfig); //通过状态名称(句柄)获取状态实例,如果不存在则会自动建
abnormalData = getRuntimeContext().getListState(new ListStateDescriptor<Long>("abnormal-state",
TypeInformation.of(Long.class)));
} @Override
public void flatMap(Tuple2<String, Long> value, Collector<Tuple2<String, List<Long>>> out) throws Exception {
Long inputValue = value.f1;
//如果输入的值超过阈值,则记录该次不正常的数据信息
if(inputValue >= threshold) {
abnormalData.add(inputValue);
} ArrayList<Long> list = Lists.newArrayList(abnormalData.get().iterator()); //如果不正常的数据超过了指定的数量,则输出报警信息
if(list.size() >= numberOfTimes) {
out.collect(Tuple2.of(value.f0 + " 超过指定阈值数量", list));
//报警信息输出后,清空状态
abnormalData.clear();
}
} public static void main(String[] args) throws Exception {
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); //设置并行度为1,用于观察输出
// env.setParallelism(1); DataStreamSource<Tuple2<String, Long>> tuple2DataStreamSource = env.fromElements(
Tuple2.of("a", 50L), Tuple2.of("a", 80L), Tuple2.of("a", 400L),
Tuple2.of("a", 100L), Tuple2.of("a", 200L), Tuple2.of("a", 200L),
Tuple2.of("b", 100L), Tuple2.of("b", 200L), Tuple2.of("b", 200L),
Tuple2.of("b", 500L), Tuple2.of("b", 600L), Tuple2.of("b", 700L)); tuple2DataStreamSource
.keyBy(0)
//超过100的阈值3次后输出报警信息
.flatMap(new ThresholdWarning(100L, 3))
.printToErr(); env.execute("Managed Keyed State");
}
}
输出的结果如下,大于等于100的出现3次即进行输出。和我们想象的都一样。
1> (b 超过指定阈值数量,[100, 200, 200])
1> (b 超过指定阈值数量,[500, 600, 700])
3> (a 超过指定阈值数量,[400, 100, 200])
- operator state
我们还在原来基础的例子上调整一下,不按key,按Operator类型,只要超过时间的次数达到了就要输出。在其中,把Operator的hashCode进行输出一下,用于区分是否为相同的Operator。首先我们将并行度设置为1,然后一会儿再把并行度调整成2。
代码的大致思路为:
继承RichFlatMapFunction,实现CheckpointedFunction接口,即在触发检查点的时候进行操作。
initializeState方法的时候将opertor的状态和检查点状态进行初始化。
snapshotState方法即存储状态时将当时的镜像进行存储。可以存储到外部设备。
flatMap的时候进行阈值判断和数据收集。
main方法进行检查点设置,数据准备,执行和输出。
package myflink.state; import org.apache.flink.api.common.functions.RichFlatMapFunction;
import org.apache.flink.api.common.state.ListState;
import org.apache.flink.api.common.state.ListStateDescriptor;
import org.apache.flink.api.common.typeinfo.TypeHint;
import org.apache.flink.api.common.typeinfo.TypeInformation;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.runtime.state.FunctionInitializationContext;
import org.apache.flink.runtime.state.FunctionSnapshotContext;
import org.apache.flink.streaming.api.CheckpointingMode;
import org.apache.flink.streaming.api.checkpoint.CheckpointedFunction;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.CheckpointConfig;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector; import java.util.ArrayList;
import java.util.List; public class ThresholdOperatorWarning extends RichFlatMapFunction<Tuple2<String, Long>, Tuple2<String,
List<Tuple2<String, Long>>>> implements CheckpointedFunction { //非正确数据状态
private List<Tuple2<String, Long>> bufferedData; //检查点状态
private transient ListState<Tuple2<String, Long>> checkPointedState; //需要监控的阈值
private Long threshold;
//次数
private Integer numberOfTimes; ThresholdOperatorWarning(Long threshold, Integer numberOfTimes) {
this.threshold = threshold;
this.numberOfTimes = numberOfTimes;
this.bufferedData = new ArrayList<>();
} @Override
public void flatMap(Tuple2<String, Long> value, Collector<Tuple2<String, List<Tuple2<String, Long>>>> out)
throws Exception {
Long inputValue = value.f1; //超过阈值则进行记录
if(inputValue >= threshold) {
bufferedData.add(value);
} //超过指定次数则进行汇总和汇总输出
if(bufferedData.size() >= numberOfTimes) {
//输出状态实例的hashCode
out.collect(Tuple2.of(checkPointedState.hashCode() + "阈值报警! " , bufferedData ));
//清理缓存
bufferedData.clear();
} } @Override
public void snapshotState(FunctionSnapshotContext context) throws Exception {
//当数据进行快照时,将数据存储到checkPointedState
checkPointedState.clear();
for (Tuple2<String, Long> element : bufferedData) {
checkPointedState.add(element);
}
} @Override
public void initializeState(FunctionInitializationContext context) throws Exception {
//这里获取的是operatorStateStore
checkPointedState = context.getOperatorStateStore().getListState(new ListStateDescriptor<Tuple2<String, Long>>(
"abnormalData", TypeInformation.of(new TypeHint<Tuple2<String, Long>>() {})
)); //如果发生重启,则需要从快照中将状态进行恢复
if(context.isRestored()) {
for (Tuple2<String, Long> element : checkPointedState.get()) {
bufferedData.add(element);
}
}
} public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); //开启检查点
env.enableCheckpointing(1000L);
// 其他可选配置如下: // 设置语义,默认是EXACTLY_ONCE
env.getCheckpointConfig().setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE);
// 设置检查点之间最小停顿时间
env.getCheckpointConfig().setMinPauseBetweenCheckpoints(500);
// 设置执行Checkpoint操作时的超时时间
env.getCheckpointConfig().setCheckpointTimeout(60000);
// 设置最大并发执行的检查点的数量
env.getCheckpointConfig().setMaxConcurrentCheckpoints(1);
// 将检查点持久化到外部存储
env.getCheckpointConfig().enableExternalizedCheckpoints(
CheckpointConfig.ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION); //设置并行度为1
env.setParallelism(1);
//数据源 DataStreamSource<Tuple2<String, Long>> tuple2DataStreamSource = env.fromElements(
Tuple2.of("a", 50L), Tuple2.of("a", 80L), Tuple2.of("a", 400L),
Tuple2.of("a", 100L), Tuple2.of("a", 200L), Tuple2.of("a", 200L),
Tuple2.of("b", 100L), Tuple2.of("b", 200L), Tuple2.of("b", 200L),
Tuple2.of("b", 500L), Tuple2.of("b", 600L), Tuple2.of("b", 700L)
); tuple2DataStreamSource.flatMap(new ThresholdOperatorWarning(100L, 3))
.printToErr(); env.execute("managed Operator State"); } }
当前并行度为1,结果如下,数据没有按key统计,而是按照里边的值进行统计,符合我们的要求。因为是同一个Operator,所以hashcode是一样的。
(1629838640阈值报警! ,[(a,400), (a,100), (a,200)])
(1629838640阈值报警! ,[(a,200), (b,100), (b,200)])
(1629838640阈值报警! ,[(b,200), (b,500), (b,600)])
接下来将并行度设置为2,结果如下。我们看一下main里边的数据,符合大于等于100的数据一共有10个,那么两个不同的operator分配的时候这10数据的时候,一个operator分5个,那么满足超过3个的时候才收集并输出。因为5个里边只有一组3个满足,2个不满足所以不会输出,所以符合我们的预期。
1> (475161679阈值报警! ,[(a,100), (a,200), (b,200)])
2> (1633355453阈值报警! ,[(a,400), (a,200), (b,100)])
- 检查点的机制和配置
- 检查点的机制
上边我们程序里边设置了检查点,检查点是当数据进行处理的时候将数据的状态进行记录,当程序出现问题的时候方便恢复。
可以像这样的情况: 数据源——> 123456789|12345678| 12341234|——>sink。|即检查点,是一个checkpoint barrier,当算子运行计算的时候会把当前的状态进行记录,比如读取Kafka的数据,假如读取到offset=6868,然后将这个值进行了记录, 当这时有机器出现了问题,程序需要进行恢复并执行,那么需要重新读取这条数据再计算。引用一张图片可以有更清楚的认识。
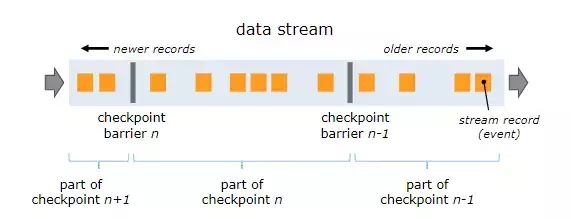
- 检查点的配置
默认情况下,检查点是关闭着的,我们需要明确开启。其他的一些配置可参考如下内容:
//开启检查点
env.enableCheckpointing(1000L);
// 其他可选配置如下: // 设置语义,默认是EXACTLY_ONCE
env.getCheckpointConfig().setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE);
// 设置检查点之间最小停顿时间
env.getCheckpointConfig().setMinPauseBetweenCheckpoints(500);
// 设置执行Checkpoint操作时的超时时间
env.getCheckpointConfig().setCheckpointTimeout(60000);
// 设置最大并发执行的检查点的数量
env.getCheckpointConfig().setMaxConcurrentCheckpoints(1);
// 将检查点持久化到外部存储
env.getCheckpointConfig().enableExternalizedCheckpoints(
CheckpointConfig.ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION);
- 检查点手工保存
flink支持手工将检查点的状态存储到外部,也可以指定存储到HDFS文件。存储到外边是为了程序出现了问题时进行恢复,比如OOM问题。程序升级和重启时也需要重新从检查点进行恢复。
# 触发指定id的作业的Savepoint,并将结果存储到指定目录下
bin/flink savepoint :jobId [:targetDirectory]
- 状态的存储
Keyed State和Operator State会存储在内存中,因为数据是持续不断的输入的,当数据量非常大的时候,内存会出现不足的情况,那么我们也是需要将当前的状态进行保存的。官方称为状态后端。
- Flink的状态保存支持3种方式
MemoryStateBackend,这种方式是将数据存储在JVM中,这种方式是用于开发。
FsStateBackend, 即以文件的形式存储到磁盘中,可以是HDFS或本地文件。当JobManger把任务发送给Taskmanger进行计算,此时数据会在JVM中,当触发了checkpoint后才会将数据存储到文件中。
RocksDBStateBackend,这种形式是介于前边两种的情况,这个是将状态数据到KV数据库中,当触发状态的时候会将数据再持久化到文件中。这样即提高了速度,空间也变得更大了。
- 状态存储配置
默认情况是MemoryStateBackend,即内存中。
剩下两种的配置如下,这种方式只对当前Job有效。RocksDB配置的话需要额外引用一下包。
// 配置 FsStateBackend
env.setStateBackend(new FsStateBackend("hdfs://namenode:60060/flink/checkpoints"));
// 配置 RocksDBStateBackend
env.setStateBackend(new RocksDBStateBackend("hdfs://namenode:60060/flink/checkpoints"))
通过修改flink-yaml.conf可以对该集群所有作业生效。
state.backend: filesystem
state.checkpoints.dir: hdfs://namenode:60060/flink/checkpoints
MemoryStateBackend
最新文章
- python之platform模块
- iPad开发(Universal Applications)
- linux多线程-互斥&条件变量与同步
- SQL Server 2008 R2——学习/练习/错误/总结/搜集
- artDialog ( v 6.0.2 ) content 参数引入页面 html 内容
- Unicode编码的熟悉与研究过程(内附全部汉字编码列表)
- Powerpoin怎么制作电子相册|PPT制作电子相册教程
- Css小技巧-图片垂直居中
- 基于visual Studio2013解决C语言竞赛题之1051数的顺序
- C#的数据类型总结(2):decimal ,double,float的区别
- java 运行环境
- PHP中使用sleep函数实现定时任务实例分享
- 运行Maven时报错:No goals have been specified for this build
- hadoop下载地址
- Springboot 如何加密,以及利用Swagger2构建Restful API
- redis惊群
- parseObject方法将json字符串转换成Map
- ansible 提示安装sshpass
- MQ 发布/订阅者模式
- 关于<ul> 下的 <li> 里面的<a> 标签字体颜色不能控制