spark之依赖关系
2024-10-21 15:45:21
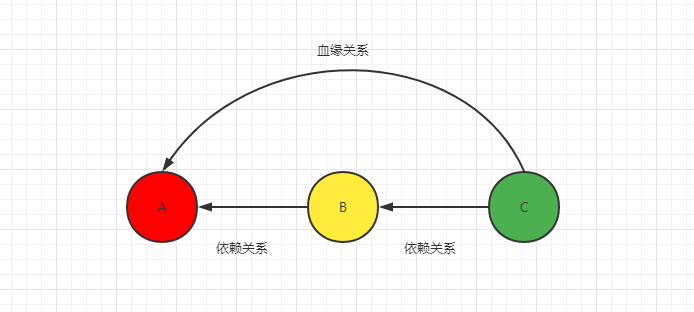
spark的每个RDD都会记录从创建到当前算子的依赖(血缘关系),当该RDD的部分分区数据丢失时,它可以根据这些信息来重新运算和恢复丢失的数据分区 --- toDebugString 方法查看
OneToOneDependency窄依赖,上游的RDD的一个分区被下游的RDD的一个分区所独享(独生子女)
ShuffleDependency宽依赖,上游的RDD的一个分区被下游RDD的多个分区所共享(多生子女)
最新文章
- 如何将github上的 lib fork之后通过podfile 改变更新源到自己fork的地址
- Object.observe
- Thinking in java学习笔记之初始化
- python 学习笔记九 队列,异步IO
- Virtual Friend Function
- Errors running builder "Integrated External Tool Builder" on project
- Web APP 随笔
- Android开发之Service的写法以及与Activity的通信
- jquery选择器中逗号的使用
- js面试题-2
- socket.io 入门篇(二)
- (转)spring aop(下)
- BZOJ 3123: [Sdoi2013]森林 [主席树启发式合并]
- Oracle:常用的一些基本操作
- VMWare的网络
- Codeforces899C Dividing the numbers(数论)
- 安全工具-cansina
- 用jQuery监听浏览器窗口的变化
- 07-django项目
- 编译错误 error C2451: “std::_Unforced”类型的条件表达式是非法的