[1] Multi-View Transformer for 3D Visual Grounding 论文精读
参考:
https://zhuanlan.zhihu.com/p/467913475
3D Visual Grounding小白调研笔记
https://zhuanlan.zhihu.com/p/34656727
zero-shot learning 入门
https://blog.csdn.net/rtygbwwwerr/article/details/50778098
交叉熵
https://zhuanlan.zhihu.com/p/388504127
Visual grounding系列--领域初探
很有可能Visual Grounding就是我的大方向了,目前打算好好读读这篇文章的所有引用。这是我当前对它的理解:https://www.cnblogs.com/loveandninenine/p/17131672.html
可能有很多不正确的地方,但是大概率博士课题就是这个方向了,好,言归正传,讲讲这篇文章。
题目
简单明确,就像这篇文章写的清晰、优雅一样。这是一篇基于Transformer的使用Multi-View来解决3D Visual Grounding问题的文章,是香港中文大学的huangshijia同学的工作,综合度非常高。
背景
3D的visual grounding与2D相比,多了一个非常严重的问题:视角,举个例子:

论文中的FIg 1,face the bad的视角只有一个,但是不在这个视角下,the pillow on the far right却不是同一个,那么如何解决这个视角的问题呢?这是本文所面对的主要挑战——模型预测与视角相关,因此如果学习单一视角下的数据,切换视角后模型很可能完全无法工作。因此本文给到的第一个解决方案——切换视角训练模型,希望能够得到一个对视角鲁棒的模型。
另外,其实我是第一次接触Visual Grounding这个工作,我其实很不理解这个工作有啥实际价值,但是文章把它的意义写的非常明确,如下:

本文的创新点在于,从3d数据的深层次的特点出发,考虑了多视图,其实本质就是用了多视角下的场景数据进行训练,从而得到一个对视图鲁棒的模型。
Related work
惭愧,related work我基本没有看懂,主要分为三部分,3d视觉定位、有监督的自然语言学习、以及多视图学习。挺吃力的其实,因为这三个领域的文章我都没读过,除了NLP的《Attention is all you need》、
因此在这不做过多介绍,接下来我会从这三个领域分别入手,读一些文章。
Method
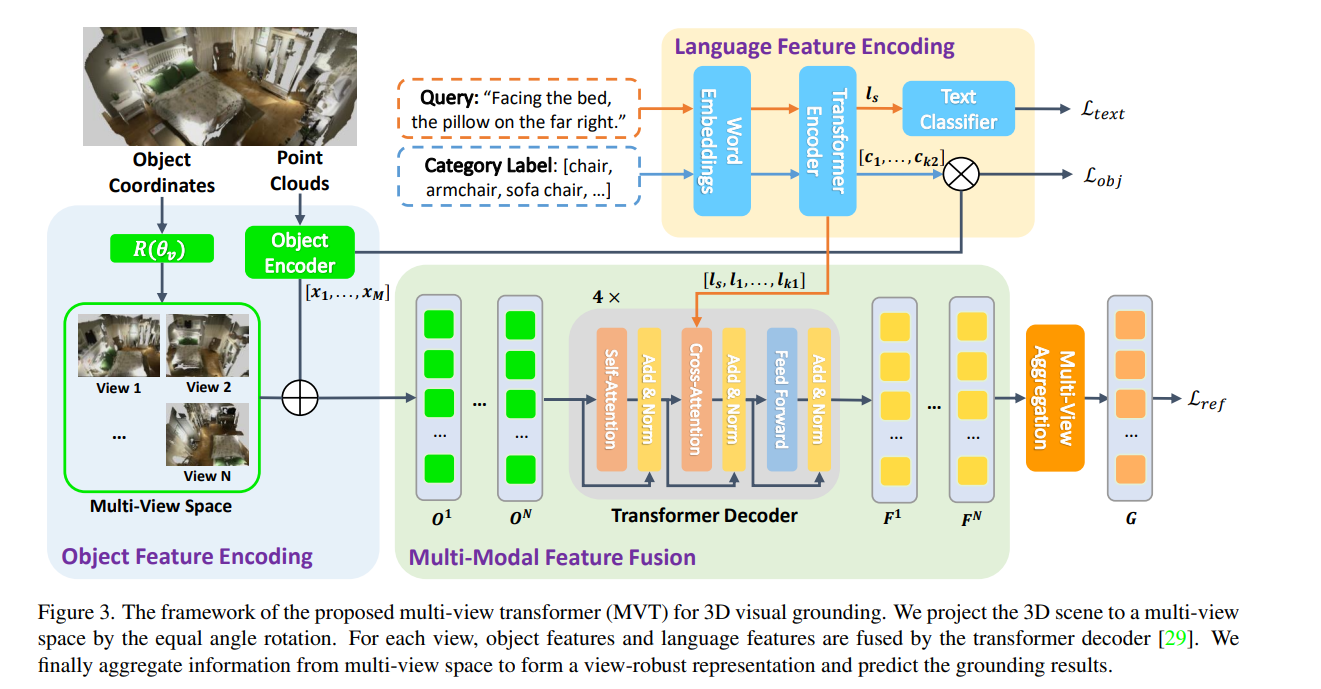
这就是整个MVT的架构了。
整个图画的还算不错,可以对着图完整地清晰讲出整个工作。图总共分为四个部分,咱们一点一点讲。
物体特征编码
首先,为什么会有物体特征编码这个工作?
因为在之前的工作中,基本都是没有考虑多视图问题的工作,而物体的特征提取是算力的主要瓶颈,因此如果计算多个视图下的object feature,将是一件非常costly的事情,这便是本文面临的第二个挑战——算力和效率上的不允许。本文给出的解决方案是——将物体的特征独立进行编码,而位置编码随着视角的切换进行编码。
这便是本部分右边的Object Encoder做的工作,x1到xm是这个场景中M个物体的特征,其使用PointNet++作为特征提取器,公式为: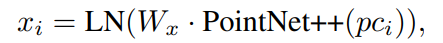
而左边输入的则是场景坐标,随后对其进行旋转,得到N个视图下的场景,具体的旋转方式非常容易描述,只沿着Z轴旋转,均匀地转一圈,比如如果是想得到四个视图,N=4,那么就是这个样子:
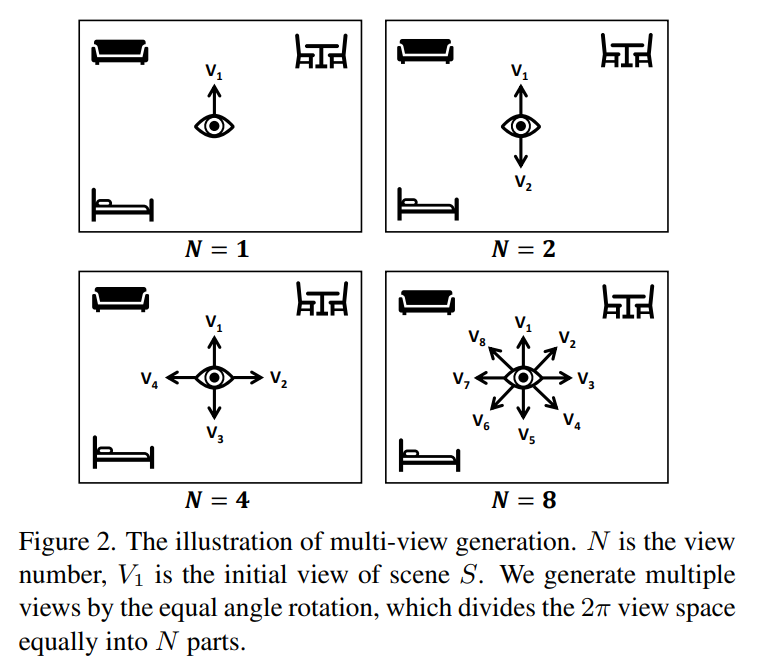
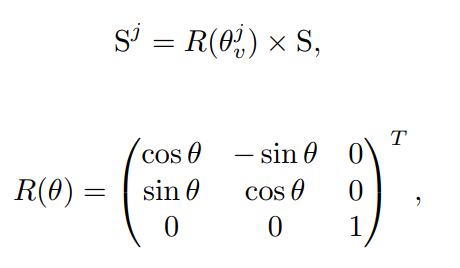
随后我们就得到了一个S序列,即不同视角下的S场景。
然后,开始做PE。
首先,将object使用box的中心点进行表示,然后对这些点进行旋转,旋转的方式也非常简单,就是让这个点乘以上面那个旋转矩阵,对得到的内容乘以一个权重矩阵,再过一层Normalization,就得到了最终次物体的PE。随后,将每个视角下的每个物体的PE直接加到上述得到的物体特征x上,就完成了对物体的位置编码。
语言特征编码
这里我现在其实不是很懂,简单说说吧,等我看了Bert之后,了解一些常用的NLP架构之后,再反过头来看这个。
首先看上面一行,输入的就是所谓的“文本描述”,也是作为Query存在的,对它过了一层Word Embedding,本文使用的是Bert,随后过了一层Transformer,并用来做cross-Attention,因为这里提取到的特征本质上已经是语言的特征了,可以直接和物体做跨注意力了。
除此之外,作者还在后面用了一个Text Classfier,本质上其实就是两个FC,用于预测文本所描述的具体物体,从而形成一个loss用来增强Bert,这个在NLP中好像挺有名的,李沐老师也讲过Bert 微调。
与此同时,为了让物体编码器增强,本文还使用Bert对物体标签进行了处理,利用句子级别的标签文本特征,对Object进行有监督的训练,于是就有了第二个loss。
多视图特征融合
接下来,作者用了一个非常简单但是让人拍案叫绝的操作——引入对称函数。这不得不让我想起当年祁芮中台的PointNet的壮举。作者是这么做的,如下:
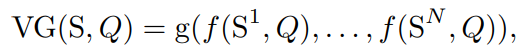
S是场景,Q是Query,也就是所谓的“描述文本”,f是一个特征提取的共享网络,可以理解成大概就是中间的Transformer这个部分了,它分别将不同视角下的描述文本感兴趣的场景信息找出来。
随后,g是一个顺序不依赖函数,换句话说,g是一个对称函数,它聚合了所有视图下的信息,并做了输出预测。
整个过程和Pointnet的灵感可以说是如出一辙,唯一不同的大概就是PointNet使用max函数,而MVT使用的确实Avg函数。
首先,将分别做PE的物体特征输入到网络,对其做自注意力,进一步对他们的特征进行抽象,随后于文本编码器产生的query文本做跨注意力,意图让模型找到文本所描述的内容,这就是经典的Transformer模型了,一共循环四次,最后输出了不同视图下的学习的结果——即面对这个query在不同视图下产生的预测。随后,就是将这些特征融合了。这里就是求平均后过了两层FC,最后输出的就是最终结果,这里也和ground truth做了一个loss。
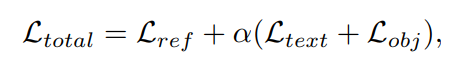
结果

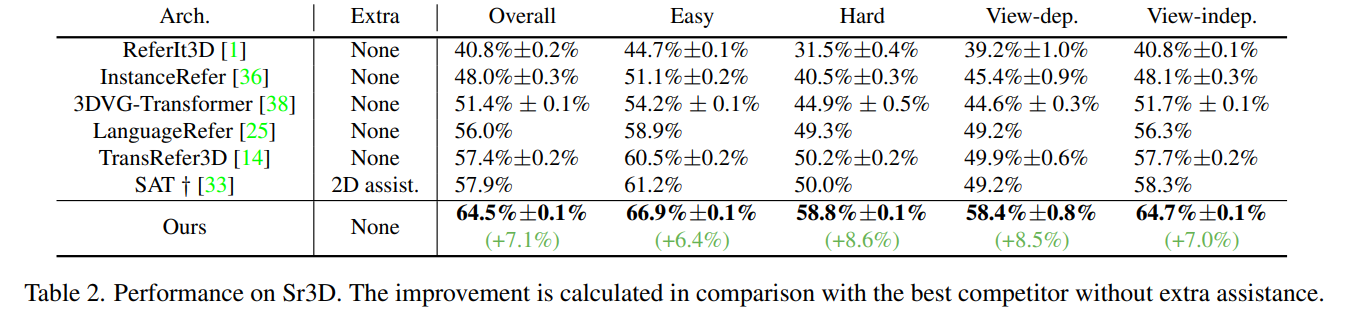
可以看到,这个提升是一个非常骇人的提升,所以对多视角的鲁棒性非常有必要。
感受
本文提出了一个基于视图鲁棒性的模型,非常新颖。、
但是本文解决的也是一个非常简单的问题,因为输入的场景和Query本身,并不受限制于视图。就像第一幅图那样,文本描述是面向床,比较远的右侧的枕头。而不是“我右侧的枕头”。这是一个非常简单的问题。最初我打算读这篇文章的时候觉得是它解决了随着视图变换ground truth也会跟着变换的工作,但其实不是,想想都很难。“我右侧的枕头”,如果我的视角旋转90度,那将变成“我左侧的枕头”,答案是完全相反的。显然这个问题目前没有人去研究,当然了,也没有数据集。3D数据集好像也就这么三个?看本文的意思是这样,本文将数据集进行了旋转而已。而至于我说的那个十分困难的问题,即ground truth要依赖于视角的问题,我觉得还有很长的一段路要走,这也是我想做这个方向的主要原因。
最新文章
- MongoDB数据库用户名和密码的设置
- 获取ItemsControl中当前item的binding数据
- libreoffice实现WORD文档转PDF文档
- JavaScript学习笔记(12)——JavaScript自定义对象
- bzoj 2734: [HNOI2012]集合选数 状压DP
- 《Hadoop权威》学习笔记五:MapReduce应用程序
- Hive_UDF函数中集合对象初始化的注意事项
- centos7之zabbix3.2的fping监控
- NOIP-质因数分解
- 理解 ASP.NET Web API 中的 HttpParameterBinding
- servletContext和request对象的生命周期比较
- Attention Model
- MySQL学习笔记:select语句性能优化建议
- 【UOJ】#49.铀仓库
- 使用BulkCopy报错 从 bcp 客户端收到一个对 colid 19 无效的列长度
- svg 配合cesium使用
- synchronized的四种用法
- web项目_学生证管理系统
- Logback日志存放路径的问题
- 【BZOJ1227】[SDOI2009]虔诚的墓主人(线段树)