HashMap面试知识点总结
背景
HashMap 的相关问题在校招面试中十分常见, 作为新人, HashMap 的各个问题应该要理解的十分透彻才行. 此外, ConcurrentHashMap, Hashtable 也是经常与 HashMap 一同被问, 下文中都有介绍.
HashMap 原理
1. 底层数据结构
HashMap 在 JDK1.8 之前底层使用的是数组+链表的拉链式结构; 在 JDK1.8 之后引入了红黑树, 当链表长度大于阈值的时候就会将这个链表转化为红黑树.
2. JDK1.8 中 HashMap 的改动
如上面所说, JDK1.8 中对 HashMap 做了一些改动, 在 JDK1.8 之前链表的插入使用的是头插法, 作者认为刚刚插入的数据被查询的可能性比较大, 头插法在多线程 resize 的时候可能会产生循环链表. JDK1.8 之后改为了尾插法, 在扩容的时候会保持链表元素原本的顺序, 避免了链表成环的问题, 但是改完以后 HashMap 依然不能支持并发场景. (不过 HashMap 本来也不是为多线程而生的呀)
3. 链表和红黑树的转化
当链表长度大于阈值的时候, 并且哈希桶的数量大于 64 (MIN_TREEIFY_CAPACITY = 64), 就会将这个链表转化为红黑树, 链表转化为红黑树的默认阈值为 8, 如果红黑树的节点个数减少到一定程度也会转化为链表, 这是出于时间和空间的折中方案, 默认会在节点个数减少到 6 的时候进行转化.
4. 默认红黑树转化阈值的选择
上面所讲的阈值为什么选择 8 和 6 呢? 根据泊松分布, 在负载因子为 0.75 (HashMap 的默认值) 的时候, 单个 hash 槽内元素个数为 8 的概率小于百万分之一, 所以将 7 作为一个分水岭, 等于 7 的时候不进行转化, 大于等于 8 时转化为红黑树, 小于等于 6 的时候再转化为链表.
5. hash值的计算
通过阅读源码, 我们可以发现它是通过 (h = key.hashCode()) ^ (h >>> 16) 来计算 hash 值, 混合了 key 哈希值的高 16 位和低 16 位.
6. 扩容机制
HashMap 的默认容量 (其实就是拉链式中数组的长度) 为 16, 每次扩容都会变为原来的 2 倍, 并保证容量为 2 的幂次, 如果在构造函数或者扩容的时候给定一个不是 2 的幂次的数, 它会自动向上扩展到一个 2 的幂次.
7. 为什么 HashMap 的容量要保证是 2 的幂次?
- 由于使用拉链式的存储方式, 当 put 一个数据的时候, 需要对数组的长度取模确定数据在数组中的位置, 取模过程相对耗时, 因此需要优化取模运算. 当数组长度为 2 的幂次的时候,
hash % len等价于hash & (len - 1), 与运算相对取模运算更快. - 在满足容量为 2 的幂次的时候,
(len - 1)的所有二进制位都为 1, 这种情况下, 只需要保证 hash 算法的结果是均匀分布的, 那么 HashMap 中各元素一定是均匀分布的. - HashMap 中有个字段
threshold, 源码注解中写着The next size value at which to resize (capacity * load factor), 表示它用来判断下次什么时候扩容的字段. 当数组发生扩容时, 只需要再比较 1 bit 即可确定这个节点是否需要移动, 要么不动, 要么移动原来的数组长度.
8. 为什么 HashMap 的默认容量是 16 呢?
这应该是一个经验值, 要保证容量为 2 的幂次, 并且需要在效率和空间上做一个权衡, 太大浪费空间, 太小需要频繁扩容.
HashMap 与 Hashtable 的区别
| 集合 | 线程安全性 | 效率 | 默认容量 | 扩容方式 | 底层结构 | 实现方式 | 是否支持null值 | 迭代器 |
|---|---|---|---|---|---|---|---|---|
| HashMap | 不安全 | 高 | 16 | 2n (保证是2的幂次) | 数组+链表+红黑树 | 继承AbstractMap类 | Key允许存在一个null, Value可以为null | Fail-fast 机制 |
| Hashtable | 安全 | 低 | 11 | 2n+1 | 数组+链表 | 继承Dictionary类 | Key和Value都不能为null | Enumerator |
1. 线程安全性和效率
首先 HashMap 本来就不是针对多线程情况而设计的, Hashtable 是遗留类, 它内部使用 synchronzied 来修饰方式, 使得它能够成为一个同步集合, 但这种方式效率比较低.
我们可以通过两种方式来获得同步的 HashMap.
- 第一种是使用
Collentions.synchronizedMap(Map<K,V> m)来将一个非同步 Map 变为同步 Map. 这种方式的原理比较简单, 与 Hashtable 类似, 它会把传入的 map 对象作为 mutex 互斥锁对象, 然后在方法里都加上synchronized(mutex)的同步. - 第二种是使用
java.util.concurrent包下的同步集合ConcurrentHashMap, 这个集合将在下面详细介绍.
2. 对于 null 的支持和迭代器的差异
/* HashMap 中计算 hash 值的过程 */
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
/* Hashtable 中 put 的部分源码 */
public synchronized V put(K key, V value) {
// Make sure the value is not null
if (value == null) {
throw new NullPointerException();
}
// Makes sure the key is not already in the hashtable.
Entry<?,?> tab[] = table;
int hash = key.hashCode();
int index = (hash & 0x7FFFFFFF) % tab.length;
...
}
首先从源码上看, Hashtable 在 put 值为 null 的 key 或者 value 时候会抛出 NullPointerException, 但是 HashMap 对值为 null 的 key 做了特殊处理. 看似很简单的处理, 那这么处理的内在原因是什么呢?
Hashtable 的迭代器使用了安全失败机制 (fail-safe), 这种机制在遍历元素的时候, 先复制原有集合内容, 在拷贝的集合上进行遍历, 这会使得每次读取到的数据并不一定是最新数据. 如果可以使用 null 值, 将会无法判断对应的 key 是不存在还是为空. ConrrentHashMap 也是同样的道理.
HashMap 则是使用安全失败机制 (fail-fast), 这种机制是指在用迭代器遍历一个集合对象的时候, 如果遍历过程中对集合对象的内容进行了修改, 则会抛出 Concurrent Modification Exception. 通过阅读源码, 我们可以发现这种机制使用了 modCount 变量, 每次遍历下个元素的时候, 都会检查 modCount 变量的值是否发生改变, 如果发生改变就会抛出异常. 我们不能依赖这个异常是否抛出来进行并发控制, 这个异常只建议用于检测并发修改的 bug.
java.util 包下的集合 (除了同步容器: Hashtable, Vector 等) 都是 fail-fast, 而 java.util.concurrent 包下的集合和 java.util 包下的同步集合都是 fail-safe.
ConcurrentHashMap 与 Hashtable 的区别
1. 底层结构
ConcurrentHashMap 的底层结构与 HashMap 类似, 使用了数组+链表+红黑树, 而 Hashtable 使用了数组+链表.
2. 实现线程安全的方式
它们都是线程安全的, 但它们实现线程安全的方式不一样.
- Hashtable 使用同一个对象锁, 用 synchronized 来保证线程安全.

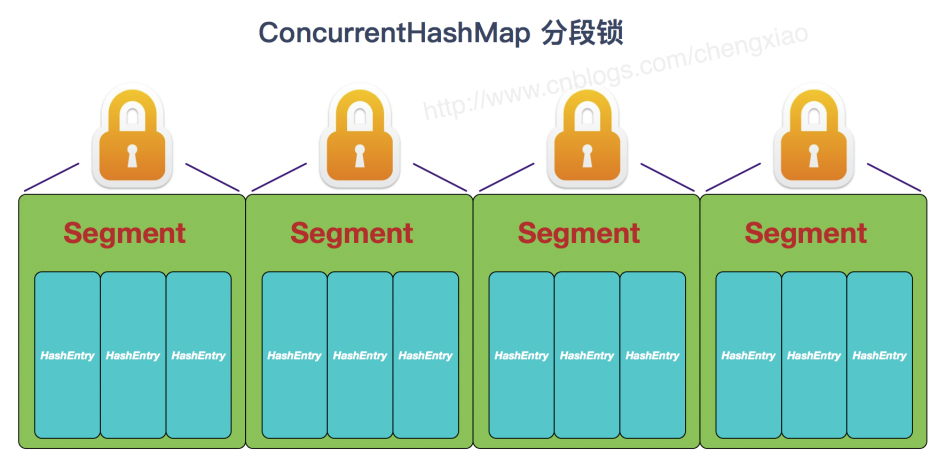
- ConcurrentHashMap 在 JDK1.7 中使用分段锁, 对整个数组进行分割来分段, 每把锁只锁定一部分数据, 多线程可以访问不同的数据段. Segment 锁继承了 ReentrantLock, 是一种可重入锁, 获取锁时先尝试自旋获取锁, 达到最大自旋次数后改为阻塞方式获取锁, 保证能够获取成功.

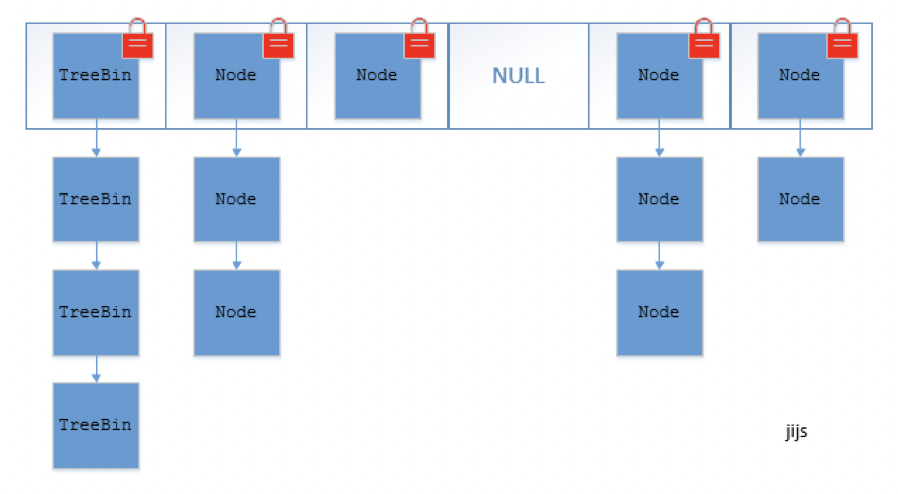
- ConcurrentHashMap 在 JDK1.8 中不再使用分段 (Segment) 的概念, 直接用 Node 数组+链表+红黑树来实现, 使用 CAS + synchronized 来进行并发控制. sychronized 只锁定当前链表或红黑树的头节点, 只要 hash 不冲突就不会有并发问题.
其他知识点
1. HashMap 与 LinkedHashMap 的区别
LinkedHashMap 继承自 HashMap, 底层结构与 HashMap 一致, 主要区别是 LinkedHashMap 维护了一个双向链表, 记录了插入数据的顺序. LinkedHashMap 十分适合用来实现 LRU 算法, LRU 算法主要利用了双向链表和 HashMap, 这简直就是量身打造, 要是手撕代码题用 LinkedHashMap 简直是作弊, 一般面试官不会让你这么干的
最新文章
- MWeb 1.5 发布!增加打字机滚动模式、发布到 Evernote、印象笔记、Wordpress.com、Blogger、编辑器内代码块语法高亮
- C++构造函数与析构函数
- Perl 语法 - 高级特性
- template_20_实现智能指针
- JAVA之经典Student问题1
- Asp.net MVC中的ViewData与ViewBag
- Spring 创建bean的时机
- php代码查询apache模块
- 实现一个宽和高都是100像素的div可以用鼠标拖拽移动的效果
- Spreadsheets
- 在程序中用new ClassPathXmlApplicationContext()的注意事项
- Autotest添加测试用例小结
- omitting directory `folder/'
- JavaScript学习-1
- Spring Boot(十六):使用Jenkins部署Spring Boot
- 【BZOJ-3532】Lis 最小割 + 退流
- EF6+MVC5之Oracleo数据库的CodeFirst方式实现
- VS Code 配置 C/C++ 环境
- 修改Nginx与Apache配置参数解决http状态码:413上传文件大小限制问题
- Java中this与super