2、flink入门程序Wordcount和sql实现
2024-10-08 22:29:51
一、DataStream Wordcount
基于scala实现
maven依赖如下:
<dependencies>
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>2.11.8</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
<version>1.7.7</version>
</dependency>
<dependency>
<groupId>log4j</groupId>
<artifactId>log4j</artifactId>
<version>1.2.17</version>
</dependency>
<!-- flink的hadoop兼容 -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-shaded-hadoop2</artifactId>
<version>1.7.2</version>
</dependency>
<!-- flink的hadoop兼容 -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-hadoop-compatibility_2.11</artifactId>
<version>${flink.version}</version>
</dependency>
<!-- flink的scala的api -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-scala_2.11</artifactId>
<version>${flink.version}</version>
</dependency>
<!-- flink streaming的scala的api -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-scala_2.11</artifactId>
<version>${flink.version}</version>
</dependency>
<!-- flink的java的api -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>${flink.version}</version>
</dependency>
<!-- flink streaming的java的api -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java_2.11</artifactId>
<version>${flink.version}</version>
</dependency>
<!-- flink 的kafkaconnector -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka-0.10_2.11</artifactId>
<version>${flink.version}</version>
</dependency>
<!-- 使用rocksdb保存flink的state -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-statebackend-rocksdb_2.11</artifactId>
<version>${flink.version}</version>
</dependency>
<!-- flink操作hbase -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-hbase_2.11</artifactId>
<version>${flink.version}</version>
</dependency>
<!-- flink运行时的webUI -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-runtime-web_2.11</artifactId>
<version>${flink.version}</version>
</dependency>
<!-- flink table -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-api-java-bridge_2.11</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-api-scala-bridge_2.11</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-planner_2.11</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-planner-blink_2.11</artifactId>
<version>${flink.version}</version>
</dependency>
<!-- mysql连接驱动 -->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.35</version>
</dependency>
</dependencies>
具体代码如下:
import org.apache.flink.api.common.functions.FlatMapFunction
import org.apache.flink.configuration.{ConfigConstants, Configuration}
import org.apache.flink.streaming.api.scala.{DataStream, StreamExecutionEnvironment}
import org.apache.flink.util.Collector object SocketWordCount {
def main(args: Array[String]): Unit = {
val logPath: String = "/tmp/logs/flink_log" // 生成配置对象
var conf: Configuration = new Configuration()
// 开启flink web UI
conf.setBoolean(ConfigConstants.LOCAL_START_WEBSERVER, true)
// 配置web UI的日志文件,否则打印日志到控制台
conf.setString("web.log.path", logPath)
// 配置taskManager的日志文件,否则打印到控制台
conf.setString(ConfigConstants.TASK_MANAGER_LOG_PATH_KEY, logPath)
// 获取local运行环境
val env: StreamExecutionEnvironment = StreamExecutionEnvironment.createLocalEnvironmentWithWebUI(conf)
// 定义socket 源
val socket: DataStream[String] = env.socketTextStream("localhost", 6666)
//scala开发需要加一行隐式转换,否则在调用operator的时候会报错
import org.apache.flink.api.scala._
// 定义 operators 解析数据,求Wordcount
val wordCount: DataStream[(String, Int)] = socket.flatMap(_.split(" ")).map((_, 1)).keyBy(_._1).sum(1)
//使用FlatMapFunction自定义函数来完成flatMap和map的组合功能
val wordCount2: DataStream[(String, Int)] = socket.flatMap(new FlatMapFunction[String, (String, Int)] {
override def flatMap(int: String, out: Collector[(String, Int)]): Unit = {
val strings: Array[String] = int.split(" ")
for (str <- strings) {
out.collect((str, 1))
}
}
}).setParallelism(2)
.keyBy(_._1).sum(1).setParallelism(2) // 打印结果
wordCount.print() // 定义任务的名称并运行,operator是惰性的,只有遇到execute才运行
env.execute("SocketWordCount")
}
}
二、flink table & sql Wordcount
import org.apache.flink.api.scala.{ExecutionEnvironment, _}
import org.apache.flink.configuration.{ConfigConstants, Configuration}
import org.apache.flink.table.api.Table
import org.apache.flink.table.api.scala.BatchTableEnvironment
import scala.collection.mutable.ArrayBuffer
/**
* @author xiandongxie
*/
object WordCountSql extends App {
val logPath: String = "/tmp/logs/flink_log"
// 生成配置对象
var conf: Configuration = new Configuration()
// 开启flink web UI
conf.setBoolean(ConfigConstants.LOCAL_START_WEBSERVER, true)
// 配置web UI的日志文件,否则打印日志到控制台
conf.setString("web.log.path", logPath)
// 配置taskManager的日志文件,否则打印到控制台
conf.setString(ConfigConstants.TASK_MANAGER_LOG_PATH_KEY, logPath)
// 获取local运行环境
val env: ExecutionEnvironment = ExecutionEnvironment.createLocalEnvironmentWithWebUI(conf)
//创建一个tableEnvironment
val tableEnv: BatchTableEnvironment = BatchTableEnvironment.create(env)
val words: String = "hello flink hello xxd"
val strings: Array[String] = words.split("\\W+")
val arrayBuffer = new ArrayBuffer[WordCount]()
for (f <- strings) {
arrayBuffer.append(new WordCount(f, 1))
}
val dataSet: DataSet[WordCount] = env.fromCollection(arrayBuffer)
//DataSet 转sql
val table: Table = tableEnv.fromDataSet(dataSet)
table.printSchema()
// 注册为一个表
tableEnv.createTemporaryView("WordCount", table)
// 查询
val selectTable: Table = tableEnv.sqlQuery("select word as word, sum(frequency) as frequency from WordCount GROUP BY word")
// 查询结果转为dataset,输出
val value: DataSet[WordCount] = tableEnv.toDataSet[WordCount](selectTable)
value.print()
}
/**
* 样例类
* @param word
* @param frequency
*/
case class WordCount(word: String, frequency: Long) {
override def toString: String = {
word + "\t" + frequency
}
}
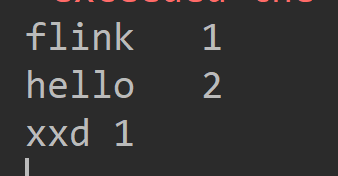
结果:
最新文章
- (备忘)自定义viewgroup与点击分发事件
- angular初步认识一
- 【OSG学习笔记之一:】OSG+VS2010+win7 64位环境搭建
- C++/CLI——读书笔记《Visual C++/CLI从入门到精通》 第Ⅳ部分
- window.navigate 与 window.location.href 的使用区别介绍
- 求s=a+aa+aaa+aaaa+aa...a的值,其中a是一个数字。例如2+22+222+2222+22222(此时共有5个数相加),几个数相加有键盘控制。
- 堆表和%%lockres%%函数
- Python 同时for遍历多个列表
- RESTFul中的那些事(1)---在RESTFul中,HTTP Put和Patch操作的差别?
- 【android】adb连接几个常见问题(遇到再新增)
- [hdu5136]Yue Fei's Battle 2014 亚洲区域赛广州赛区J题(dp)
- mysql错误号码:1129
- 网易云课堂_C语言程序设计进阶_第8周:图形交互程序
- Linux 多线程通信
- Misra-Gries 算法
- 【Ural1277】 Cops and Thieves 无向图点连通度问题
- [HDU5969] 最大的位或
- Cannot forward to error page for request ......
- JavaEE进阶——全文检索之Solr7.4服务器
- TensorFlow常用API汇总