消息队列扫盲(RocketMQ 入门)
消息队列扫盲
消息队列顾名思义就是存放消息的队列,队列我就不解释了,别告诉我你连队列都不知道似啥吧?
所以问题并不是消息队列是什么,而是 消息队列为什么会出现?消息队列能用来干什么?用它来干这些事会带来什么好处?消息队列会带来副作用吗?
消息队列为什么会出现?
消息队列算是作为后端程序员的一个必备技能吧,因为分布式应用必定涉及到各个系统之间的通信问题,这个时候消息队列也应运而生了。可以说分布式的产生是消息队列的基础,而分布式怕是一个很古老的概念了吧,所以消息队列也是一个很古老的中间件了。
消息队列能用来干什么?
异步
你可能会反驳我,应用之间的通信又不是只能由消息队列解决,好好的通信为什么中间非要插一个消息队列呢?我不能直接进行通信吗?
很好,你又提出了一个概念,同步通信。就比如现在业界使用比较多的 Dubbo 就是一个适用于各个系统之间同步通信的 RPC 框架。
我来举个吧,比如我们有一个购票系统,需求是用户在购买完之后能接收到购买完成的短信。
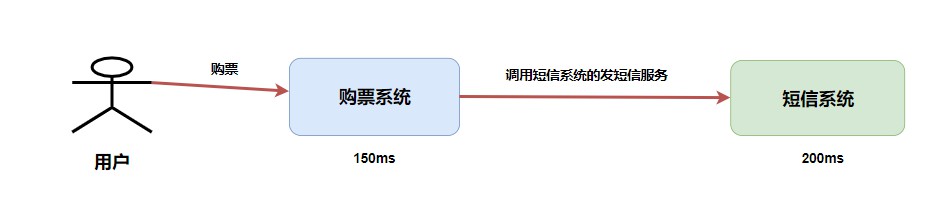
我们省略中间的网络通信时间消耗,假如购票系统处理需要 150ms ,短信系统处理需要 200ms ,那么整个处理流程的时间消耗就是 150ms + 200ms = 350ms。
当然,乍看没什么问题。可是仔细一想你就感觉有点问题,我用户购票在购票系统的时候其实就已经完成了购买,而我现在通过同步调用非要让整个请求拉长时间,而短息系统这玩意又不是很有必要,它仅仅是一个辅助功能增强用户体验感而已。我现在整个调用流程就有点 头重脚轻 的感觉了,购票是一个不太耗时的流程,而我现在因为同步调用,非要等待发送短信这个比较耗时的操作才返回结果。那我如果再加一个发送邮件呢?

这样整个系统的调用链又变长了,整个时间就变成了550ms。
当我们在学生时代需要在食堂排队的时候,我们和食堂大妈就是一个同步的模型。
我们需要告诉食堂大妈:“姐姐,给我加个鸡腿,再加个酸辣土豆丝,帮我浇点汁上去,多打点饭哦” 咦~~~~~ 为了多吃点,真恶心。
然后大妈帮我们打饭配菜,我们看着大妈那颤抖的手和掉落的土豆丝不禁咽了咽口水。
最终我们从大妈手中接过饭菜然后去寻找座位了...
回想一下,我们在给大妈发送需要的信息之后我们是 同步等待大妈给我配好饭菜 的,上面我们只是加了鸡腿和土豆丝,万一我再加一个番茄牛腩,韭菜鸡蛋,这样是不是大妈打饭配菜的流程就会变长,我们等待的时间也会相应的变长。

那后来,我们工作赚钱了有钱去饭店吃饭了,我们告诉服务员来一碗牛肉面加个荷包蛋 (传达一个消息) ,然后我们就可以在饭桌上安心的玩手机了 (干自己其他事情) ,等到我们的牛肉面上了我们就可以吃了。这其中我们也就传达了一个消息,然后我们又转过头干其他事情了。这其中虽然做面的时间没有变短,但是我们只需要传达一个消息就可以看其他事情了,这是一个 异步 的概念。
所以,为了解决这一个问题,聪明的程序员在中间也加了个类似于服务员的中间件——消息队列。这个时候我们就可以把模型给改造了。
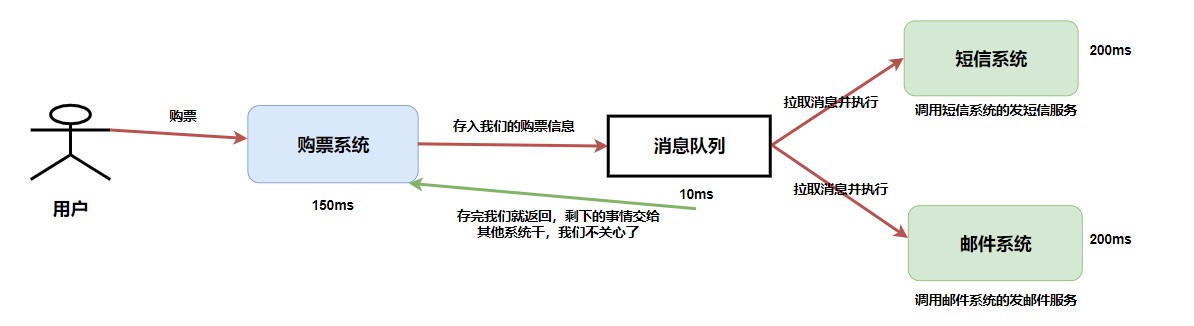
这样,我们在将消息存入消息队列之后我们就可以直接返回了(我们告诉服务员我们要吃什么然后玩手机),所以整个耗时只是 150ms + 10ms = 160ms。
但是你需要注意的是,整个流程的时长是没变的,就像你仅仅告诉服务员要吃什么是不会影响到做面的速度的。
解耦
回到最初同步调用的过程,我们写个伪代码简单概括一下。
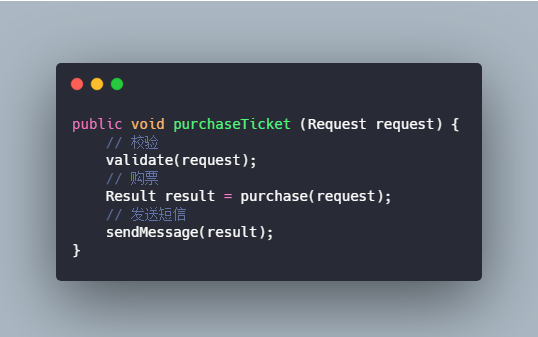
那么第二步,我们又添加了一个发送邮件,我们就得重新去修改代码,如果我们又加一个需求:用户购买完还需要给他加积分,这个时候我们是不是又得改代码?

如果你觉得还行,那么我这个时候不要发邮件这个服务了呢,我是不是又得改代码,又得重启应用?

这样改来改去是不是很麻烦,那么 此时我们就用一个消息队列在中间进行解耦 。你需要注意的是,我们后面的发送短信、发送邮件、添加积分等一些操作都依赖于上面的 result ,这东西抽象出来就是购票的处理结果呀,比如订单号,用户账号等等,也就是说我们后面的一系列服务都是需要同样的消息来进行处理。既然这样,我们是不是可以通过 “广播消息” 来实现。
我上面所讲的“广播”并不是真正的广播,而是接下来的系统作为消费者去 订阅 特定的主题。比如我们这里的主题就可以叫做 订票 ,我们购买系统作为一个生产者去生产这条消息放入消息队列,然后消费者订阅了这个主题,会从消息队列中拉取消息并消费。就比如我们刚刚画的那张图,你会发现,在生产者这边我们只需要关注 生产消息到指定主题中 ,而 消费者只需要关注从指定主题中拉取消息 就行了。
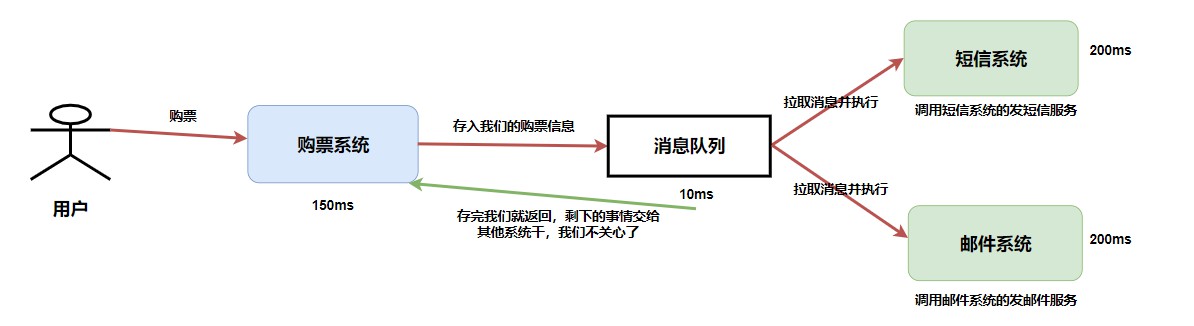
如果没有消息队列,每当一个新的业务接入,我们都要在主系统调用新接口、或者当我们取消某些业务,我们也得在主系统删除某些接口调用。有了消息队列,我们只需要关心消息是否送达了队列,至于谁希望订阅,接下来收到消息如何处理,是下游的事情,无疑极大地减少了开发和联调的工作量。
削峰
我们再次回到一开始我们使用同步调用系统的情况,并且思考一下,如果此时有大量用户请求购票整个系统会变成什么样?
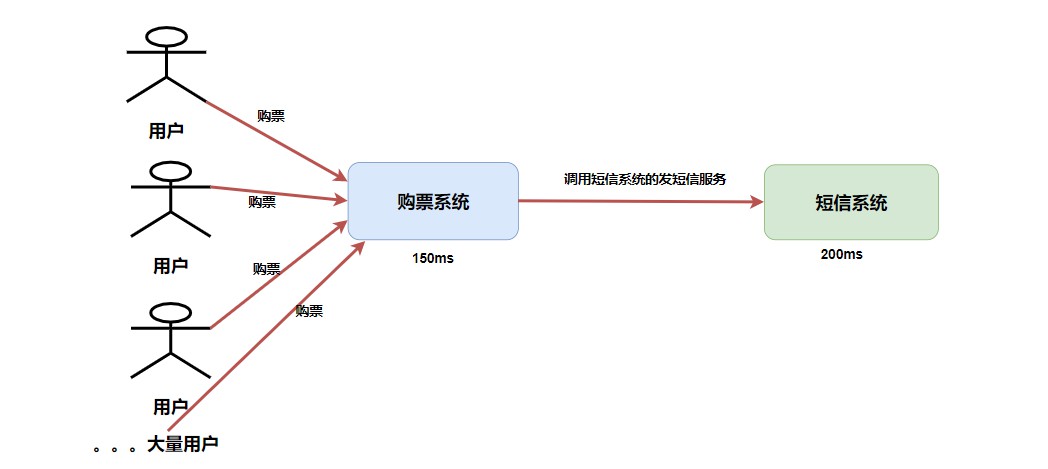
如果,此时有一万的请求进入购票系统,我们知道运行我们主业务的服务器配置一般会比较好,所以这里我们假设购票系统能承受这一万的用户请求,那么也就意味着我们同时也会出现一万调用发短信服务的请求。而对于短信系统来说并不是我们的主要业务,所以我们配备的硬件资源并不会太高,那么你觉得现在这个短信系统能承受这一万的峰值么,且不说能不能承受,系统会不会 直接崩溃 了?
短信业务又不是我们的主业务,我们能不能 折中处理 呢?如果我们把购买完成的信息发送到消息队列中,而短信系统 尽自己所能地去消息队列中取消息和消费消息 ,即使处理速度慢一点也无所谓,只要我们的系统没有崩溃就行了。
留得江山在,还怕没柴烧?你敢说每次发送验证码的时候是一发你就收到了的么?
消息队列能带来什么好处?
其实上面我已经说了。异步、解耦、削峰。 哪怕你上面的都没看懂也千万要记住这六个字,因为他不仅是消息队列的精华,更是编程和架构的精华。
消息队列会带来副作用吗?
没有哪一门技术是“银弹”,消息队列也有它的副作用。
比如,本来好好的两个系统之间的调用,我中间加了个消息队列,如果消息队列挂了怎么办呢?是不是 降低了系统的可用性 ?
那这样是不是要保证HA(高可用)?是不是要搞集群?那么我 整个系统的复杂度是不是上升了 ?
抛开上面的问题不讲,万一我发送方发送失败了,然后执行重试,这样就可能产生重复的消息。
或者我消费端处理失败了,请求重发,这样也会产生重复的消息。
对于一些微服务来说,消费重复消息会带来更大的麻烦,比如增加积分,这个时候我加了多次是不是对其他用户不公平?
那么,又 如何解决重复消费消息的问题 呢?
如果我们此时的消息需要保证严格的顺序性怎么办呢?比如生产者生产了一系列的有序消息(对一个id为1的记录进行删除增加修改),但是我们知道在发布订阅模型中,对于主题是无顺序的,那么这个时候就会导致对于消费者消费消息的时候没有按照生产者的发送顺序消费,比如这个时候我们消费的顺序为修改删除增加,如果该记录涉及到金额的话是不是会出大事情?
那么,又 如何解决消息的顺序消费问题 呢?
就拿我们上面所讲的分布式系统来说,用户购票完成之后是不是需要增加账户积分?在同一个系统中我们一般会使用事务来进行解决,如果用 Spring 的话我们在上面伪代码中加入 @Transactional 注解就好了。但是在不同系统中如何保证事务呢?总不能这个系统我扣钱成功了你那积分系统积分没加吧?或者说我这扣钱明明失败了,你那积分系统给我加了积分。
那么,又如何 解决分布式事务问题 呢?
我们刚刚说了,消息队列可以进行削峰操作,那如果我的消费者如果消费很慢或者生产者生产消息很快,这样是不是会将消息堆积在消息队列中?
那么,又如何 解决消息堆积的问题 呢?
可用性降低,复杂度上升,又带来一系列的重复消费,顺序消费,分布式事务,消息堆积的问题,这消息队列还怎么用啊?

别急,办法总是有的。
RocketMQ是什么?

哇,你个混蛋!上面给我抛出那么多问题,你现在又讲 RocketMQ ,还让不让人活了?!
别急别急,话说你现在清楚 MQ 的构造吗,我还没讲呢,我们先搞明白 MQ 的内部构造,再来看看如何解决上面的一系列问题吧,不过你最好带着问题去阅读和了解喔。
RocketMQ 是一个 队列模型 的消息中间件,具有高性能、高可靠、高实时、分布式 的特点。它是一个采用 Java 语言开发的分布式的消息系统,由阿里巴巴团队开发,在2016年底贡献给 Apache,成为了 Apache 的一个顶级项目。 在阿里内部,RocketMQ 很好地服务了集团大大小小上千个应用,在每年的双十一当天,更有不可思议的万亿级消息通过 RocketMQ 流转。
废话不多说,想要了解 RocketMQ 历史的同学可以自己去搜寻资料。听完上面的介绍,你只要知道 RocketMQ 很快、很牛、而且经历过双十一的实践就行了!
队列模型和主题模型
在谈 RocketMQ 的技术架构之前,我们先来了解一下两个名词概念——队列模型 和 主题模型 。
首先我问一个问题,消息队列为什么要叫消息队列?
你可能觉得很弱智,这玩意不就是存放消息的队列嘛?不叫消息队列叫什么?
的确,早期的消息中间件是通过 队列 这一模型来实现的,可能是历史原因,我们都习惯把消息中间件成为消息队列。
但是,如今例如 RocketMQ 、Kafka 这些优秀的消息中间件不仅仅是通过一个 队列 来实现消息存储的。
队列模型
就像我们理解队列一样,消息中间件的队列模型就真的只是一个队列。。。我画一张图给大家理解。

在一开始我跟你提到了一个 “广播” 的概念,也就是说如果我们此时我们需要将一个消息发送给多个消费者(比如此时我需要将信息发送给短信系统和邮件系统),这个时候单个队列即不能满足需求了。
当然你可以让 Producer 生产消息放入多个队列中,然后每个队列去对应每一个消费者。问题是可以解决,创建多个队列并且复制多份消息是会很影响资源和性能的。而且,这样子就会导致生产者需要知道具体消费者个数然后去复制对应数量的消息队列,这就违背我们消息中间件的 解耦 这一原则。
主题模型
那么有没有好的方法去解决这一个问题呢?有,那就是 主题模型 或者可以称为 发布订阅模型 。
感兴趣的同学可以去了解一下设计模式里面的观察者模式并且手动实现一下,我相信你会有所收获的。
在主题模型中,消息的生产者称为 发布者(Publisher) ,消息的消费者称为 订阅者(Subscriber) ,存放消息的容器称为 主题(Topic) 。
其中,发布者将消息发送到指定主题中,订阅者需要 提前订阅主题 才能接受特定主题的消息。
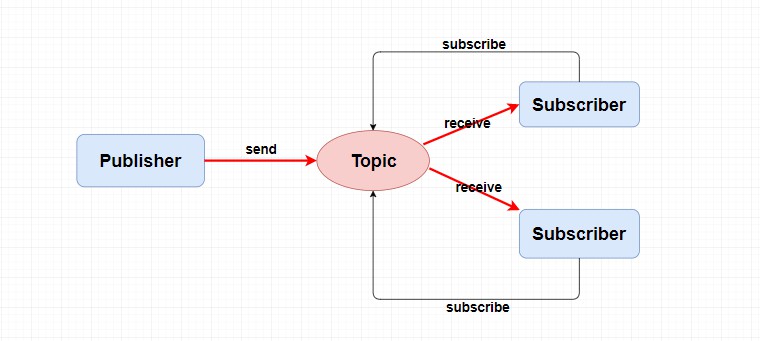
RocketMQ中的消息模型
RockerMQ 中的消息模型就是按照 主题模型 所实现的。你可能会好奇这个 主题 到底是怎么实现的呢?你上面也没有讲到呀!
其实对于主题模型的实现来说每个消息中间件的底层设计都是不一样的,就比如 Kafka 中的 分区 ,RocketMQ 中的 队列 ,RabbitMQ 中的 Exchange 。我们可以理解为 主题模型/发布订阅模型 就是一个标准,那些中间件只不过照着这个标准去实现而已。
所以,RocketMQ 中的 主题模型 到底是如何实现的呢?首先我画一张图,大家尝试着去理解一下。
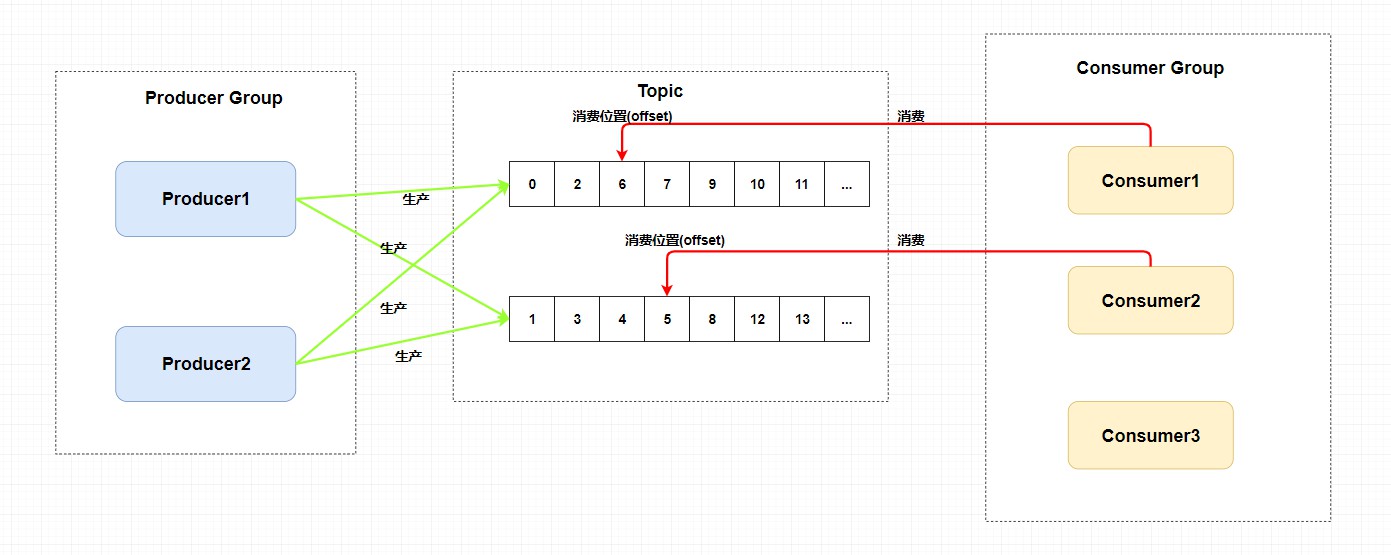
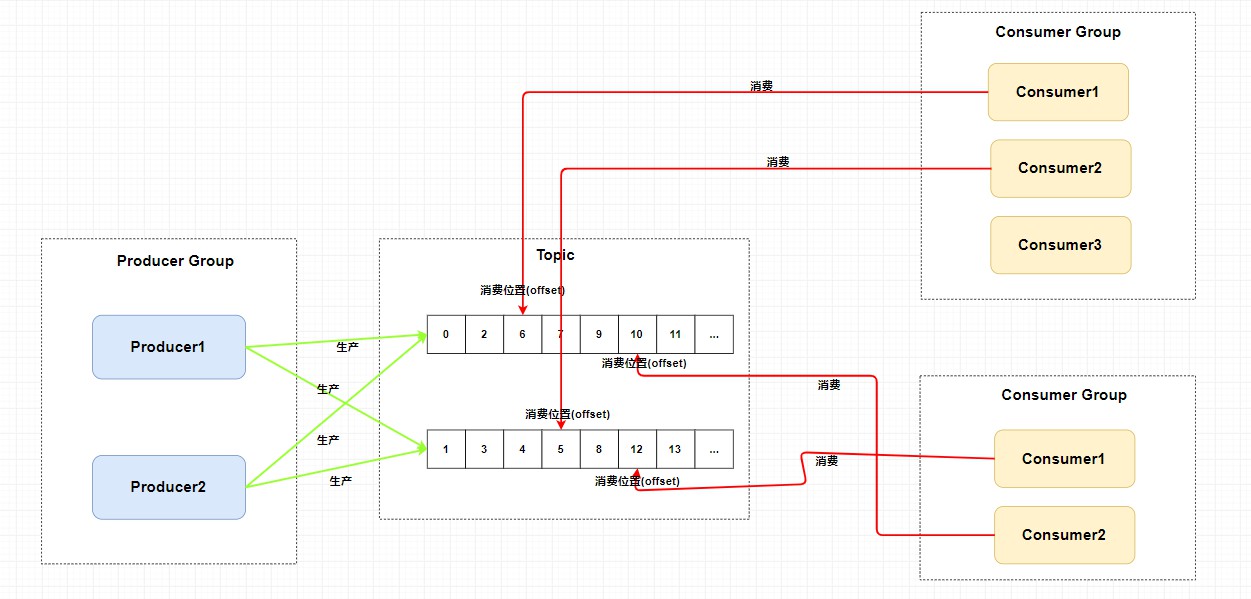
我们可以看到在整个图中有 Producer Group 、Topic 、Consumer Group 三个角色,我来分别介绍一下他们。
Producer Group生产者组: 代表某一类的生产者,比如我们有多个秒杀系统作为生产者,这多个合在一起就是一个Producer Group生产者组,它们一般生产相同的消息。Consumer Group消费者组: 代表某一类的消费者,比如我们有多个短信系统作为消费者,这多个合在一起就是一个Consumer Group消费者组,它们一般消费相同的消息。Topic主题: 代表一类消息,比如订单消息,物流消息等等。
你可以看到图中生产者组中的生产者会向主题发送消息,而 主题中存在多个队列,生产者每次生产消息之后是指定主题中的某个队列发送消息的。
每个主题中都有多个队列(这里还不涉及到 Broker),集群消费模式下,一个消费者集群多台机器共同消费一个 topic 的多个队列,一个队列只会被一个消费者消费。如果某个消费者挂掉,分组内其它消费者会接替挂掉的消费者继续消费。就像上图中 Consumer1 和 Consumer2 分别对应着两个队列,而 Consuer3 是没有队列对应的,所以一般来讲要控制 消费者组中的消费者个数和主题中队列个数相同 。
当然也可以消费者个数小于队列个数,只不过不太建议。如下图。
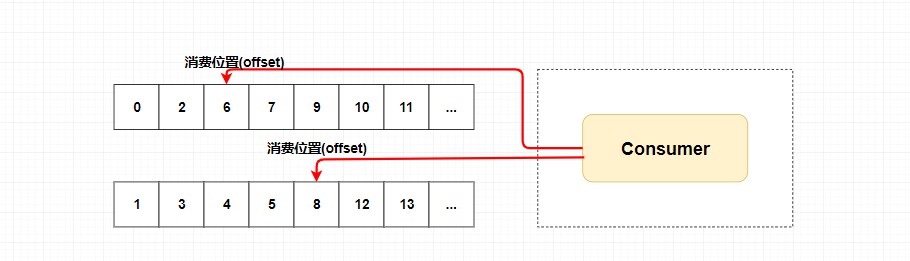
每个消费组在每个队列上维护一个消费位置 ,为什么呢?
因为我们刚刚画的仅仅是一个消费者组,我们知道在发布订阅模式中一般会涉及到多个消费者组,而每个消费者组在每个队列中的消费位置都是不同的。如果此时有多个消费者组,那么消息被一个消费者组消费完之后是不会删除的(因为其它消费者组也需要呀),它仅仅是为每个消费者组维护一个 消费位移(offset) ,每次消费者组消费完会返回一个成功的响应,然后队列再把维护的消费位移加一,这样就不会出现刚刚消费过的消息再一次被消费了。
可能你还有一个问题,为什么一个主题中需要维护多个队列 ?
答案是 提高并发能力 。的确,每个主题中只存在一个队列也是可行的。你想一下,如果每个主题中只存在一个队列,这个队列中也维护着每个消费者组的消费位置,这样也可以做到 发布订阅模式 。如下图。

但是,这样我生产者是不是只能向一个队列发送消息?又因为需要维护消费位置所以一个队列只能对应一个消费者组中的消费者,这样是不是其他的 Consumer 就没有用武之地了?从这两个角度来讲,并发度一下子就小了很多。
所以总结来说,RocketMQ 通过使用在一个 Topic 中配置多个队列并且每个队列维护每个消费者组的消费位置 实现了 主题模式/发布订阅模式 。
RocketMQ的架构图
讲完了消息模型,我们理解起 RocketMQ 的技术架构起来就容易多了。
RocketMQ 技术架构中有四大角色 NameServer 、Broker 、Producer 、Consumer 。我来向大家分别解释一下这四个角色是干啥的。
Broker: 主要负责消息的存储、投递和查询以及服务高可用保证。说白了就是消息队列服务器嘛,生产者生产消息到Broker,消费者从Broker拉取消息并消费。这里,我还得普及一下关于
Broker、Topic和 队列的关系。上面我讲解了Topic和队列的关系——一个Topic中存在多个队列,那么这个Topic和队列存放在哪呢?一个
Topic分布在多个Broker上,一个Broker可以配置多个Topic,它们是多对多的关系。如果某个
Topic消息量很大,应该给它多配置几个队列(上文中提到了提高并发能力),并且 尽量多分布在不同Broker上,以减轻某个Broker的压力 。Topic消息量都比较均匀的情况下,如果某个broker上的队列越多,则该broker压力越大。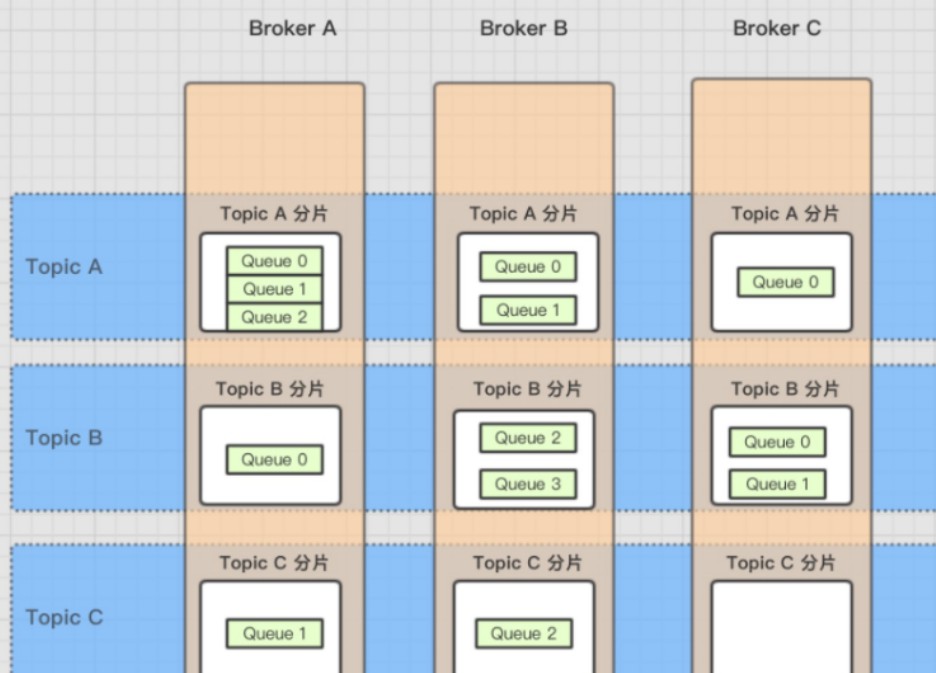
所以说我们需要配置多个Broker。
NameServer: 不知道你们有没有接触过ZooKeeper和Spring Cloud中的Eureka,它其实也是一个 注册中心 ,主要提供两个功能:Broker管理 和 路由信息管理 。说白了就是Broker会将自己的信息注册到NameServer中,此时NameServer就存放了很多Broker的信息(Broker的路由表),消费者和生产者就从NameServer中获取路由表然后照着路由表的信息和对应的Broker进行通信(生产者和消费者定期会向NameServer去查询相关的Broker的信息)。Producer: 消息发布的角色,支持分布式集群方式部署。说白了就是生产者。Consumer: 消息消费的角色,支持分布式集群方式部署。支持以push推,pull拉两种模式对消息进行消费。同时也支持集群方式和广播方式的消费,它提供实时消息订阅机制。说白了就是消费者。
听完了上面的解释你可能会觉得,这玩意好简单。不就是这样的么?
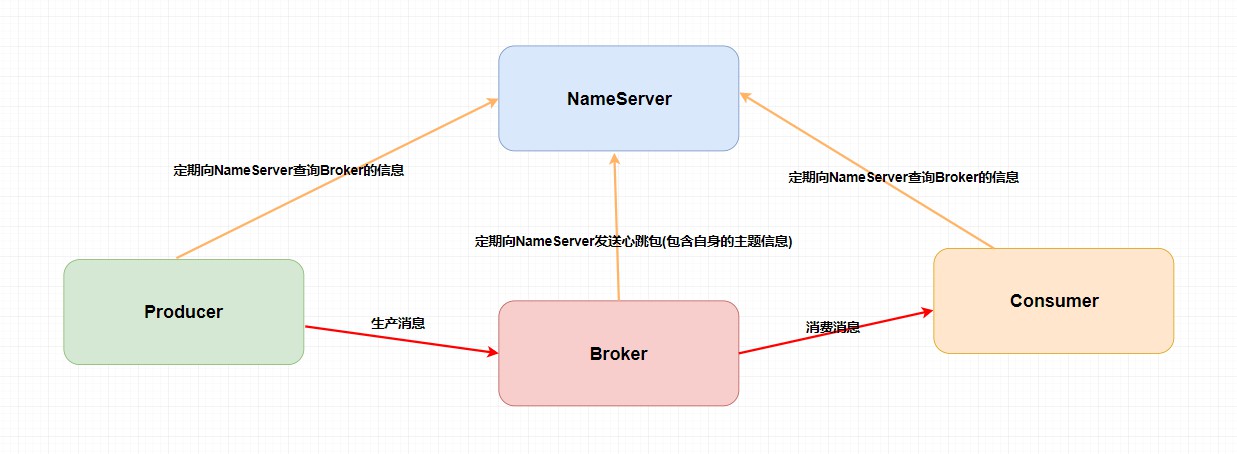
嗯?你可能会发现一个问题,这老家伙 NameServer 干啥用的,这不多余吗?直接 Producer 、Consumer 和 Broker 直接进行生产消息,消费消息不就好了么?
但是,我们上文提到过 Broker 是需要保证高可用的,如果整个系统仅仅靠着一个 Broker 来维持的话,那么这个 Broker 的压力会不会很大?所以我们需要使用多个 Broker 来保证 负载均衡 。
如果说,我们的消费者和生产者直接和多个 Broker 相连,那么当 Broker 修改的时候必定会牵连着每个生产者和消费者,这样就会产生耦合问题,而 NameServer 注册中心就是用来解决这个问题的。
如果还不是很理解的话,可以去看我介绍
Spring Cloud的那篇文章,其中介绍了Eureka注册中心。
当然,RocketMQ 中的技术架构肯定不止前面那么简单,因为上面图中的四个角色都是需要做集群的。我给出一张官网的架构图,大家尝试理解一下。
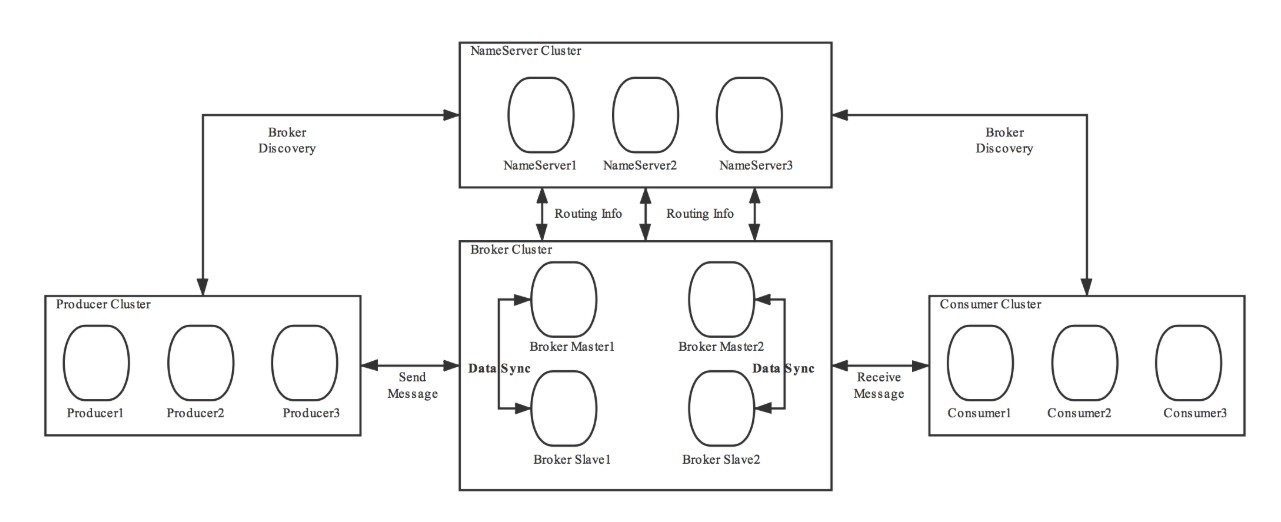
其实和我们最开始画的那张乞丐版的架构图也没什么区别,主要是一些细节上的差别。听我细细道来
最新文章
- 谁在关心toString的性能?
- NoClassDefFoundError vs ClassNotFoundException
- git merge git pull时候遇到冲突解决办法git stash
- javascript坐标:event.x、event.clientX、event.offsetX、event.screenX 用法
- SSL、TLS协议格式、HTTPS通信过程、RDP SSL通信过程
- 【WCF】Silverlight+wcf+自定义用户名密码验证
- 《高性能javascript》读书笔记
- Python中的SET集合操作
- 给你讲个笑话,我是创业公司CEO
- Android中的TextView实现多行显示省略号
- LeetCode219:Contains Duplicate II
- dplyr 数据操作 数据排序 (arrange)
- 关于SQL调优(Distinct 和 Exits)
- ArcGIS 网络分析[2.2] 服务区分析
- IE兼容事件绑定V1.0
- UUID的意义和作用
- Window服务与Quartz.NET
- winscp以命令行方式同步服务器数据到PC机磁盘上
- 使用oracle9的 odbc 连接oracle11
- cenos 安装hadoop