Spark-1.6.1 Hadoop-2.6.4 VMware Ubuntu 分布式集群搭建 全过程
本文从头开始零基础完全配置,适合小白。
本文在vmware中配置三台虚拟机,一台做Master,两台Worker,hadoop 和spark只需要在Master上配置,然后cp到worker上,包括配置文件。
Ubuntu基本环境配置
创建hadoop用户
在终端中输入
sudo useradd -m hadoop -s /bin/bash接着使用如下命令设置密码,可简单设置为 hadoop,按提示输入两次密码:
sudo passwd hadoop可为 hadoop 用户增加管理员权限,方便部署,避免一些对新手来说比较棘手的权限问题:
sudo adduser hadoop sudo最后注销当前用户(点击屏幕右上角的齿轮,选择注销),在登陆界面使用刚创建的 hadoop 用户进行登陆。这个很重要,一定要切换到hadoop用户,涉及到后面的配置。
安装vim
首先更新apt
sudo apt-get update因为后面要修改很多配置文件,有些用gedit比较方便,比如大块的copy,但在有些环境下vim更方便,有时也只能用vim,所以建议装。用的时候只要将gedit 和 vim互换即可。
sudo apt-get install vim中间输入y即可
以上过程需在所有节点上配置(本文是有一台Master ,两台worker)
网络配置
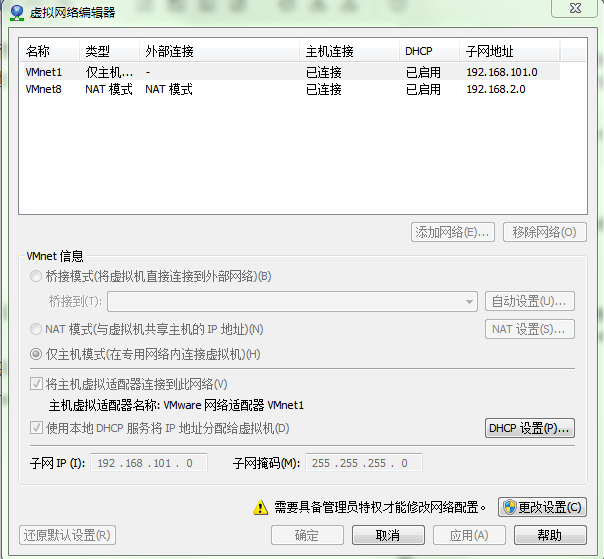
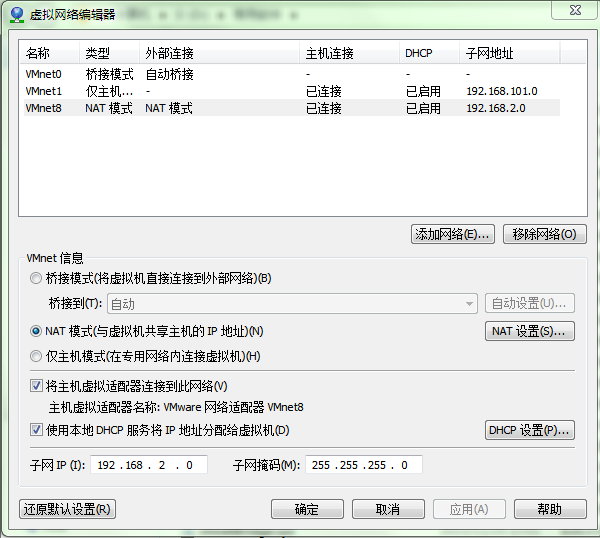
点击VMware快捷方式,右键打开文件所在位置 -> 双击vmnetcfg.exe -> VMnet8 NAT模式 ->修改subnet ip
点击更改设置
选中VMnet8
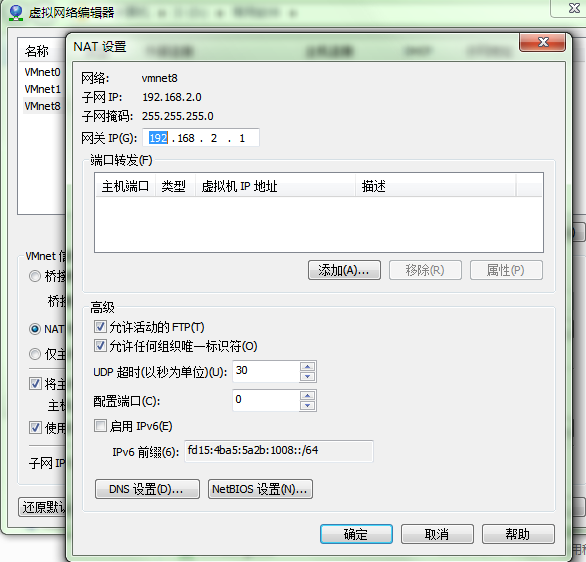
点击NAT设置
设置子网IP:192.168.2.0 子网掩码:255.255.255.0 -> apply(应用) -> ok(确定)。其实都可以,只要在同一网段内即可
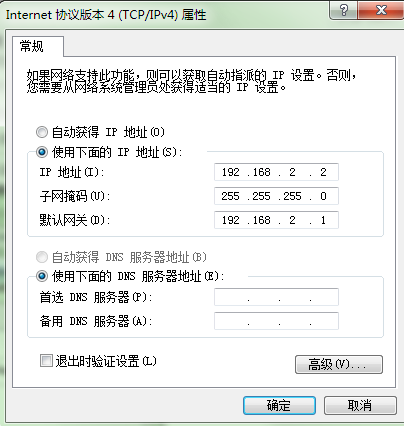
回到windows下检查 –> 打开网络和共享中心 -> 更改适配器设置 -> 右键VMnet8 -> 属性 -> 双击IPv4
192.168.2.2 在网段内,可以可以。
在虚拟软件上 –My Computer -> 选中虚拟机 -> 右键 -> settings -> (网络适配器)network adapter -> 选择VMnet8
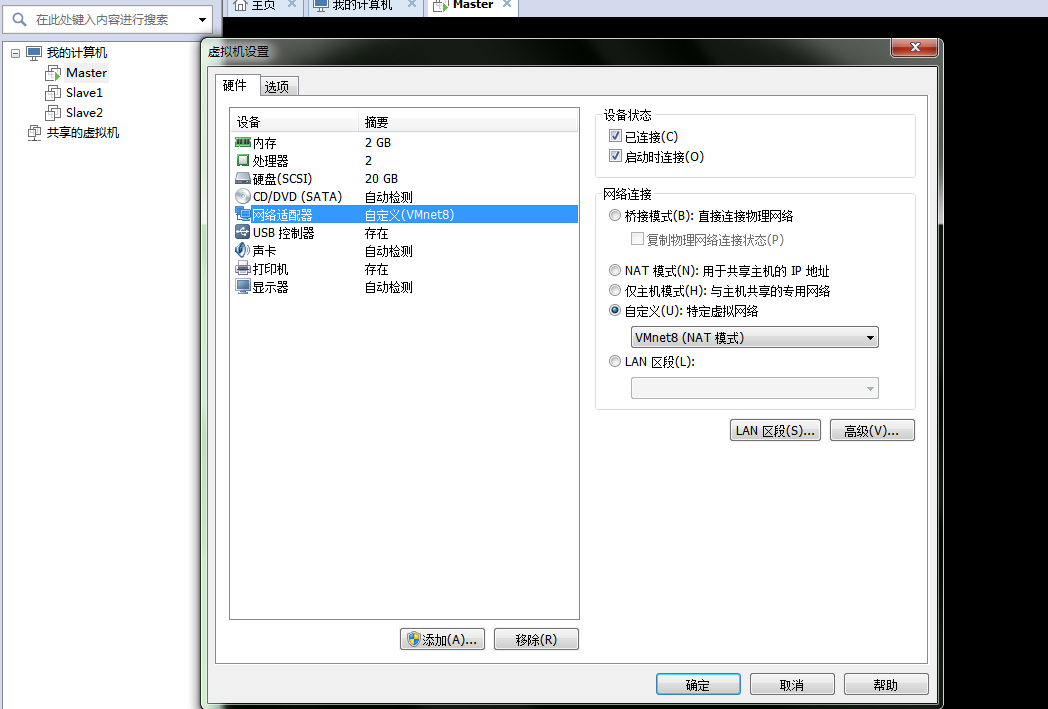
配置虚拟机IP地址
两种方式:
第一种:通过Linux图形界面进行修改(强烈推荐)
进入Linux图形界面 -> 右键点击右上方的两个小电脑 -> 点击Edit connections -> 选中当前网络 -> 点击edit按钮 -> 选择IPv4 -> method选择为manual -> 点击add按钮 -> 添加IP:192.168.2.100 子网掩码:255.255.255.0 网关:192.168.2.1 -> apply
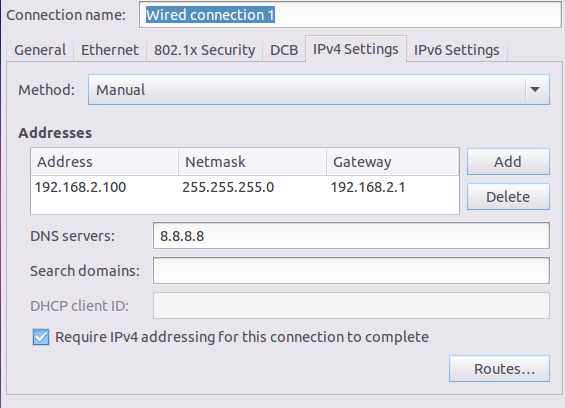
第二种:修改配置文件方式(屌丝程序猿专用)
vim /etc/sysconfig/network-scripts/ifcfg-eth0
DEVICE="eth0"
BOOTPROTO="static" ###
HWADDR="00:0C:29:3C:BF:E7"
IPV6INIT="yes"
NM_CONTROLLED="yes"
ONBOOT="yes"
TYPE="Ethernet"
UUID="ce22eeca-ecde-4536-8cc2-ef0dc36d4a8c"
IPADDR="192.168.2.100" ###
NETMASK="255.255.255.0" ###
GATEWAY="192.168.2.1" ###改完后 reboot
三台都需要修改, IP地址同网段不同即可
本文用的是
192.168.2.100 Master
192.168.2.101 Slave1
192.168.2.102 Slave2
Linux 中查看节点 IP 地址的命令为 ifconfig
修改主机名
为了便于区分,可以修改各个节点的主机名(在终端标题、命令行中可以看到主机名,以便区分)
sudo vim /etc/hostname按 i 进行 Insert 添加修改
添加Master即可,在其他两台机器上同样添加Slave1和Slave2即可。
保持并推出,先按esc,再按 :wq
命令修改自己所用节点的IP映射:
sudo vim /etc/hosts
127.0.0.1 localhost
192.168.2.100 Master
192.168.2.101 Slave1
192.168.2.102 Slave2配置好后需要在各个节点上执行如下命令,测试是否相互 ping 得通,如果 ping 不通,后面就无法顺利配置成功
ping Master -c 3 # 只ping 3次,否则要按 Ctrl+c 中断
ping Slave1 -c 3配置好后,所有机器都需要重启
SSH无密码登陆节点
首先安装SSH
sudo apt-get install openssh-server安装后,可以使用如下命令登陆本机:
ssh localhostSSH首次登陆会有提示,输入 yes 。然后按提示输入密码 hadoop,这样就登陆到本机了,但是每次都要输密码比较麻烦,因此需要配置无密码登录。
首先退出刚才的 ssh,就回到了我们原先的终端窗口,然后利用 ssh-keygen 生成密钥,并将密钥加入到授权中:
exit # 退出刚才的 ssh localhost
cd ~/.ssh/ # 若没有该目录,请先执行一次ssh localhost
ssh-keygen -t rsa # 会有提示,都按回车就可以
cat ./id_rsa.pub >> ./authorized_keys # 加入授权此时再用 ssh localhost 命令,无需输入密码就可以直接登陆了
对三台机器都进行上述操作
接下来设置无密码登录,让 Master 节点可以无密码 SSH 登陆到各个 Slave 节点上。
首先生成 Master 节点的公匙,在 Master 节点的终端中执行(因为改过主机名,所以还需要删掉原有的再重新生成一次):
cd ~/.ssh # 如果没有该目录,先执行一次ssh localhost
rm ./id_rsa* # 删除之前生成的公匙(如果有)
ssh-keygen -t rsa # 一直按回车就可以让 Master 节点需能无密码 SSH 本机,在 Master 节点上执行:
cat ./id_rsa.pub >> ./authorized_keys完成后可执行 ssh Master 验证一下(可能需要输入 yes,成功后执行 exit 返回原来的终端)。接着在 Master 节点将上公匙传输到 Slave1 节点:
scp ~/.ssh/id_rsa.pub hadoop@Slave1:/home/hadoop/这里解释下,scp 是 secure copy 的简写,用于在 Linux 下进行远程拷贝文件,类似于 cp 命令,不过 cp 只能在本机中拷贝。执行 scp 时会要求输入 Slave1 上 hadoop 用户的密码(hadoop)。因为是烤给 Slave1 机器的hadoop用户。
接着在 Slave1 节点上,将 ssh 公匙加入授权:
mkdir ~/.ssh # 如果不存在该文件夹需先创建,若已存在则忽略
cat ~/id_rsa.pub >> ~/.ssh/authorized_keys
rm ~/id_rsa.pub # 用完就可以删掉了对于Slave2也进行同样操作
在 Master 节点上就可以无密码 SSH 到各个 Slave 节点了,可在 Master 节点上执行如下命令进行检验
ssh Slave1
要推出,exit 即可。
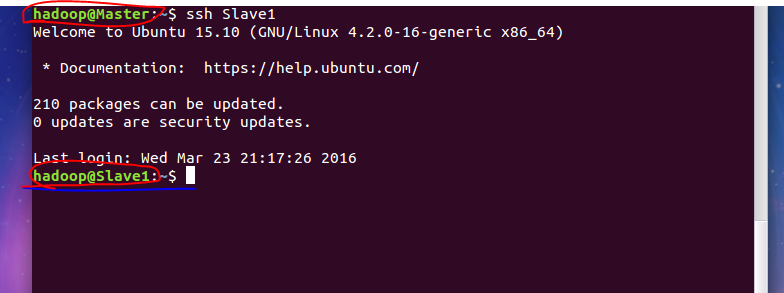
在这里,推荐使用一款工具SecureCRT, 可以方便的登录
具体使用,就不在这里讨论了。
关闭防火墙
1、关闭ubuntu的防火墙
ufw disable 2、卸载了iptables
apt-get remove iptables 安装Java
1.下载JDK
本次选择的是 jdk-8u73-linux-x64
放到Download目录, 当然随意看喜好
2.创建新目录
sudo mkdir /usr/local/java3.将下载到压缩包拷贝到java文件夹中
进入jdk源码包所在目录Download
解压压缩包,然后可以删除压缩包
cd Downloads
cp jdk-8u73-linux-x64.tar.gz /usr/local/java
cd /usr/local/java
sudo tar xvf jdk-8u73-linux-x64.tar.gz
sudo rm jdk-8u73-linux-x64.tar.gz4.设置jdk环境变量
sudo gedit ~/.bashrc添加
export JAVA_HOME=/usr/local/java/jdk1.8.0_73
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:$CLASSPATH:$JAVA_HOME/lib:$JRE_HOME/lib
export PATH=$PATH:$JAVA_HOME/bin:$JRE_HOME/bin然后
source ~/.bashrc让配置立即生效
5.最后检查是否生效
在终端输入
java -version安装Scala
Scala 安装与Java 类似
1_下载压缩包
http://www.scala-lang.org/download/
2_建立目录,解压文件到所建立目录
sudo mkdir /usr/local/scala
tar zxvf scala-2.11.7.tgz -C /usr/local/scala3_添加环境变量
sudo gedit ~/.bashrc添加
export SCALA_HOME=/usr/local/scala/scala-2.11.7
export PATH=/usr/local/scala/scala-2.11.7/bin:$PATH4.测试
scala -version
Scala code runner version 2.11.7 -- Copyright 2002-2013, LAMP/EPFL
让服务器启动时不要启动图形界面(Slaves节点 )
修改 /etc/X11/default-display-manager文件:
vim /etc/X11/default-display-manager一般为空,若为空,则添加false,:wq 保存推出
值为/usr/sbin/gdm,则进入图形界面
安装Hadoop
下载 hadoop http://hadoop.apache.org/releases.html
本文用的是 hadoop-2.6.4.tar.gz , 据说 2.6.0的比较稳定,比较好
将 Hadoop 安装至 /usr/local/ 中:
sudo tar -zxf ~/Downloads/hadoop-2.6.4.tar.gz -C /usr/local # 解压到/usr/local中
cd /usr/local/
sudo mv ./hadoop-2.6.0/ ./hadoop # 将文件夹名改为hadoop
sudo chown -R hadoop:hadoop ./hadoop # 修改文件权限Hadoop 解压后即可使用。输入如下命令来检查 Hadoop 是否可用,成功则会显示 Hadoop 版本信息:
cd /usr/local/hadoop
./bin/hadoop version伪分布式需要修改6个配置文件 ,文件位于/usr/local/hadoop/etc/hadoop/
用gedit 大块复制会比较方便
1. slaves
将文件中原来的 localhost 删除,添加内容:
Slave1
Slave22. hadoop-env.sh
vim hadoop-env.sh
#第27行
export JAVA_HOME=/usr/local/java/jdk1.8.0_73
export HADOOP_HOME=/usr/local/hadoop3. core-site.xml
<!-- 指定HADOOP所使用的文件系统schema(URI),HDFS的老大(NameNode)的地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://Master:9000</value>
</property>
<!-- 指定hadoop运行时产生文件的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/local/hadoop/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
<property>
<name>hadoop.native.lib</name>
<value>true</value>
<description>Should native hadoop libraries, if present, be used.</description>
</property>4. hdfs-site.xml
<configuration>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>Master:50090</value>
</property>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/data</value>
</property>
<property>
<name>dfs.namenode.checkpoint.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/namesecondary</value>
</property>
</configuration>5. mapred-site.xml
需要先重命名,默认文件名为 mapred-site.xml.template
mv mapred-site.xml.template mapred-site.xml- 1
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>Master:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>Master:19888</value>
</property>
</configuration>6. yarn-site.xml
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>Master</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>将hadoop添加到环境变量
gedit ~/.bashrc
export JAVA_HOME=/usr/local/java/jdk1.8.0_73
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:$CLASSPATH:$JAVA_HOME/lib:$JRE_HOME/lib
export HADOOP_HOME=/usr/local/hadoop
export HADOOP_CONF_DIR=${HADOOP_HOME}/etc/hadoop
export HADOOP_COMMON_LIB_NATIVE_DIR=${HADOOP_HOME}/lib/native
export OPTS="-Djava.library.path=${HADOOP_HOME}/lib"
export SPARK_HOME=/usr/local/spark
export PATH=${SPARK_HOME}/sbin:$PATH
export PATH=${SPARK_HOME}/bin:$PATH
export SCALA_HOME=/usr/local/scala/scala-2.11.7
export PATH=/usr/local/scala/scala-2.11.7/bin:$PATH
export PATH=$PATH:$JAVA_HOME/bin:$JRE_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
export HADOOP_HOME=/usr/local/hadoop
export HADOOP_CONF_DIR=${HADOOP_HOME}/etc/hadoop
export HADOOP_COMMON_LIB_NATIVE_DIR=${HADOOP_HOME}/lib/native
export OPTS="-Djava.library.path=${HADOOP_HOME}/lib"
export PATH=$PATH:$JAVA_HOME/bin:$JRE_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin在Slave 上配置
配置好后,将 Master 上的 /usr/local/Hadoop 文件夹复制到各个节点上。因为之前有跑过伪分布式模式,建议在切换到集群模式前先删除之前的临时文件。在 Master 节点上执行: //先开Slave 虚拟机
sudo rm -r ./hadoop/tmp # 删除 Hadoop 临时文件
sudo rm -r ./hadoop/logs/* # 删除日志文件
tar -zcf ~/hadoop.master.tar.gz ./hadoop # 先压缩再复制
cd ~
scp ./hadoop.master.tar.gz Slave1:/home/hadoop
scp ./hadoop.master.tar.gz Slave2:/home/hadoop在 Slave1 节点上执行:
sudo rm -r /usr/local/hadoop # 删掉旧的(如果存在)
sudo tar -zxf ~/hadoop.master.tar.gz -C /usr/local
sudo chown -R hadoop:hadoop /usr/local/hadoop同样,如果有其他 Slave 节点,也要执行将 hadoop.master.tar.gz 传输到 Slave 节点、在 Slave 节点解压文件的操作。
首次启动需要先在 Master 节点执行 NameNode 的格式化:
hdfs namenode -format # 首次运行需要执行初始化,之后不需要启动hadoop
start-dfs.sh
start-yarn.sh
mr-jobhistory-daemon.sh start historyserver过命令 jps 可以查看各个节点所启动的进程。正确的话,在 Master 节点上可以看到 NameNode、ResourceManager、SecondrryNameNode、JobHistoryServer 进程
在 Slave 节点可以看到 DataNode 和 NodeManager 进程
也可以通过 Web 页面看到查看 DataNode 和 NameNode 的状态:http://master:50070/。如果不成功,可以通过启动日志排查原因。
测试的例子,在http://www.powerxing.com/install-hadoop/ 中有介绍,此处不再赘述。
安装Spark
官网下载地址:http://spark.apache.org/downloads.html
需要下载预编译版本
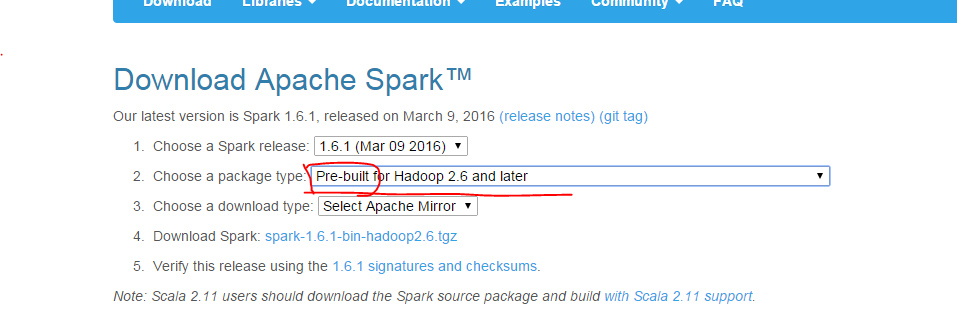
下载后,执行如下命令进行安装:
sudo tar -zxf ~/Downloads/spark-1.6.1-bin-hadoop2.6.tgz -C /usr/local/
cd /usr/local
sudo mv ./spark-1.6.1-bin-hadoop2.6.tgz/ ./spark
sudo chown -R hadoop:hadoop ./spark 安装后,需要在 ./conf/spark-env.sh 中修改 Spark 的 Classpath,执行如下命令拷贝一个配置文件:
cd /usr/local/spark
cp ./conf/spark-env.sh.template ./conf/spark-env.sh编辑 ./conf/spark-env.sh(gedit ./conf/spark-env.sh) ,在最后面加上如下:
export JAVA_HOME=/usr/local/java/jdk1.8.0_73
export SCALA_HOME=/usr/local/scala/scala-2.11.7
export HADOOP_HOME=/usr/local/hadoop
export HADOOP_CONF_DIR=/usr/local/hadoop/etc/hadoop
export SPARK_MASTER_IP=192.168.2.100
export SPARK_WORKER_INSTANCES=2
export SPARK_WORKER_MEMORY=1g
export SPARK_WORKER_CORES=1
export SPARK_HOME=/usr/local/spark
export SPARK_DIST_CLASSPATH=$(/usr/local/hadoop/bin/hadoop classpath)
cd conf/
cp slaves.template slaves
vim slaves
#insert
Slave1
Slave2配置系统环境变量
加入
${SPARK_HOME}:bin
${SPARK_HOME}:sbin修改spark-defaults.conf
cp spark-defaults.conf.template spark-defaults.conf
#加入
spark.executor.extraJavaOptions -XX:+PrintGCDetails -DKey=value -Dnumbers="one two three"
spark.eventLog.enabled true
spark.eventLog.dir hdfs://Master:9000/historyserverforSpark
spark.yarn.historySever.address Master:18080
spark.history.fs.logDirectory hdfs://Master:9000/historyserverforSpark给Slave配置
tar -zcf ~/spark.master.tar.gz ./spark # 先压缩再复制
cd ~
scp ./spark.master.tar.gz Slave1:/home/hadoop
scp ./spark.master.tar.gz Slave2:/home/hadoop
在 Slave1 节点上执行(其他的也一样):
sudo rm -r /usr/local/spark # 删掉旧的(如果存在)
sudo tar -zxf ~/spark.master.tar.gz -C /usr/local
sudo chown -R hadoop:hadoop /usr/local/spark配置historyserverforSpark
hadoop dfs -rmr /historyserverforSpark
hadoop dfs -mkdir /historyserverforSpark到此基本就已经配置完全了!大功告成!
来测试一下。
最后测试
首先启动hadoop
cd /usr/local/hadoop/sbin/
start-all.sh
start-yarn.sh
mr-jobhistory-daemon.sh start historyserver
cd /usr.loacl/spark/sbin/
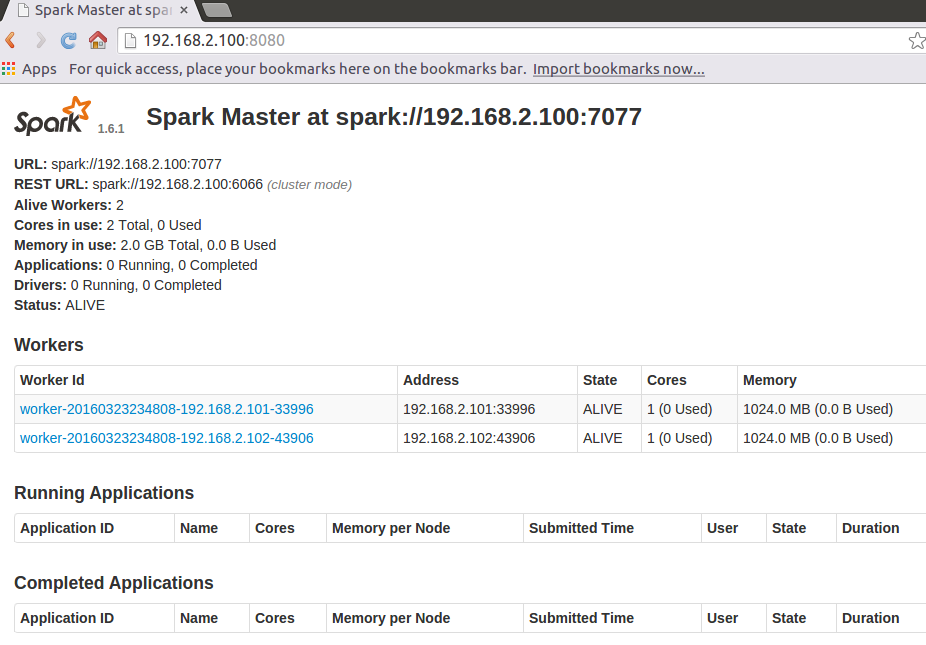
start-all.sh
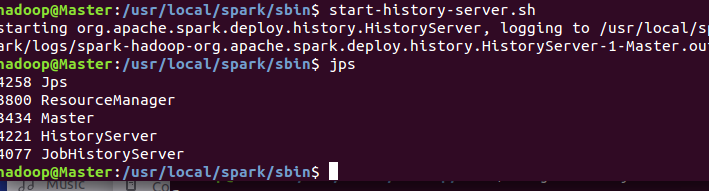
./start-history-server.sh
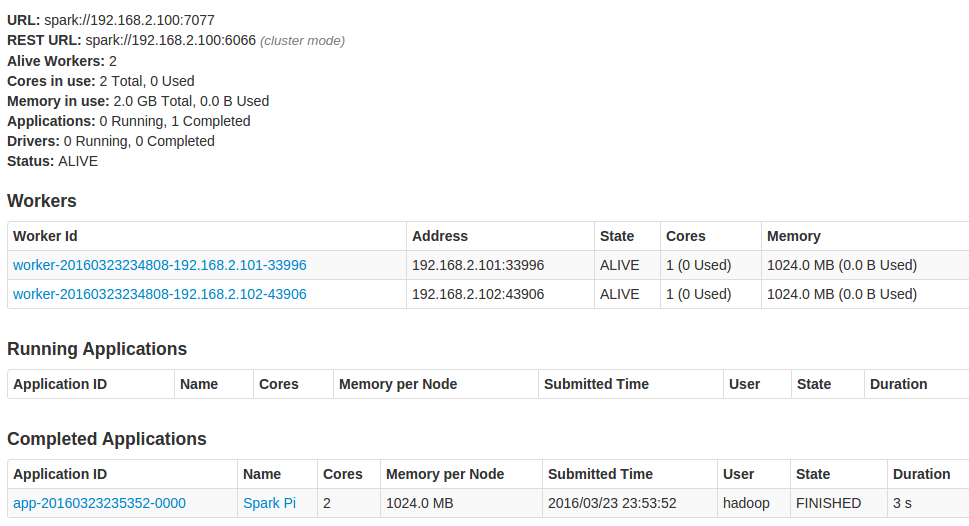
./spark-submit --class org.apache.spark.examples.SparkPi --master spark://Master:7077 ../lib/spark-examples-1.6.1-hadoop2.6.0.jar 10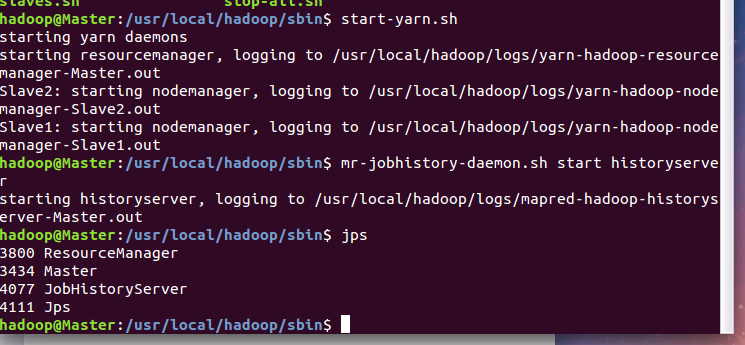
最新文章
- Win10怎么设置始终以管理员身份运行应用程序
- Block回调
- 很少再用left join
- lucene 查询的使用
- C#使用Fixed创建固定大小的缓冲区
- 搭建Spring + SpringMVC + Mybatis框架之一(创建项目)
- argparse - 命令行选项与参数解析(转)
- JAVA客户端API调用memcached两种方式
- QuaZip实现多文件打包
- 微信公众账号【iOSDevTip】推出新栏目【看大牛】
- pc2日记——有惊无险的第二天2014/08/29
- 实时音视频互动系列(下):基于 WebRTC 技术的实战解析
- 数据结构与算法--从平衡二叉树(AVL)到红黑树
- macbook air扩展显示器全屏滑动怎样不一起滑动?
- Web开发工具——Jupyter notebook
- python3.6 使用 pymysql 连接 Mysql 数据库及 简单的增删改查操作
- 文件中间修改内容遇到OSEerror
- UVa514 Rails (栈)
- 一次linux服务器黑客入侵后处理
- Ubuntu 14.04 LTS 系统空间不足,输入密码后,无法进入桌面的解决办法