Spark(二)【sc.textfile的分区策略源码分析】
2024-08-31 13:20:14
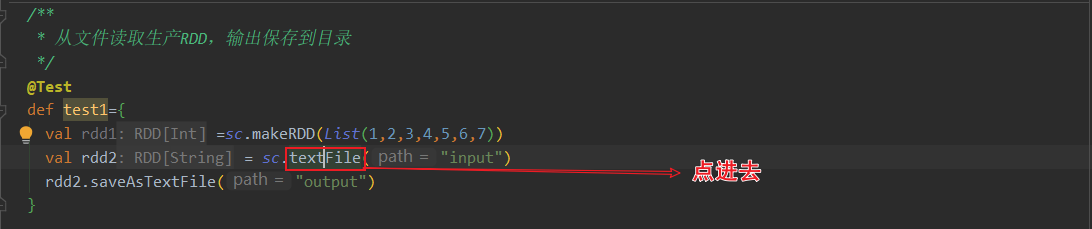
sparkcontext.textFile()返回的是HadoopRDD!
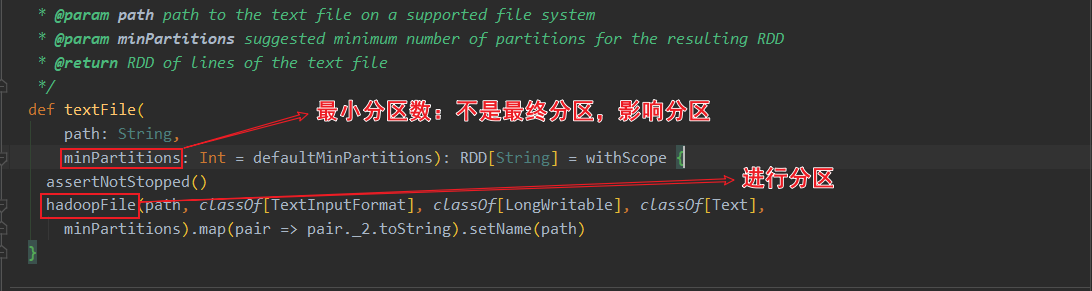
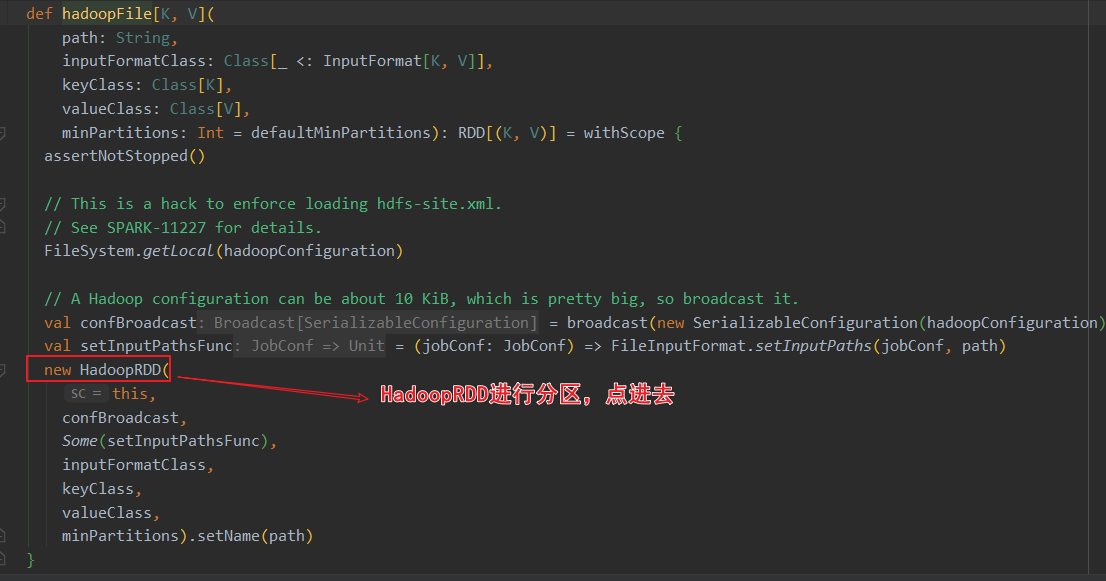
关于HadoopRDD的官方介绍,使用的是旧版的hadoop api

ctrl+F12搜索 HadoopRDD的getPartitions方法,这里进行了分区计算
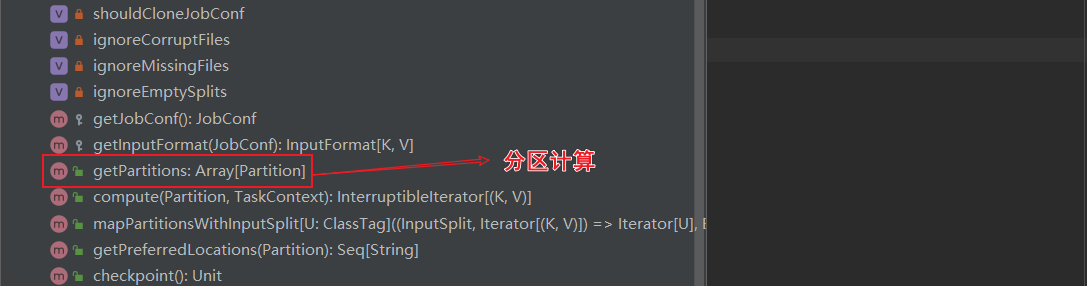
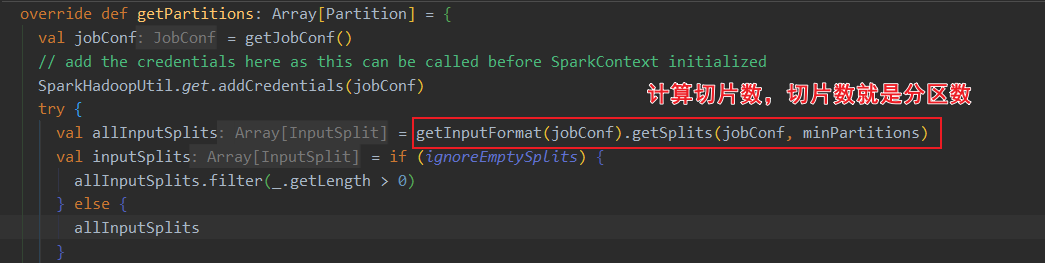
读取的是txt文件,用的是TextInputFormat的切片规则
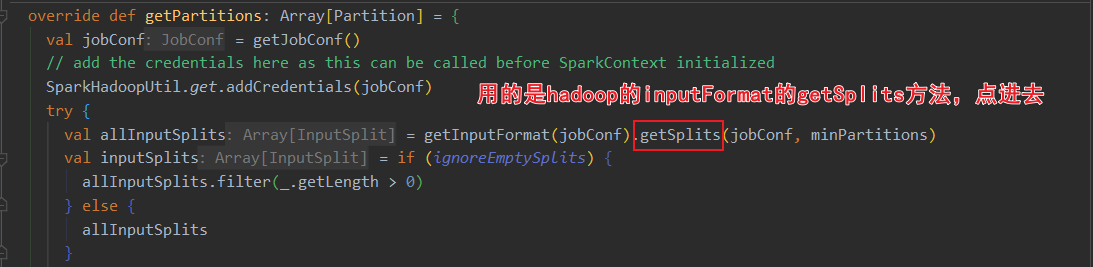
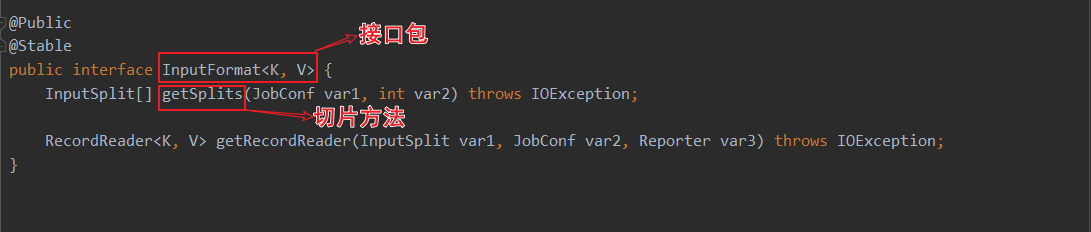
当前spark3.0的HadoopRDD依赖于hadoop的切片规则。其中HadoopRDD用的是旧版hadoop API,还有个NewHadoopRDD用的是新版hadoop API

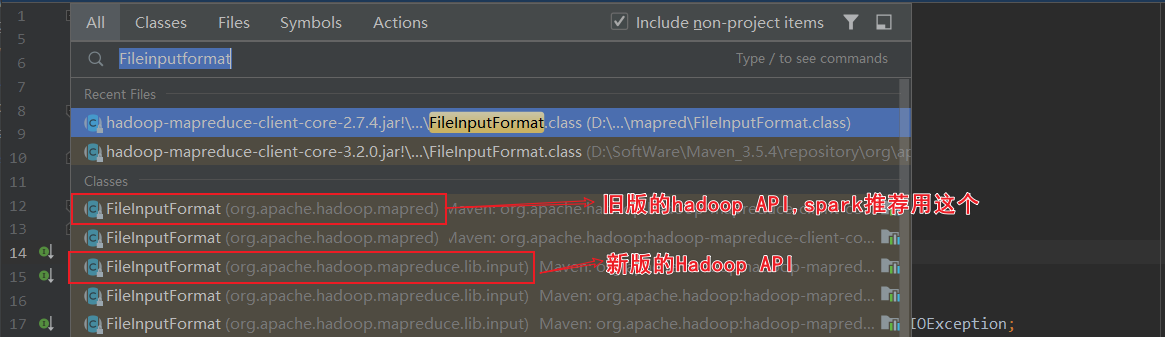
进去TextInputFromat的查看split方法
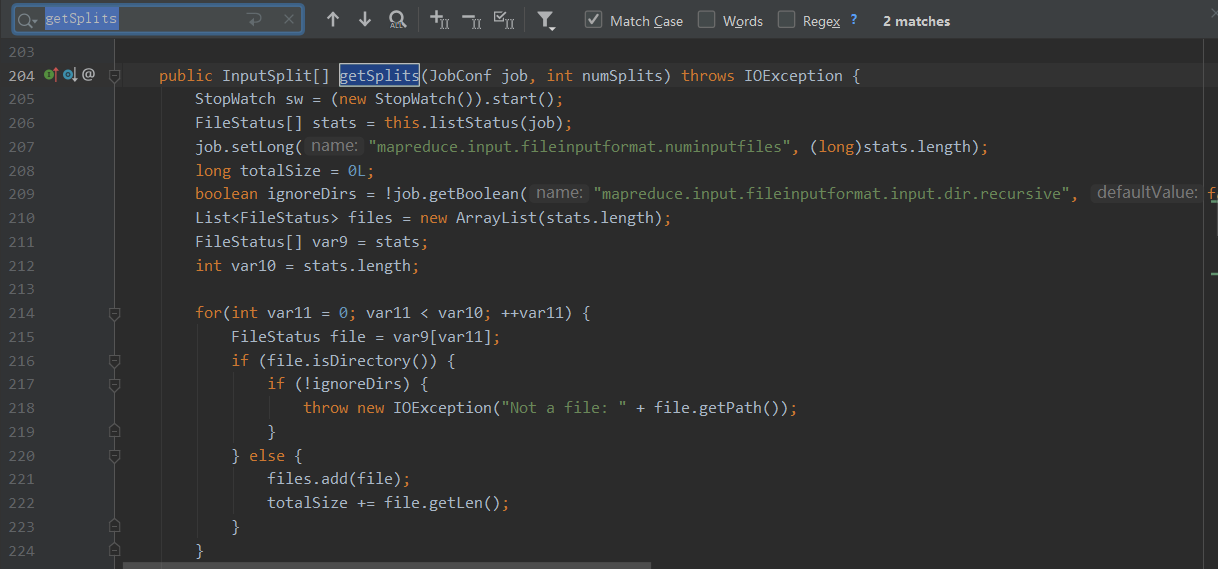
public InputSplit[] getSplits(JobConf job, int numSplits)
throws IOException {
// 获取要操作的所有文件的属性信息
FileStatus[] files = listStatus(job);
// 所有文件的总大小
long totalSize = 0; // compute total size
// 目标切片大小 numSplits=defaultMinPartitions
long goalSize = totalSize / (numSplits == 0 ? 1 : numSplits);
//默认为1
long minSize = Math.max(job.getLong(org.apache.hadoop.mapreduce.lib.input.
FileInputFormat.SPLIT_MINSIZE, 1), minSplitSize);
// generate splits
ArrayList<FileSplit> splits = new ArrayList<FileSplit>(numSplits);
NetworkTopology clusterMap = new NetworkTopology();
// 切片是以文件为单位切
for (FileStatus file: files) {
//获取文件大小
long length = file.getLen();
//文件不为空
if (length != 0) {
// 文件是否可切,一般普通文件都可切,如果是压缩格式,只有lzo,Bzip2可切
if (isSplitable(fs, path)) {
// 获取文件的块大小 默认128M
long blockSize = file.getBlockSize();
// 计算片大小
long splitSize = computeSplitSize(goalSize, minSize, blockSize);
long bytesRemaining = length;
// 循环切片,以splitSize为基础进行切片 , 切的片大小,最后一片有可能小于片大小的1.1倍
while (((double) bytesRemaining)/splitSize > SPLIT_SLOP) {
String[][] splitHosts = getSplitHostsAndCachedHosts(blkLocations,
length-bytesRemaining, splitSize, clusterMap);
// makeSplit()切片
splits.add(makeSplit(path, length-bytesRemaining, splitSize,
splitHosts[0], splitHosts[1]));
bytesRemaining -= splitSize;
}
//剩余部分,不够一片,全部作为1片
if (bytesRemaining != 0) {
String[][] splitHosts = getSplitHostsAndCachedHosts(blkLocations, length
- bytesRemaining, bytesRemaining, clusterMap);
splits.add(makeSplit(path, length - bytesRemaining, bytesRemaining,
splitHosts[0], splitHosts[1]));
}
} else {
String[][] splitHosts = getSplitHostsAndCachedHosts(blkLocations,0,length,clusterMap);
splits.add(makeSplit(path, 0, length, splitHosts[0], splitHosts[1]));
}
} else {
// 文件为空,创建一个空的切片
//Create empty hosts array for zero length files
splits.add(makeSplit(path, 0, length, new String[0]));
}
}
sw.stop();
if (LOG.isDebugEnabled()) {
LOG.debug("Total # of splits generated by getSplits: " + splits.size()
+ ", TimeTaken: " + sw.now(TimeUnit.MILLISECONDS));
}
return splits.toArray(new FileSplit[splits.size()]);
}
计算片大小:片大小的计算以所有文件的总大小计算,切片时以文件为单位进行切片。
protected long computeSplitSize(long goalSize, long minSize,
long blockSize) {
// minSize默认为1
return Math.max(minSize, Math.min(goalSize, blockSize));
}
总结:在大数据的计算领域,一般情况下,块大小就是片大小!
分区数过多,会导致切片大小 < 块大小。
分区数过少,task个数也会少,数据处理效率低,合理设置分区数。
最新文章
- Eclipse的快捷键
- mysql 分页查询
- 基于 Asp.Net的 Comet 技术解析
- Jackson
- c# Invalidate() Update() Refresh()的区别
- jquery的ajax可以传入的三种参数类型
- 使用WCF 测试客户端测试你的WCF服务
- Linux中的元字符和转义符 单引号 硬引号 双引号 软引号
- 二十四种设计模式:中介者模式(Mediator Pattern)
- Js判断密码强度并显示提示信息
- Thinkphp join 连接查询
- MySQL优化必须调整的10项配置
- Spring Boot IoC 容器初始化过程
- Python网络数据采集二
- 20145339顿珠 Exp5 MSF基础应用
- ARMV7,ARMV8
- hdu-1050(贪心+模拟)
- 学习python第四天——Oracle分组
- Java并发编程(4)--生产者与消费者模式介绍
- maven子模块转化成project