Python编程中 re正则表达式模块 介绍与使用教程
Python编程中 re正则表达式模块 介绍与使用教程
一、前言:
这篇文章是因为昨天写了一篇 shell script 的文章,在文章中俺大量调用多媒体素材与网址引用。这样就会有一个问题就是:随着俺的技能的提高,需要类比的、引用的、整理的就会越来越多。这样会出现一个问题就是 针对 url 做一个全面的检查,保证所有链接读者都可以打开。嗯,就是这样的一个轮子。目前计划先是 **re模块找到url链接,requests 模块再进行源码爬取与判断 。后面再升级的话可以考虑修复链接的错误,更强可以再修复文档中各种错误(这些就是后话了)。为啥会写这篇文章呢?俺觉得网上很多人都是抄袭或没有实战经验,写的东西不容易懂也不容易被利用 **。正好现在俺在造轮子,那就参考参考权威资料和几位前辈的美文,动动手,写篇 re模块 的详细介绍。
二、介绍:
I、正则表达式
正则表达式,又称正规表示式、正规表示法、正规表达式、规则表达式、常规表示法(英语:Regular Expression,在代码中常简写为regex、regexp或RE),是计算机科学的一个概念。正则表达式使用**单个字符串来描述、匹配一系列匹配某个句法规则的字符串 **。在很多文本编辑器里,正则表达式通常被用来检索、替换那些匹配某个模式的文本。许多程序设计语言都支持利用正则表达式进行字符串操作。例如,在Perl中就内建了一个功能强大的正则表达式引擎。正则表达式这个概念最初是由Unix中的工具软件(例如sed和grep)普及开的。——摘自维基百科
文字表达式全集 (番茄) 正则表达式语法(IBM) 图片表达式全集 Regular Expression Syntax
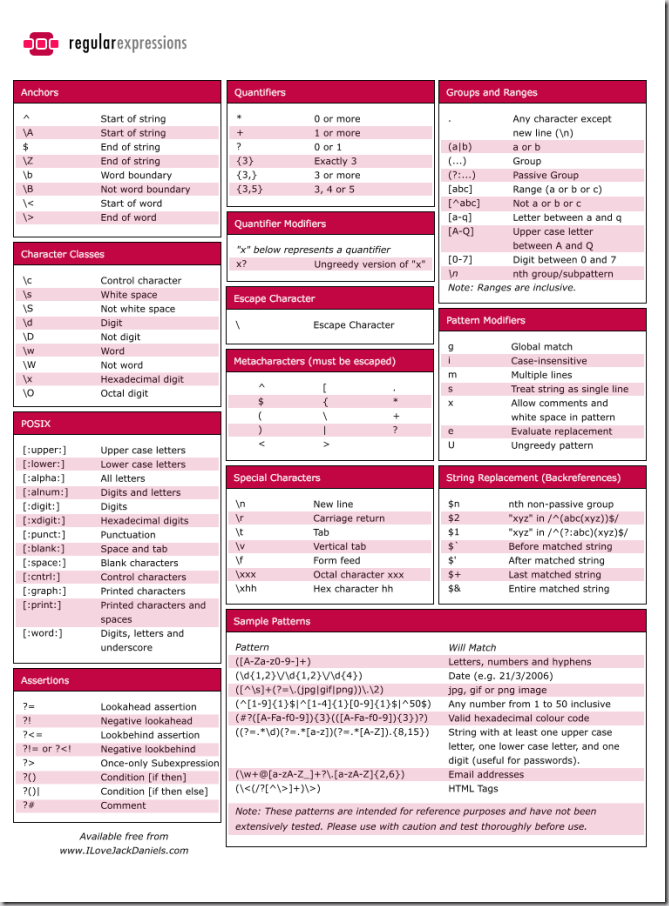{kind=link}
II、re 模块
This module provides regular expression matching operations similar to those found in Perl. ——摘自官方手册
Python 的 re 模块(Regular Expression 正则表达式)提供各种正则表达式的匹配操作,和 Perl 脚本的正则表达式功能类似,使用这一内嵌于 Python 的语言工具,尽管不能满足所有复杂的匹配情况,但足够在绝大多数情况下能够有效地实现对复杂字符串的分析并提取出相关信息。Python 会将正则表达式转化为字节码,利用 C 语言的匹配引擎进行深度优先的匹配。——摘自IBM
In [9]: print(str(len(re.__all__))+" 个子模块")
27 个子模块
In [10]: print(re.__all__)
['match', 'fullmatch', 'search', 'sub', 'subn', 'split', 'findall', 'finditer', 'compile', 'purge', 'template', 'escape', 'error', 'A', 'I', 'L', 'M', 'S', 'X', 'U', 'ASCII', 'IGNORECASE', 'LOCALE', 'MULTILINE', 'DOTALL', 'VERBOSE', 'UNICODE']
三、约定:
1、反斜杠
与大多数编程语言相同,正则表达式里使用"\"作为转义字符,这就可能造成反斜杠困扰。假如你需要匹配文本中的字符"\",那么使用编程语言表示的正则表达式里将需要4个反斜杠"\\\\":前两个和后两个分别用于在编程语言里转义成反斜杠,转换成两个反斜杠后再在正则表达式里转义成一个反斜杠。Python里的原生字符串很好地解决了这个问题,这个例子中的正则表达式可以使用r"\\"表示。同样,匹配一个数字的"\\d"可以写成r"\d"。有了原生字符串,你再也不用担心是不是漏写了反斜杠,写出来的表达式也更直观。
2、匹配模式
re 所定义的 flag 包括:
re.I 忽略大小写
re.L 表示特殊字符集 \w, \W, \b, \B, \s, \S 依赖于当前环境
re.M 多行模式
re.S 即为’ . ’并且包括换行符在内的任意字符(’ . ’不包括换行符)
re.U 表示特殊字符集 \w, \W, \b, \B, \d, \D, \s, \S 依赖于 Unicode 字符属性数据库
re.X 为了增加可读性,忽略空格和’ # ’后面的注释
3、条件返回值
In [30]: a='afoaisfoasnfo'
In [31]: if re.match(r'[a-z]*',a):
...: print('It\'s Ture')
...:
It's Ture
四、使用:

I、re.compile
将正则表达式(以字符串书写的)转换为模式对象,供 match() 和 search() 这两个函数使用,可以实现更有效率的匹配。
re.compile(pattern[, flags])

# 如果在调用 match 或 search 函数时,使用字符串表示的正则表达式,它们会在内部将字符串转换成正则表示式对象。但是如果使用了compile 进行一次转换之后,在每次使用模式的时候就不需要再次进行转换。(没有特殊情况基本不用会比较麻烦)
# 例:以下两种用法结果相同:
# A)
compiled_pattern = re.compile(pattern)
result = compiled_pattern.match(string)
# B)
result = re.match(pattern, string)
II、re.search
在字符串中查找匹配正则表达式模式的位置,**一旦找到子字符串 **返回 MatchObject 的实例(值为True),否则返回 None(值为False)。
re.search(pattern, string[, flags])
# 例:以下代码为俺的半成品项目
def Regular_expression(self):
with open(self.doc_location.encode('utf-8')) as doc_files:
return re.search(r'(ht|f)(tp+)(s?)(://)[a-zA-Z0-9\.]+(?#url)(:[0-9]+)*(?#port)(/)',doc_files.read())
# 千万注意,search() 函数是扫描整个字符串来查找匹配。一旦使用了 re.search 找到了第一个符合的字符串会立刻停止查找。
III、re.march
从字符串开头位置开始匹配正则表达式,match() 函数只在字符串的开始位置尝试匹配正则表达式,也就是只报告从位置 0 开始的匹配情况。
re.match(pattern, string[, flags])
# 如果想要搜索整个字符串来寻找匹配,应当用 search()。
# 例:
In [79]: if re.match('a','www.python.org')==None: print('Match False')
Match False
In [80]: if re.match('w','www.python.org')==None: print('Match False')
In [81]: if re.match('ww','www.python.org')==None: print('Match False')
IIII、re.split
可以将字符串匹配正则表达式的匹配项来切割字符串并返回一个列表。
re.split(pattern, string[, maxsplit=0, flags=0])
In [85]: modleText='this is the test'
In [86]: print(modleText.split(' '))
['this', 'is', 'the', 'test']
In [87]: print(re.split(' ',modleText))
['this', 'is', 'the', 'test']
V、re.findall
在字符串中找到正则表达式所匹配的所有子串,返回给定模式的所有匹配项并组成一个列表返回。
re.findall(pattern, string[, flags])
# 实例1
def Regular_expression(self):
with open(self.doc_location.encode('utf-8')) as doc_files:
return re.findall(r'(ht|f)(tp+)(s?)(://)[a-zA-Z0-9\.]+(?#url)(:[0-9]+)*(?#port)(/)',doc_files.read())
> python lsurl.py
Please Input The Path About Documents: c:\users\rabbit\Desktop\example.txt
[('ht', 'tp', '', '://', '', '/'), ('ht', 'tp', 's', '://', ':2121', '/')]
# 实例2(给正则加上了括号)
def Regular_expression(self):
with open(self.doc_location.encode('utf-8')) as doc_files:
return re.findall(r'((ht|f)(tp+)(s?)(://)[a-zA-Z0-9\.]+(?#url)(:[0-9]+)*(?#port)(/))',doc_files.read())
> python lsurl.py
Please Input The Path About Documents: c:\users\rabbit\Desktop\example.txt
[('http://c.example.net/', 'ht', 'tp', '', '://', '', '/'), ('https://ira.be.me:2121/', 'ht', 'tp', 's', '://',
:2121', '/')]
VI、re.sub
使用给定的替换内容将匹配模式的字符串替换掉。在字符串 string 中找到匹配正则表达式 pattern 的所有子串,用另一个字符串 repl 进行替换。如果没有找到匹配 pattern 的串,则返回未被修改的 string。repl 既可以是字符串也可以是一个函数。
re.sub(pattern, repl, string[, count, flags])
In [91]: help(re.sub)
Help on function sub in module re:
sub(pattern, repl, string, count=0, flags=0)
Return the string obtained by replacing the leftmost
non-overlapping occurrences of the pattern in string by the
replacement repl. repl can be either a string or a callable;
if a string, backslash escapes in it are processed. If it is
a callable, it's passed the match object and must return
a replacement string to be used.
In [92]: re.sub('(is|this)','sub','this is contect')
Out[92]: 'sub sub contect'
In [93]: re.sub('(is|this)','sub','this is contect',count=1)
Out[93]: 'sub is contect'
----------------
In [94]: p = re.compile( '(one|two|three)')
In [95]: p.sub( 'num', 'one word two words three words')
Out[95]: 'num word num words num words'
In [96]: p.subn( 'num', 'one word two words three words')
# 该函数的功能和 sub() 相同,但它还返回新的字符串以及替换的次数。
Out[96]: ('num word num words num words', 3)
VII、re.escape
它可以对字符串中所有可能被解释为正则运算符的字符进行转义的应用函数。
re.escape(pattern)
In [99]: re.escape('https://cdn.itxdm.com')
Out[99]: 'https\\:\\/\\/irabe\\.me'
In [100]: re.escape('https://www.itxdm.com')
Out[100]: 'https\\:\\/\\/www\\.itxdm\\.com'
相关主题:
引用维基百科:https://zh.wikipedia.org/wiki/正则表达式/
参考IBM一文:https://www.ibm.com/developerworks/cn/opensource/os-cn-pythonre/index.html
参考 "Python基础教程" 一书
推荐后续阅读1:https://www.cnblogs.com/huxi/archive/2010/07/04/1771073.html
推荐后续阅读2:https://www.ibm.com/developerworks/cn/opensource/os-cn-pythonre/index.html
最新文章
- 剑指offer五:
- C++ 为什么拷贝构造函数参数必须为引用?赋值构造函数参数也必须为引用吗?
- tomcat 无法加载js和css 等静态文件的问题
- SIEBEL应用概述
- Linux命令--文件管理
- [转]null和""以及==与equals的区别
- 给Jquery添加alert,prompt方法,类似系统的Alert,Prompt,可以响应键盘,支持拖动
- 在linux上用dd命令实现ghost功能
- linux reboot命令
- HDU5140---Hun Gui Wei Company (主席树)
- 记录:sea.js和require.js配置 与 性能对比
- php memcached缓存集群
- jsp之用户自定义标签
- SQL数据库基础知识-巩固篇<一>
- Vuforia开发完全指南---License Manager和Target Manager详解
- js 设计模式之观察者模式
- Java程序设计教程(第2版)阅读总结
- WPF调用zxing生成二维码
- Linux命令(十三)make_makefile基础
- [转]numpy 100道练习题