Spark小问题合集
1)在win7下使用spark shell运行spark程序,通过以下形式读取文件时
sc.sequenceFile[Int,String]("./sparkF")
偶尔会出现“Input path does not exist”,原因是没有使用“file:///”表示文件时本地文件系统上的文件,相对路径形式如下:
sc.sequenceFile[Int,String]("file:///.\\sparkF")
不过,还可以使用绝对路径,更保险些。
2)在Ubuntu上读取文件,貌似三种都可以。参考0
sc.sequenceFile[Int,String]("file:///home/hadoop/sparkF")
sc.sequenceFile[Int,String]("file://home/hadoop/sparkF")
sc.sequenceFile[Int,String]("file:/home/hadoop/sparkF")
3)可以使用println()打印某些变量值,然后在Exector对应的stdout可以看到打印的内容
4)有时候电脑IP没有固定的话,从教研室把电脑背回来,在IDEA上单机运行spark程序就失败了,提示如下:
ERROR NettyTransport: failed to bind to host.home/192.168.1.124:
“192.168.1.124”是在教研室的IP。出错的原因就是,创建sparkContext时,在“SparkEnv.scala”中,可以看到“spark.driver.host”对应值是:
192.1681.1.124//正好是教研室地址,与当前地址不同,自然报错
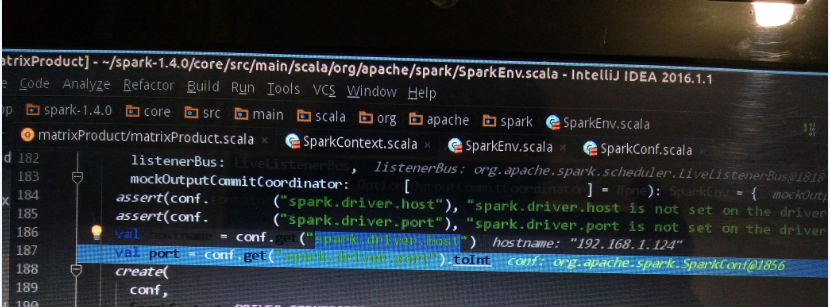
修改代码即可,原先代码如下:
val conf2=new SparkConf().setAppName("matrixProduct").setMaster(args())
修改后代码如下:
val conf2=new SparkConf().setAppName("matrixProduct").setMaster(args()).set("spark.local.ip","127.0.0.1")
.set("spark.driver.host","127.0.0.1")
5)有时候运行spark作业会提示“WARN TaskSchedulerImpl: Initial job has not accepted any resources; check your cluster UI to ensure that workers are registered and have sufficient memory”,原因是申请的Exector内存比节点自身内存还要大。访问web界面中8080端口,看到每个节点的RAM是979MB,而提交作业时使用关键字 --executor-memory 1g,这样就超过了自身内存,所以报错。参考
6)使用IDEA调试spark程序时,在控制台窗口会打印出很多的“INFO,WARN”类信息,这些信息,我们并不需要,我们只需要打印出“ERROR”信息,解决方法如下:
1.首先生成spark_Home/conf中的“log4j.properties“文件,方法如下:
Even simpler you just cd SPARK_HOME/conf
then mv log4j.properties.template log4j.properties then open log4j.properties and change all INFO to ERROR.
Here SPARK_HOME is the root directory of your spark installation.
其实生成了“log4j.properties”文件之后,当我们使用集群的方式运行spark程序时,就可以在控制台屏蔽掉那些”INFO“和”WARN“类的信息,但是如果是在IDEA本地调试spark程序时,”INFO“ ”WARN“类信息仍然会打印出来,解决方法参考以下方法
2.在完成了上述步骤之后,为了保证在IDEA中调试spark程序时避免打印”INFO“、”WARN“类信息,需要在spark程序在添加如下代码:
import org.apache.log4j.PropertyConfigurator
PropertyConfigurator.configure("path to log4j.properties")
sparkconf.set("log4j.configuration", "path to log4j.properties");
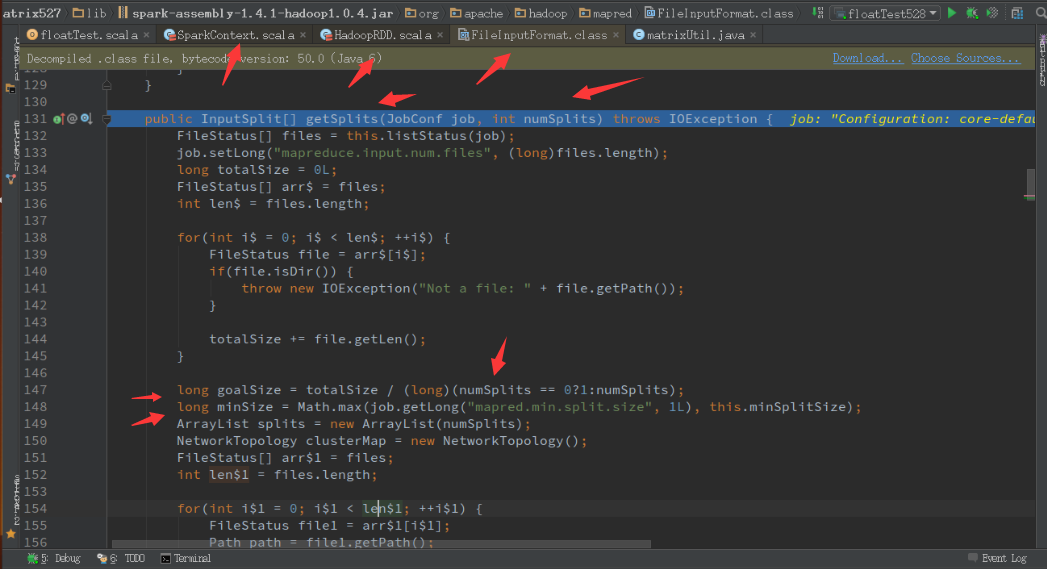
7)Spark下SequenceFile文件分片数量的确定
http://www.cnblogs.com/gaoze/p/5208970.html
对于在spark中使用Sequence,其分片数量的计算方式与hadoop中相同,其实就是调用了hadoop中的实现来计算,计算goalSize,minSize,maxSize。如下图:
8)sortBy和sortByKey函数
http://www.iteblog.com/archives/1240
9)遍历了一次 Iterable 之后,再次遍历的时候,数据都没了
https://my.oschina.net/leejun2005/blog/131744
最新文章
- VIM下的跳转练习
- Y+的一些讨论
- TransactionScope 使用记录
- Win7系统安装好Axure点击运行报.NET Framework4.0未安装的解决办法
- hdu 1863 - 畅通工程(MST)
- 【bzoj2435】[NOI2011]道路修建
- NYOJ题目113字符串替换
- fifo read
- 【C#进阶系列】00 序
- 游戏模块分析总结(2)之UI、操作篇
- php yii框架使用MongoDb
- css_day7
- yield 学习笔记
- Postman 安装
- C#基础知识之属性
- 使用VSCode如何调试C#控制台程序_1
- 1060D Social Circles(贪心)
- python之路第二天
- 无法删除另一个分区的windows文件夹
- 【PAT】B1032 挖掘机技术哪家强(20 分)
热门文章
- Tumblr:150亿月浏览量背后的架构挑战
- 自己实现的JDBC工具类
- 图论---图的m-点着色判定问题(回溯法--迭代式)
- [目前未找到题目]扩展KMP模板
- [bzoj3224]Tyvj 1728 普通平衡树——splay模板
- bzoj 1996 DP
- LeetCode 4 Median of Two Sorted Array
- POJ2186 (强连通分量缩点后出度为0的分量内点个数)
- kuangbin带你飞 生成树专题 : 次小生成树; 最小树形图;生成树计数
- 【“10”力全开 游戏“Ti”厉害】ZX53VE-新飞行堡垒笔记本(Windows 10 Home/新七代标压i7-7700HQ/GTX 1050Ti 4G/8G内存/1TB+128GB)