Spark运行模式_local(本地模式)
2024-10-15 06:25:31
本地运行模式 (单机)
- 该模式被称为Local[N]模式,是用单机的多个线程来模拟Spark分布式计算,直接运行在本地,便于调试,通常用来验证开发出来的应用程序逻辑上有没有问题。
- 其中N代表可以使用N个线程,每个线程拥有一个core。如果不指定N,则默认是1个线程(该线程有1个core)。
- 如果是local[*],则代表 Run Spark locally with as many worker threads as logical cores on your machine.


那么,这些线程都运行在什么进程下呢?
运行该模式非常简单,只需要把Spark的安装包解压后,改一些常用的配置即可使用,而不用启动Spark的Master、Worker守护进程( 只有集群的Standalone方式时,才需要这两个角色),也不用启动Hadoop的各服务(除非你要用到HDFS),这是和其他模式的区别哦,要记住才能理解。
那么,这些执行任务的线程,到底是共享在什么进程中呢?
我们用如下命令提交作业:

可以看到,在程序执行过程中,只会生成一个SparkSubmit进程。
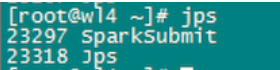
这个SparkSubmit进程又当爹、又当妈,既是客户提交任务的Client进程、又是Spark的driver程序、还充当着Spark执行Task的Executor角色。(如下图所示:driver的web ui)

这里有个小插曲,因为driver程序在应用程序结束后就会终止,那么如何在web界面看到该应用程序的执行情况呢,需要如此这般:(如下图所示)

转载自:
作者:俺是亮哥
链接:https://www.jianshu.com/p/65a3476757a5
來源:简书
最新文章
- 51nod1265(判断四个点是否共面)
- 对express中引入文件时提示Error: Cannot find module错误的理解
- 2016 ECJTU - STL
- BPM业务流程管理与SAP如何更好集成整合?
- js控制固定div和随屏滚动div兼容多浏览器和纯css控制(来自网络)
- [Android][Audio] audio_policy.conf文件分析
- 4-2.矩阵乘法的Strassen算法详解
- LNMP笔记:更改网站文件和MySQL数据库的存放目录
- jQuery数据缓存data(name, value)详解及实现
- HttpWatch工具简介及使用技巧(转载)
- struts2(三)之表单参数自动封装与参数类型自动转换
- C#2.0之细说泛型
- ASA failover --AA
- openXML向Word插入表
- redis主从复制和sentinel配置高可用
- OpenSIPS 1.11.1安装记录
- Java+Selenium3框架设计篇5-如何实现邮件发送测试报告
- python类型错误:can only concatenate list (not "str") to list
- 洛谷P1244 青蛙过河 DP/思路
- Python爬虫项目--爬取某宝男装信息