MapReduce机制
1. MapReduce是一种分布式计算模型,由Google提出,主要用于搜索领域,解决海量数据的计算问题。
2. MR由两个阶段组成:Map和Reduce,用户只需要实现map()和reduce()两个函数,即可实现分布式计算,非常简单。
这两个函数的形参是key、value对,表示函数的输入信息。
MapReduce的原理图如图所示:

整个处理过程的流程图:

我们不妨通过一个简单的例子加以说明。
这个例子是统计一堆域名中,每个域名各有多少个。如果放在单机上写程序,处理起来很容易,可以用个HashMap或者在数据库中distinct,但是一旦数据量足够大,单机无法满足的时候,就需要用到集群,即MapReduce进行运行。运行大概思路如下图所示,首先文件里面的内容被分成了若干块,放到了不同的map中,进行相应的统计处理,即变成<qq.com 1>这种形式,注意到这是可以分布运行的,不会影响到最终结果。框架在map处理完成之后,将所有kv对缓存起来,进行分组,然后传递一个组<key,valus{}>,相同的key为一组,相同的组放到一个reduce中进行运行。所以reduce收到的效果是类似<qq.com {1,1,1,1...}>这种格式,然后reduce再进行一个简单的加和运算就可以了,最终输出类似<qq.com 50000>这种效果。

◆执行步骤:
1. map任务处理
1.1 读取输入文件内容,解析成key、value对。对输入文件的每一行,解析成key、value对。每一个键值对调用一次map函数。
1.2 写自己的逻辑,对输入的key、value处理,转换成新的key、value输出。
2.reduce任务处理
2.1 在reduce之前,有一个shuffle的过程对多个map任务的输出进行合并、排序。
2.2写reduce函数自己的逻辑,对输入的key、value处理,转换成新的key、value输出。
2.3 把reduce的输出保存到文件中。
任务切片的示意图:
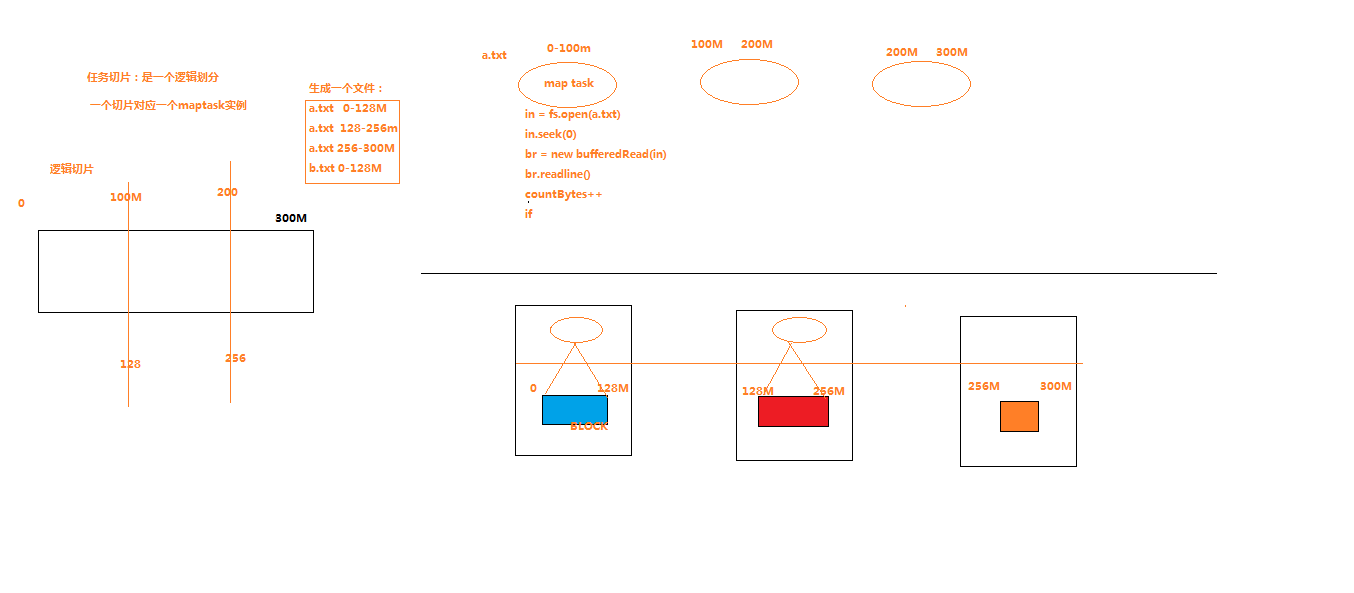
我们用代码进行说明,导入mapreduce所需要的相应包,建立三个文件:

WCMapper.java文件:
package cn.darrenchan.hadoop.mr.wordcount; import java.io.IOException; import org.apache.commons.lang.StringUtils;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper; //4个泛型中,前两个是指定mapper输入数据的类型,KEYIN是输入的key的类型,VALUEIN是输入的value的类型
//map 和 reduce 的数据输入输出都是以 key-value对的形式封装的
//默认情况下,框架传递给我们的mapper的输入数据中,key是要处理的文本中一行的起始偏移量,这一行的内容作为value
//下面这两种类型就相当于Long和String,是hadoop的类型
public class WCMapper extends Mapper<LongWritable, Text, Text, LongWritable>{ //mapreduce框架每读一行数据就调用一次该方法
@Override
protected void map(LongWritable key, Text value,Context context)
throws IOException, InterruptedException {
//具体业务逻辑就写在这个方法体中,而且我们业务要处理的数据已经被框架传递进来,在方法的参数中 key-value
//key 是这一行数据的起始偏移量 value 是这一行的文本内容 //将这一行的内容转换成string类型
String line = value.toString(); //对这一行的文本按特定分隔符切分
String[] words = StringUtils.split(line, " "); //遍历这个单词数组输出为kv形式 k:单词 v : 1
for(String word : words){
context.write(new Text(word), new LongWritable(1));
} } }
WCReducer.java文件:
package cn.darrenchan.hadoop.mr.wordcount; import java.io.IOException; import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer; public class WCReducer extends Reducer<Text, LongWritable, Text, LongWritable> { // 框架在map处理完成之后,将所有kv对缓存起来,进行分组,然后传递一个组<key,valus{}>,相同的key为一组,调用一次reduce方法
// <hello,{1,1,1,1,1,1.....}>
@Override
protected void reduce(Text key, Iterable<LongWritable> values,
Context context) throws IOException, InterruptedException { long count = 0;
// 遍历value的list,进行累加求和
for (LongWritable value : values) {
count += value.get();
} // 输出这一个单词的统计结果
context.write(key, new LongWritable(count)); } }
WCRunner.java文件:
package cn.darrenchan.hadoop.mr.wordcount; import java.io.IOException; import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; /**
* 用来描述一个特定的作业
* 比如,该作业使用哪个类作为逻辑处理中的map,哪个作为reduce
* 还可以指定该作业要处理的数据所在的路径
* 还可以指定改作业输出的结果放到哪个路径
* ....
*
*/
public class WCRunner { public static void main(String[] args) throws Exception { Configuration conf = new Configuration(); Job wcjob = Job.getInstance(conf); //设置整个job所用的那些类在哪个jar包
wcjob.setJarByClass(WCRunner.class); //本job使用的mapper和reducer的类
wcjob.setMapperClass(WCMapper.class);
wcjob.setReducerClass(WCReducer.class); //指定reduce的输出数据kv类型
wcjob.setOutputKeyClass(Text.class);
wcjob.setOutputValueClass(LongWritable.class); //指定mapper的输出数据kv类型
wcjob.setMapOutputKeyClass(Text.class);
wcjob.setMapOutputValueClass(LongWritable.class); //指定要处理的输入数据存放路径
FileInputFormat.setInputPaths(wcjob, new Path("/wc/srcdata/")); //指定处理结果的输出数据存放路径
FileOutputFormat.setOutputPath(wcjob, new Path("/wc/output/")); //将job提交给集群运行 ,将运行状态进行打印
wcjob.waitForCompletion(true); } }
我们可以以集群模式运行:
将工程打成jar包,上传到服务器,然后用hadoop命令提交 hadoop jar wc.jar cn.darrenchan.hadoop.mr.wordcount.WCRunner即可。
我们也可以以本地模式运行:
在linux的eclipse里面直接运行main方法,但是不要添加yarn相关的配置,也会提交给localjobrunner执行
----输入输出数据可以放在本地路径下(/home/hadoop/wc/srcdata/)
----输入输出数据也可以放在hdfs中(hdfs://weekend110:9000/wc/srcdata)
在运行过程中会打印运行状态,信息如下:
17/02/24 06:21:29 INFO client.RMProxy: Connecting to ResourceManager at weekend110/192.168.230.134:8032
17/02/24 06:21:30 WARN mapreduce.JobSubmitter: Hadoop command-line option parsing not performed. Implement the Tool interface and execute your application with ToolRunner to remedy this.
17/02/24 06:21:31 INFO input.FileInputFormat: Total input paths to process : 1
17/02/24 06:21:32 INFO mapreduce.JobSubmitter: number of splits:1
17/02/24 06:21:35 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1487945579635_0001
17/02/24 06:21:36 INFO impl.YarnClientImpl: Submitted application application_1487945579635_0001
17/02/24 06:21:37 INFO mapreduce.Job: The url to track the job: http://weekend110:8088/proxy/application_1487945579635_0001/
17/02/24 06:21:37 INFO mapreduce.Job: Running job: job_1487945579635_0001
17/02/24 06:21:48 INFO mapreduce.Job: Job job_1487945579635_0001 running in uber mode : false
17/02/24 06:21:48 INFO mapreduce.Job: map 0% reduce 0%
17/02/24 06:21:54 INFO mapreduce.Job: map 100% reduce 0%
17/02/24 06:21:59 INFO mapreduce.Job: map 100% reduce 100%
17/02/24 06:21:59 INFO mapreduce.Job: Job job_1487945579635_0001 completed successfully
17/02/24 06:21:59 INFO mapreduce.Job: Counters: 49
File System Counters
FILE: Number of bytes read=297
FILE: Number of bytes written=186437
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=208
HDFS: Number of bytes written=87
HDFS: Number of read operations=6
HDFS: Number of large read operations=0
HDFS: Number of write operations=2
Job Counters
Launched map tasks=1
Launched reduce tasks=1
Data-local map tasks=1
Total time spent by all maps in occupied slots (ms)=3753
Total time spent by all reduces in occupied slots (ms)=3019
Total time spent by all map tasks (ms)=3753
Total time spent by all reduce tasks (ms)=3019
Total vcore-seconds taken by all map tasks=3753
Total vcore-seconds taken by all reduce tasks=3019
Total megabyte-seconds taken by all map tasks=3843072
Total megabyte-seconds taken by all reduce tasks=3091456
Map-Reduce Framework
Map input records=8
Map output records=19
Map output bytes=253
Map output materialized bytes=297
Input split bytes=107
Combine input records=0
Combine output records=0
Reduce input groups=12
Reduce shuffle bytes=297
Reduce input records=19
Reduce output records=12
Spilled Records=38
Shuffled Maps =1
Failed Shuffles=0
Merged Map outputs=1
GC time elapsed (ms)=164
CPU time spent (ms)=1460
Physical memory (bytes) snapshot=218402816
Virtual memory (bytes) snapshot=726446080
Total committed heap usage (bytes)=137433088
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Input Format Counters
Bytes Read=101
File Output Format Counters
Bytes Written=87
最终会生成如下两个文件:

源文件是:
hello chenchi
hello jim
hello jack
hello darren
hello baby
hello dd
baby is my god
hahaha is rubbish
在part-r-0000中会显示相应结果:
baby 2
chenchi 1
darren 1
dd 1
god 1
hahaha 1
hello 6
is 2
jack 1
jim 1
my 1
rubbish 1
附:统计文本中记录条数的代码:
package com.darrenchan.hadoop; import java.io.IOException; import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; public class Count {
public static class CountMapper extends Mapper<LongWritable, Text, Text, LongWritable> { @Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
// 封装数据为kv并输出
context.write(new Text("count"), new LongWritable(1));
} } public static class CountReducer extends Reducer<Text, LongWritable, NullWritable, LongWritable> {
@Override
protected void reduce(Text key, Iterable<LongWritable> values,
Reducer<Text, LongWritable, NullWritable, LongWritable>.Context context)
throws IOException, InterruptedException {
long sum = 0; for (LongWritable value : values) {
sum += value.get();
}
context.write(NullWritable.get(), new LongWritable(sum));
}
} public static void main(String[] args) throws Exception { Configuration conf = new Configuration();
Job job = Job.getInstance(conf); job.setJarByClass(Count.class); job.setMapperClass(CountMapper.class);
job.setReducerClass(CountReducer.class); job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(LongWritable.class); job.setOutputKeyClass(Text.class);
job.setOutputValueClass(LongWritable.class); FileInputFormat.setInputPaths(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1])); System.exit(job.waitForCompletion(true) ? 0 : 1); } }
最新文章
- 【Python】引用计数
- (转)SQL 优化原则
- 使用数据泵+dblink迁移数据库,适用于本地空间不足的情况
- [No00002D] “大学生还不如农民工”背后的“身份教育”困境
- 求方程式ax^2+bx+c=0的根。
- 剑指Offer 合并两个排序的链表
- [JFinal 1] JFinal和SSH中使用拦截器的对比
- 把eclipse"中文版"变成"英文版"
- Junit 断言 assertThat Hamcrest匹配器
- MySQL 序列使用
- linux系统批量无人值守安装
- AT89C 系列单片机解密原理
- JS里的CSS函数
- pop动画使用示例
- win10 UWP 隐式转换
- java.text.DateFormat 线程不安全问题
- <FAT文件系统> -- DBR
- 解决腾讯云封锁SS(shadow--socks)访问google问题
- istio实现对外暴露服务
- curl模拟请求常用参数