正则化--Lambda
2024-09-06 15:03:04
模型开发者通过以下方式来调整正则化项的整体影响:用正则化项的值乘以名为 lambda(又称为正则化率)的标量。也就是说,模型开发者会执行以下运算:
$$\text{minimize(Loss(Data|Model)} + \lambda \text{ complexity(Model))}$$
执行 L2 正则化对模型具有以下影响:
- 使权重值接近于 0(但并非正好为 0)
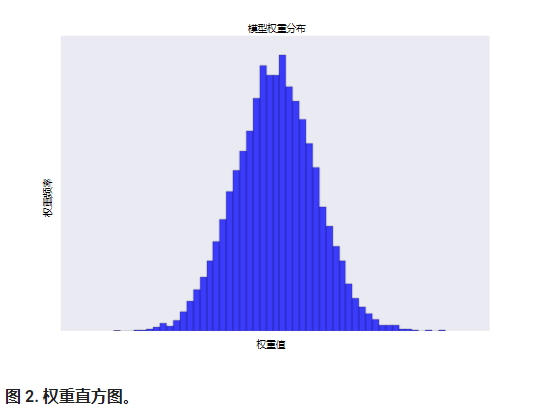
- 使权重的平均值接近于 0,且呈正态(钟形曲线或高斯曲线)分布。
增加 lambda 值将增强正则化效果。 例如,lambda 值较高的权重直方图可能会如图 2 所示。
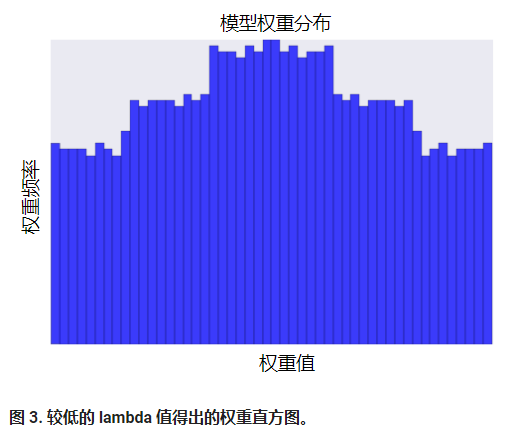
降低 lambda 的值往往会得出比较平缓的直方图,如图 3 所示。
在选择 lambda 值时,目标是在简单化和训练数据拟合之间达到适当的平衡:
- 如果您的 lambda 值过高,则模型会非常简单,但是您将面临数据欠拟合的风险。您的模型将无法从训练数据中获得足够的信息来做出有用的预测。
- 如果您的 lambda 值过低,则模型会比较复杂,并且您将面临数据过拟合的风险。您的模型将因获得过多训练数据特点方面的信息而无法泛化到新数据。
- 将 lambda 设为 0 可彻底取消正则化。 在这种情况下,训练的唯一目的将是最小化损失,而这样做会使过拟合的风险达到最高。
理想的 lambda 值生成的模型可以很好地泛化到以前未见过的新数据。 遗憾的是,理想的 lambda 值取决于数据,因此您需要手动或自动进行一些调整。
了解 L2 正则化和学习速率
学习速率和 lambda 之间存在密切关联。强 L2 正则化值往往会使特征权重更接近于 0。较低的学习速率(使用早停法)通常会产生相同的效果,因为与 0 的距离并不是很远。 因此,同时调整学习速率和 lambda 可能会产生令人混淆的效果。
早停法指的是在模块完全收敛之前就结束训练。在实际操作中,我们经常在以在线(连续)方式进行训练时采取一些隐式早停法。也就是说,一些新趋势的数据尚不足以收敛。
如上所述,更改正则化参数产生的效果可能会与更改学习速率或迭代次数产生的效果相混淆。一种有用的做法(在训练一批固定的数据时)是执行足够多次迭代,这样早停法便不会起作用。
引用
简化正则化 (Regularization for Simplicity):Lambda
最新文章
- 烂泥:python2.7和python3.5源码安装
- MySQL 注册码
- C#解压缩文件
- Volley源码分析(1)----Volley 队列
- JSP学习笔记(一)
- 嵌入式设备上的 Linux 系统开发
- 带您理解SQLSERVER是如何执行一个查询的
- 网易云课堂_程序设计入门-C语言_期末考试编程题
- linux系统的安装
- C# 调用迅雷 7 迅雷下载开放引擎
- vue 修改数据界面没有及时更新nextTick
- 我认知的javascript之函数调用
- C# 如何物理删除有主外键约束的记录?存储过程实现
- SQL Server双机热备之后项目的FailOver自动连接
- jquery遍历table的tr获取td的值
- SQL中树形分层数据的查询优化
- 转:zTree树控件实战篇:针对多个下拉加载zTree树应该如何做出合理的配置
- Python3 input() 函数
- react-navigation的多次点击重复跳转同一页面、不在堆栈路由页面使用navigation方法的解决思路
- Linux的CPU相关知识