整个ssd的网络和multibox_loss_layer
总结说来prior_box层只完成了一个提取anchor的过程,其他与gt的match,筛选正负样本比例都是在multibox_loss_layer完成的
http://www.360doc.com/content/17/0810/10/10408243_678091430.shtml
1.以mobileNet-ssd为例子:https://github.com/chuanqi305/MobileNet-SSD/blob/master/train.prototxt
ssd在6个层上进行了预测,从6个feature map分别做了confidence和location预测,这些预测都是从相应层的feature map做一个1*1卷积,w和h是不变的,但channel会做改变,confidence:prior_num*class_num, location:prior_num*4
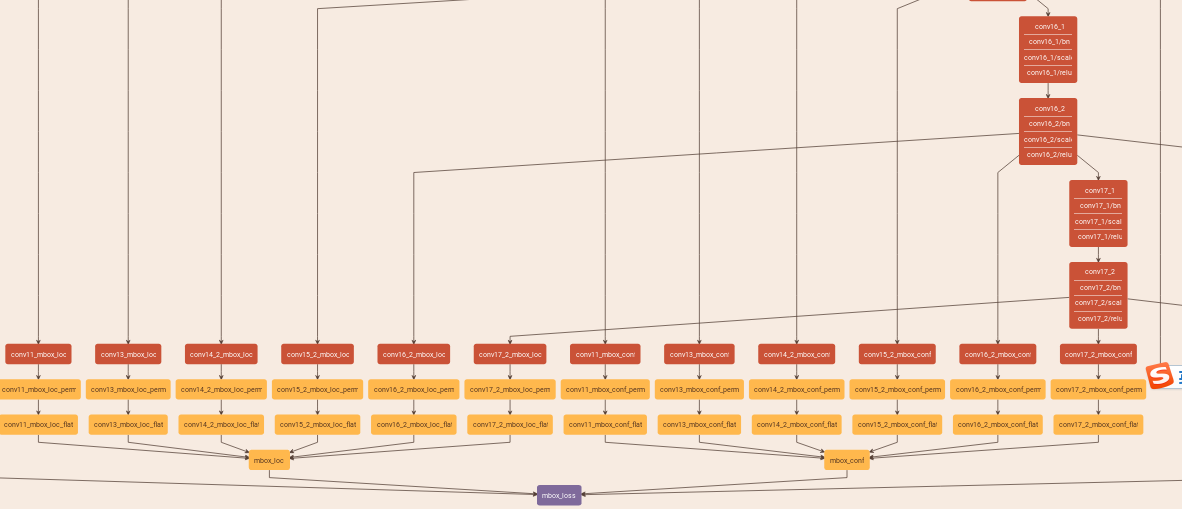
卷积都会经过一个permute层把原来的blob从nchw的顺序变成n,h,w,c,然后在flatten变成n,h*w*c,最后再通过concat把6个预测连接起来,最后就变成了一个一维的blob,比如mbox_conf前4个值代表的是4个prior为第0类的概率,shape的变化可以看下图:
为什么是conv4_3的channel是84,16;fc7的channel是126,24?
84 = 4*21,16 = 4*4
126 = 6*21,24 = 6*4
conv4_3的anchor是4个,fc7的anchor是6个,分类的channel是anchor数*分类数,bouding box的channel是anchor数*4个坐标

https://www.zhihu.com/question/269160464/answer/400342428,这个解释了为什么要进行permute,如果不进行permute直接进行flatten会让prior的值不在连续的存储空间
可以这样理解,flatten从axis=1开始摊开,先摊开的是第四维,摊完之后再是第三维,再是第二维.所以把84所代表的prior换到第四维,就先摊开类别和anchor个数
其实最终这个一维的blob都会对应某一个feature map中的某一个点的某一个anchor
2.https://blog.csdn.net/qianqing13579/article/details/80146425:
* Forward_cpu的主要流程: FindMatches:确定哪些priorbox是正样本,哪些是负样本,存放在all_match_indices_中
MineHardExamples:Minig出符合条件的负样本 计算正样本的定位
loss 计算所有正样本+Mining出来的负样本的分类loss
最后的loss为定位和分类loss的加权和
先GetGroundTruth、GetPriorBBoxes、GetLocPredictions分别得到gt,prior_box和预测的bounding box regression的值,然后FindMatches将prior的坐标和boudingbox坐标相加变成真正的预测框再和gt进行一个匹配.值得注意的是先是从groudtruth box出发给每个groudtruth box找到了最匹配的prior box放入候选正样本集,然后再从prior box出发为prior box集中寻找与groundtruth box满足IOU>0.5的一个IOU最大的prior box(如果有的话)放入候选正样本集,这样显然就增大了候选正样本集的数量.https://www.cnblogs.com/xuanyuyt/p/7447111.html
https://www.cnblogs.com/lillylin/p/6207292.html 然后MineHardExamples根据confidence loss排序,选取loss最大的前面一些并保证正负比1:3进行训练
https://www.sohu.com/a/168738025_717210,这个网页的ssd网络图比较完整,并且是以vgg为backbone,从conv6_1开始是ssd在vgg上添加的网络层,ssd是在6个层进行了预测

其他层都是直接从feature map上直接使用3*3,pad=1,stride=1的卷积生成分类和回归,但conv4_3的分类和回归是先norm了再用的卷积
最新文章
- map() 函数
- UML-用例图
- hdu 1576 求逆元
- 代码-Weka的决策树类J48
- C语言程序设计做题笔记之C语言基础知识(下)
- 修改Oracle数据库用户的密码
- Scala-变量、常量和懒加载
- UML 教程
- python通过openpyxl操作excel
- HDOJ 1004 Let the Balloon Rise (字符串+stl)
- Linux下的串口调试工具——Xgcom
- MATLAB:图像二值化、互补图(反运算)(im2bw,imcomplement函数)
- Laravel 5 插入数据后返回主键ID
- python multiprocess pool模块报错pickling error
- yii Nav:widget 配置参数encodeLabels
- Django 2.0.1 官方文档翻译: 文档目录 (Page 1)
- Windows执行命令与下载文件总结
- WIFI物联网平台微信端开发分享
- Spring AOP声明式事务异常回滚(转)
- Maven------使用maven新建web项目出现问题 项目名称出现红色交叉