Spark集群数据处理速度慢(数据本地化问题)
2024-08-26 08:46:47
SparkStreaming拉取Kafka中数据,处理后入库。整个流程速度很慢,除去代码中可优化的部分,也在spark集群中找原因。
发现:
集群在处理数据时存在移动数据与移动计算的区别,也有些其他叫法,如:数据本地化、计算本地化、任务本地化等。
自己简单理解:
假设集群有6个节点,来了一批数据共12条,数据被均匀的分布在了每个节点,也就是每个节点2条。现在要开始处理这些数据。
一种情况是:某数据由哪个节点处理被随机的分配,类似A节点存了数据1和数据2却可能被要求处理C节点的数据5和数据6,C节点的数据5和数据6就被备份到A节点,而A节点的数据又要备份到其他某一节点用于被处理。集群节点间存在大量数据移动,影响了速度。
另一种情况:某节点自身储存的数据就由自身来处理,比如A节点存储了数据1和数据2,那么数据1和数据2就由A节点来计算,C节点存储了数据5和数据6,那么数据5和数据6就由C节点来计算。这也就避免了数据的移动。
当然实际要比我描述的复杂得多,我的理解肯定也有不对的地方。
浏览器打开spark 8080端口master界面,图中红色箭头处如果显示各机器IP地址那就很有可能会造成移动数据的问题。
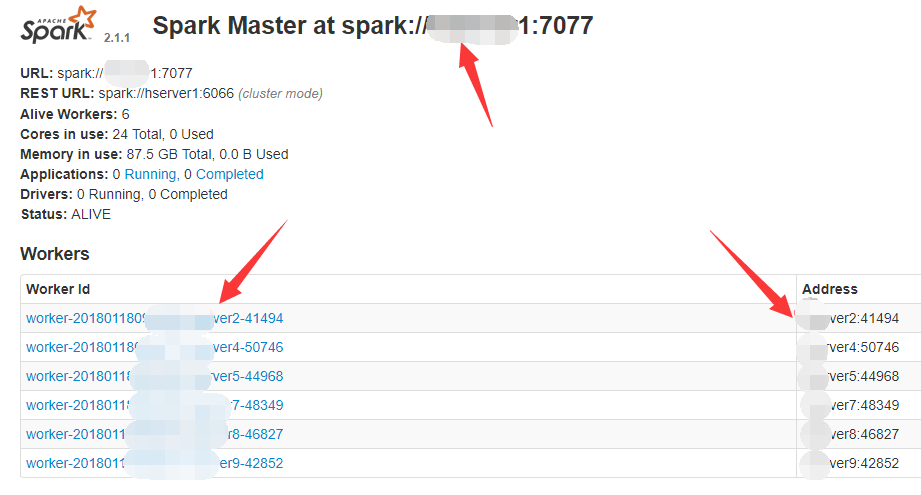
解决:
先停止spark集群,在master机器用 start-master.sh 启动,然后分别在每一台worker机器用 start-slave.sh -h 本机hostname spark://master机器hostname:7077 启动。
过程中可能遇到很多问题,多注意每台机器上的几个文件中的内容是否有问题:/etc/hosts, spark中conf文件夹中spark-env.sh和slaves
最新文章
- Graphviz从入门到不精通
- XML转换JSON的工具使用方法
- JS获取Cookie值
- 当执行php脚本时用户关闭浏览器会发生什么?
- 深入理解HTTP协议、HTTP协议原理分析【转】
- sed实例一则
- 关于Json传递的日期/Date(数字)/解析
- HDU 5637 Transform
- IMPEX
- Redis——windows环境安装redis和redis sentinel部署
- 获取数据库时间sql 以及行级锁总结-共享锁-排他锁-死锁
- java中的取整(/)和求余(%)
- Android Stuido xml使用app属性没有提示代码
- Bean之间的关系
- mysql5.7以上安装
- Fragment与Acitvity通信
- 550 5.7.1 Client does not have permissions to send as this sender
- Codeforces 1038D - Slime - [思维题][DP]
- swift 的相机扫描
- 误删mysql表物理文件的解决方法(不涉及恢复数据)
热门文章
- 本地搭建SVN局域网服务器【转】
- Oracle rman 各种恢复
- [设计模式-行为型]访问者模式(Vistor)
- eclispe新导入的文件有个小红叉号(x)的问题
- 分享HTTP Status 404(The requested resource is not available)的几种解决方案解决方法
- Python与数据结构[3] -> 树/Tree[1] -> 表达式树和查找树的 Python 实现
- Python3 数字
- 去掉Chrome手机版首屏的“推荐的文章”
- 微信小程序开发教程(八)视图层——.wxml详解
- 【动态规划】bzoj1613 [Usaco2007 Jan]Running贝茜的晨练计划