scrapy-splash抓取动态数据例子十四
2024-08-25 08:00:28
一、介绍
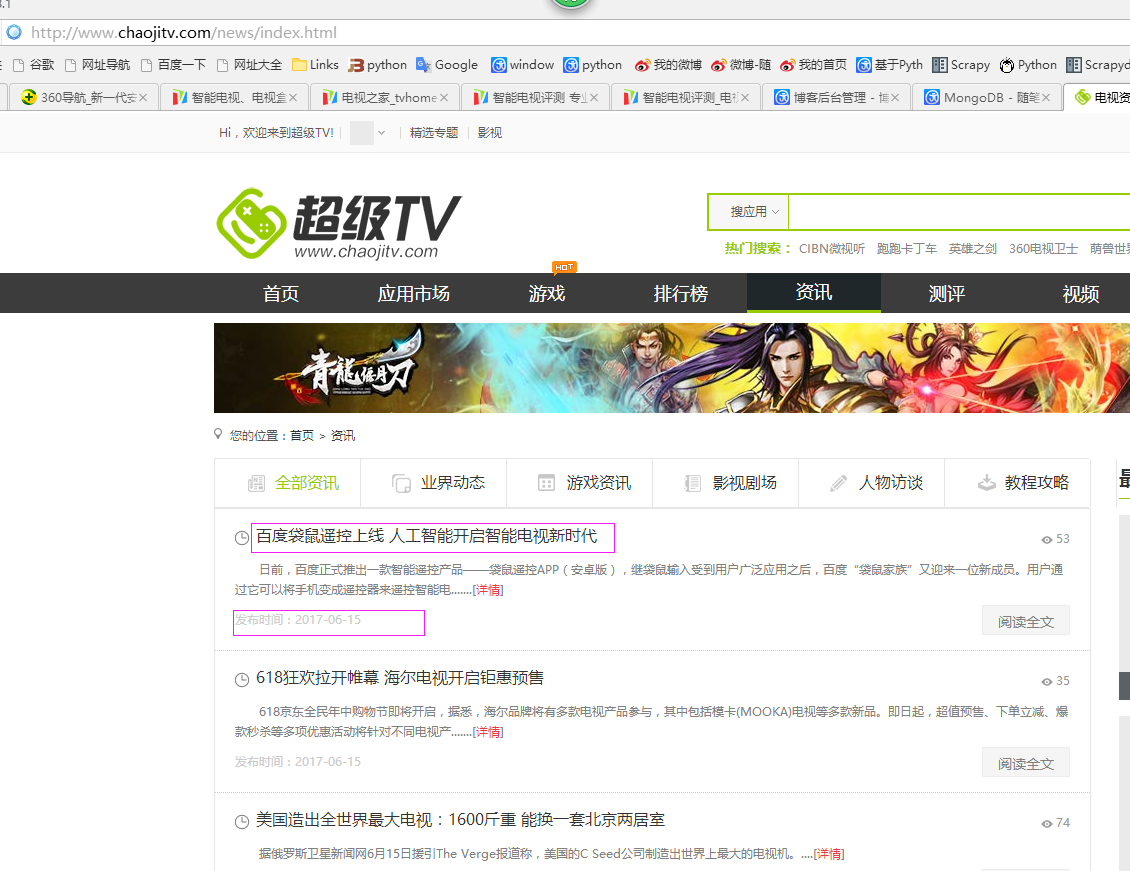
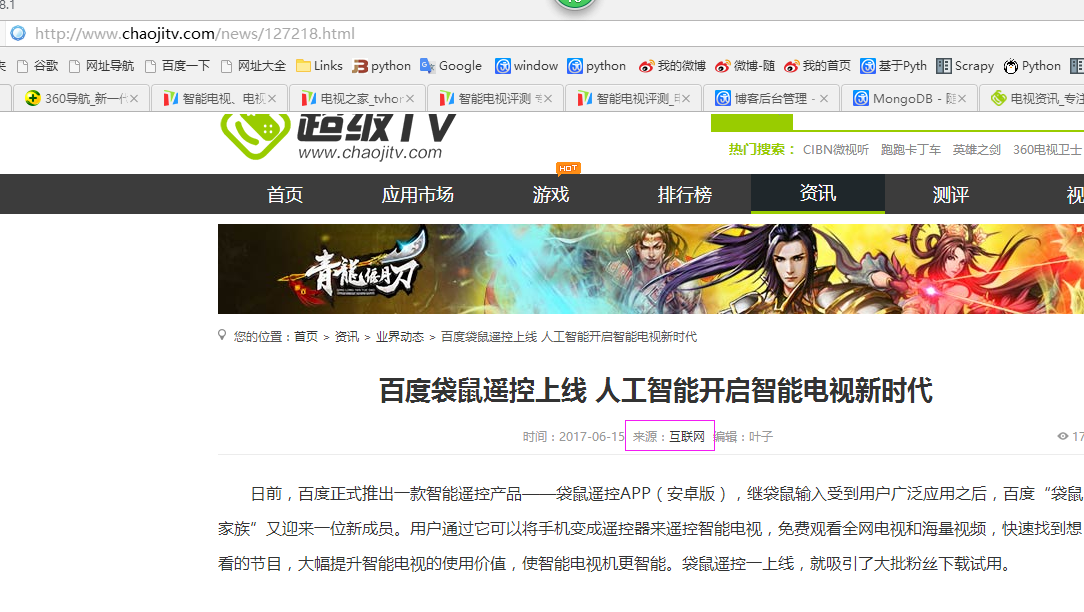
本例子用scrapy-splash爬取超级TV网站的资讯信息,输入给定关键字抓取微信资讯信息。
给定关键字:数字;融合;电视
抓取信息内如下:
1、资讯标题
2、资讯链接
3、资讯时间
4、资讯来源
二、网站信息

三、数据抓取
针对上面的网站信息,来进行抓取
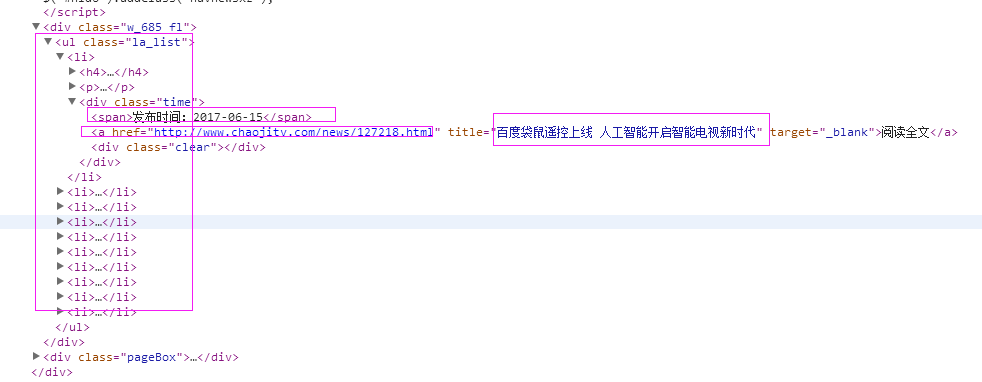
1、首先抓取信息列表
抓取代码:sels = site.xpath('//ul[@class="la_list"]/li')
2、抓取标题
抓取代码:title = str(sel.xpath('.//h4/a/text()')[0].extract())
3、抓取链接
抓取代码:url = str(sel.xpath('.//h4/a/@href')[0].extract())
4、抓取日期
抓取代码:strdates = sel.xpath('.//div[@class="time"]/span/text()')
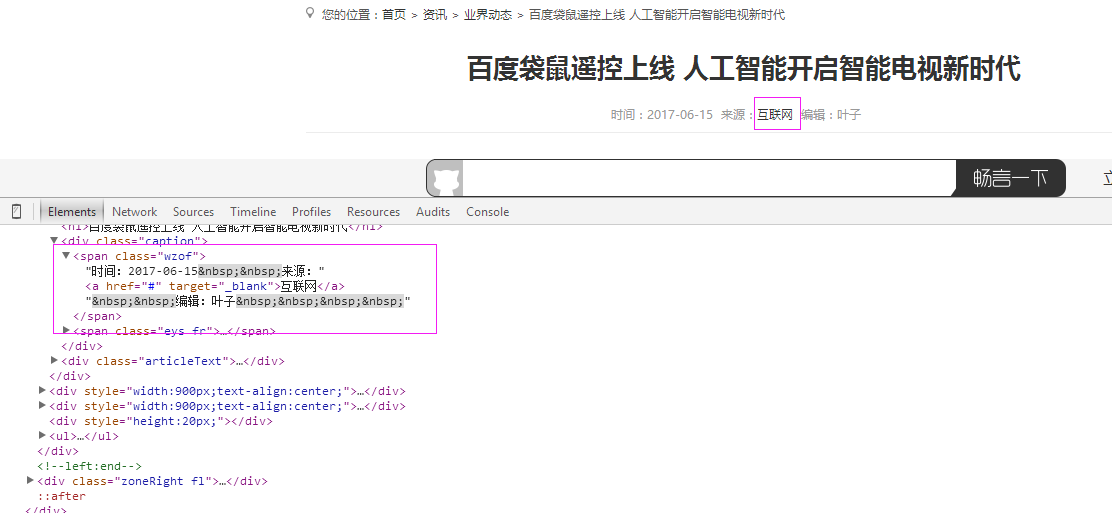
5、抓取来源
抓取代码:sources = site.xpath('//span[@class="wzof"]/a/text()');或sources = site.xpath('//span[@class="wzof"]/text()')
四、完整代码
# -*- coding: utf-8 -*-
import scrapy
from scrapy import Request
from scrapy.spiders import Spider
from scrapy_splash import SplashRequest
from scrapy_splash import SplashMiddleware
from scrapy.http import Request, HtmlResponse
from scrapy.selector import Selector
from scrapy_splash import SplashRequest
from scrapy_ott.items import SplashTestItem
from scrapy_ott.mongoDB import mongoDbBase
import scrapy_ott.IniFile
import sys
import os
import re
import time reload(sys)
sys.setdefaultencoding('utf-8') # sys.stdout = open('output.txt', 'w') class chaojitvSpider(Spider):
name = 'chaojitv'
db = mongoDbBase() configfile = os.path.join(os.getcwd(), 'scrapy_ott\setting.conf')
cf = scrapy_ott.IniFile.ConfigFile(configfile)
information_wordlist = cf.GetValue("section", "information_keywords").split(';')
websearchurl_list = cf.GetValue("chaojitv", "websearchurl").split(';')
start_urls = []
for url in websearchurl_list:
start_urls.append(url) # request需要封装成SplashRequest
def start_requests(self):
for url in self.start_urls:
yield SplashRequest(url
, self.parse
, args={'wait': ''}
)
def Comapre_to_days(self,leftdate, rightdate):
'''
比较连个字符串日期,左边日期大于右边日期多少天
:param leftdate: 格式:2017-04-15
:param rightdate: 格式:2017-04-15
:return: 天数
'''
l_time = time.mktime(time.strptime(leftdate, '%Y-%m-%d'))
r_time = time.mktime(time.strptime(rightdate, '%Y-%m-%d'))
result = int(l_time - r_time) / 86400
return result def date_isValid(self, strDateText):
'''
判断日期时间字符串是否合法:如果给定时间大于当前时间是合法,或者说当前时间给定的范围内
:param strDateText: 四种格式 '2小时前'; '2天前' ; '昨天' ;'2017.2.12 '
:return: True:合法;False:不合法
'''
currentDate = time.strftime('%Y-%m-%d')
datePattern = re.compile(r'\d{4}-\d{2}-\d{2}')
strDate = re.findall(datePattern, strDateText)
if len(strDate) == 1:
if self.Comapre_to_days(currentDate, strDate[0]) <= 1:
return True, strDate[0]
return False, '' def parse(self, response):
site = Selector(response)
sels = site.xpath('//ul[@class="la_list"]/li') for sel in sels:
strdates = sel.xpath('.//div[@class="time"]/span/text()')
if len(strdates)>0: flag, date = self.date_isValid(str(strdates[0].extract()))
if flag:
title = str(sel.xpath('.//h4/a/text()')[0].extract())
for keyword in self.information_wordlist:
if title.find(keyword) > -1:
url = str(sel.xpath('.//h4/a/@href')[0].extract())
yield SplashRequest(url
, self.parse_item
, args={'wait': ''},
meta={'date': date, 'url': url,
'keyword': keyword, 'title': title}
) def parse_item(self, response):
site = Selector(response)
it = SplashTestItem()
it['title'] = response.meta['title']
it['url'] = response.meta['url']
it['date'] = response.meta['date']
it['keyword'] = response.meta['keyword']
sources = site.xpath('//span[@class="wzof"]/a/text()')
if len(sources)>0:
it['source'] = sources[0].extract()
else:
#时间:2017-06-15 来源:环球网 编辑:叶子
sources = site.xpath('//span[@class="wzof"]/text()')
if len(sources)>0:
ss= str(sources[0].extract()).split(':')
if len(ss)>2:
it['source']= ss[2].replace(u'编辑: ','').replace(' ','') self.db.SaveInformation(it)
return it
最新文章
- RBAC中 permission , role, rule 的理解
- OSX的一些基本知识
- SQLserver2008数据库备份和还原问题(还原是必须有完整备份)
- OKHttp的容易使用
- USACO 5.5 Hidden Password(搜索+优化)
- C# (事件触发)回调函数,完美处理各类疑难杂症!
- PKCS10生成证书csr
- struts中的helloword(1)
- C语言的一个关键字——static
- sql server基本流程语句
- Java设计模式(四) 装饰 代理模式
- ASP.NET Zero--3.菜单配置
- Android:关于背景选择器Selector的item顺序
- OSI参考模型各层的主要功能
- Linux中的grep命令
- Centos6.10部署TeamViewer
- Mac OS X 清除DNS缓存
- PL/SQL学习笔记之游标
- java中的Sort函数,你值得看
- WPF Demo13 GridSplitter