【尺度不变性】An Analysis of Scale Invariance in Object Detection – SNIP 论文解读
前言
本来想按照惯例来一个overview的,结果看到1篇十分不错而且详细的介绍,因此copy过来,自己在前面大体总结一下论文,细节不做赘述,引用文章讲得很详细,另外这篇paper引用十分详细,如果做detection可以从这篇文章去读更多不同类型的文章。
论文概述
卷积网络具有较好的平移不变性,但是对尺度不变性有较差的泛化能力,现在网络具有的一定尺度不变性、平移不变性往往是通过网络很大的capacity来“死记硬背”,小目标物体难有效的检测出来,主要原因有:1.物体尺度变化很大,CNN学习尺度不变性较难。2.通常用分类数据集进行预训练,而分类数据集物体目标通常相对较大,而检测数据集则较小。这样学习到的模型对小物体更难有效的泛化,存在很大的domain-shift。3.有的CNN的卷积核stride过大,小尺度中的小物体很容易被忽略,下图可以很好的体现这一问题。
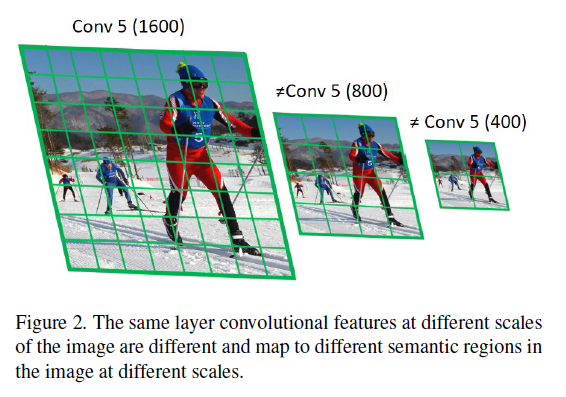
人们提出了一些解决小目标识别的问题,作者也分别进行分析,实验:
- 使用空洞卷积(dilated/atrous convolution)。减小stride的,增加feature map大小,但不会减小感受野的大小。这样做不影响检测大目标的性能
- 训练时将图像放大1.5到2倍,预测时,放大4倍
- 使用CNN中不同层的特征分别进行预测,浅层负责检测小目标,深层负责检测大目标
- 深浅层特征结合进行预测,使浅层特征结合深层的语义特征,如FPN。但当目标尺寸较小时,如25x25,特征金字塔生成的高层语义特征也可能对检测小目标帮助不大
作者的第一个实验证明了当训练图片的尺度与测试图片的尺度相差较大时性能会很差,越接近性能越好,具体可以看下图。另外作者比较了一个新的网络(CNN-S)来专门针对小目标检测(如小卷积核,减少stride)与在低分辨率的数据集上来fine-tuning高分辨率训练训练的检测器之间的性能,发现与其设计针对小物体的网络不如按到传统pre-trained模型在低分辨率的数据集进行微调(这个实验好像对文章主旨没什么用?),实验结果具体如下:

对于小目标检测困难的原因,最容易想到的解决方法就是放大图片,让小物体变大,从而不在卷积过程中丢失太多信息,作者也就此做了实验,发现提升并不明显,作者分析原因是放大图片小物体变大,中-大的物体也变大了,从而较难分类,所以整个分类器性能下降。因此,作者又设计了一组实验。使用1400分辨率进行训练,同时忽略原图中的中大目标(大于80像素)。然而,结果更差了。作者分析,这样做忽略了很多中-大目标(30%左右)的外形特征,pose之类的特征,特征减少对网络的学习能力产生了影响。作者又尝试训练具有尺度不变特性的检测器。随机采样图像,用不同分辨率的图像进行训练(Multi-Scale Training, MST),虽然包含了各类物体的各种尺度,物体特征较多,然而效果也不太好,原因是随机采样,会出现极大极小的样本,影响训练效果,又回到了最初的问题。因此作者得出结论:图像缩放后,使用尺度接近的目标来训练分类器很重要。
然后SNIP登场了!
作者提出,在训练时,既希望训练数据有尽可能多的外观变化以及多种不同的尺度来提高大/小物体的检测能力,又想训练的尺度与预训练的尺度较为接近从而提高检测器的性能同时减少domain-shift。因此作者提出了SNIP训练方法,使用MST(多尺度图像训练)方法时,只训练目标尺度在特定范围(与预训练的图像尺寸接近)的图像,在反向传播时,忽略其他过大过小的图像。实验表明,效果比其他训练方法都好。
网络图如下:
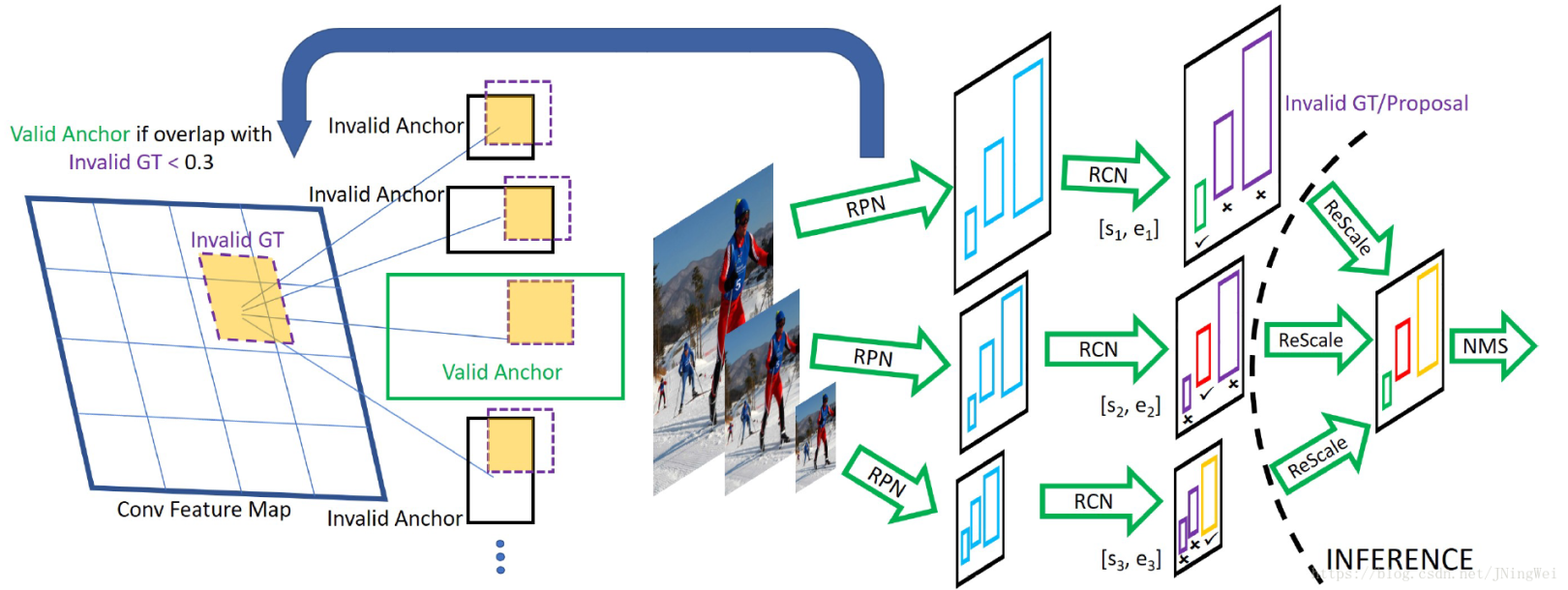
从上图可以发现:(转自:点击打开)
- 每个pipe-line的RPN只负责一个scale range的proposal生成。
- 对于大size的feature map,对应的RPN只负责预测被放大的小物体;对于小size的feature map,对应的RPN只负责预测被缩小的大物体;这样的设计保证了每个CNN分支在判别proposal是否为前景时,只需针对最易分类的中等range的proposal进行训练。
- 在Image Pyramid的基础上加入了 每层scale 的 proposal有效生成范围,发扬本scale的优势,回避其他scale的劣势,大大降低了前景分类任务的难度,从而“作弊式”地实现了Scale Invariance。
two-stage的检测器,包括RPN提取proposals,对proposals分类和bbox回归两个阶段,规则如下:
- 在分类阶段,训练时,不选择那些proposals和GT boxes在特定大小范围外的。
- RPN阶段,和无效GT boxes(大小不在范围内)的IoU大于0.3的anchor认为是无效的,忽略这些anchor。
- 在测试阶段,使用多个分辨率的图像进行检测;在分类阶段,去除那些回归后bboxes大小不在特定范围的检测结果。然后使用Soft-NMS将不同分辨率图像的检测结果合并。
训练图像采样方法
为了降低训练对GPU内存的要求,作者将原图进行裁剪,处理过程如下。
目标是在原图裁剪尽可能少的1000x1000的区域,并且这些裁剪区域包含所有的小目标
具体方法:
- 选择一幅图像
- 随机生成50个1000x1000的裁剪区域
- 选择包括目标最多的裁剪区域
- 如果所有裁剪区没有包含原图所有的目标,继续 (2)
- 由于很多目标在原图边界,再加上是随机裁剪,为了加快速度,裁剪时,保证裁剪区域的至少一个边在原图边界上。对于分辨率小于1000*1000的,或者不包含小目标的图像,不处理。
并且作者通过实验证明,裁剪原图不是提高精度的原因。
训练细节
对于预训练的分类器,通常训练图像大小为224x224。为了尽可能减少domain-shift,训练检测器时,我们期望proposals的大小与预训练时差不多。因此作者设定了如下的有效范围,注意的是COCO数据集中的图像大多在480x640左右。
左为训练图像分辨率,右为原图中有效尺寸的范围,使用了三种尺度进行训练:
1400x2000,[0,80]
800x1200,[40,160]
480x800,[120,∞]
假设原图短边尺寸为480,经过简单计算可知,有效尺寸映射到训练图像的分辨率上,边长为200左右,与预训练图像尺寸接近。
本文提出了一种训练方法:图像金字塔尺度归一化(Scale Normalization for Image Pyramids, SNIP),该方法使用图像金字塔来训练网络,并根据目标大小选择性的反向传播梯度,使得训练时的scale与原始图片的scale相近,从而提高准确率减少domain-shift。
引用文章1
以下内容来自:http://lowrank.science/SNIP/
这篇日志记录一些对下面这篇 CVPR 2018 Oral 文章的笔记。
Singh B, Davis L S. An Analysis of Scale Invariance in Object Detection–SNIP[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2018: 3578-3587.
论文链接:https://arxiv.org/abs/1711.08189
代码链接:https://github.com/bharatsingh430/snip
论点
论文一开始作者摆了个事实,对于 Image Classification 已经能够做到 super-human level performance 了,但是 Object Detection 还差得很远很远,所以作者问了一个问题:Why is object detection so much harder than image classification?
作者给出的解释是 Large scale variation across object instances,这个 scale variation 不仅仅存在于要 apply 的 target dataset 自身内部,还存在与 pre-trained dataset 和要 apply 的 target dataset 之间。
- 对于要 apply 的 target dataset 自身内部的 extreme scale variation,作者给了下面这张图来说明。纵坐标的 CDF 是 Cumulative Distribution Function,累积分布函数;这个 Relative Scale 应该就是 Object 应该是长或宽,占据图像的长或宽的比例。从这张图上能看出,COCO 的大部分目标集中在 relative scale 0.1 之下,面积小于 1 %。这里其实有两个问题:
- 一个是目标本身很小,怎么样才能比较好的特征表示小目标,也就是让 CNN 本身能检测出小目标。
- 另一个问题是,因为 COCO 里面大部分都是小目标,而小目标因为很小,所以彼此之间尺度的倍数其实很大,scale 为 0.0001 的和 scale 为 0.1 的之间差了 1000 倍,但因为一半的目标都集中在 0.1 一下,所以特别小的尺度的其实也有大量目标,并不能被忽略。也就是说是大量、数目不可忽略的 very small objects 的存在,使得 object detection 数据集上的 scale variation 很大。所以对于 COCO,就要求 CNN 必须要有在极小的 scale 和 很大的 scale 上(这两者之间的比例值很大,比如 0.0001 vs 0.9)之间的目标都有很好的分类能力才会有很好的性能,也就要要有对 extreme scale variation 的鲁棒性,即 scale-invariant。

- 对于 pre-trained dataset 和要 apply 的 target dataset 之间的 scale variation,作者给了 domain-shift 这个名词来形容。ImageNet 是用来图像分类的,目标一般 scale 比较大,而 object detection 数据集中的目标的 scale 差异就很大了。在 ImageNet 这种大目标数据集上 pre-trained 的 features,直接用在检测 object detection 中的那些小目标,可以预期到效果并不会很好,这就是 domain-shift 造成的。
归根到底,object detection 目前做不好,还是因为有大量 very small objects 存在的本身,而 small objects 检测很难,因为:
- small objects 因为 small,内部 scale 就差异很大(倍数,因为分母很小,一除就会很大),检测器需要很强的 scale-invariance 能力,而 CNN 就其设计本身其实是没有 scale-invariance 的;
- small objects 本身 small,在 ImageNet 这样 Median Scale Objects 为主的 Datasets 上 Pre-trained 的 Features 直接用来 Detect Small Objects 效果不好,因为 domain-shift。
- CNN 抽取 semantic feature 导致的 coarse representation 和 detect small objects 需要 fine resolution 之间的矛盾,small objects 因为 small,很难在 coarse representation 还有很好的表示,很可能就被忽略了
- The deeper layers of modern CNNs have large strides (32 pixels) that lead to a very coarse representation of the input image, which makes small object detection very challenging.
- 所以本质上是因为 strides 太大导致的 原图像 的表示是非常 coarse 的表示,在这种 coarse 的表示中,小目标本身很容易就会被忽视掉了
- 实际上这个问题,在 Semantic Segmentation 中也是存在的,我们希望能够有既是 Fine Resolution 又是 Semantic 的表示,这也是为什么后面的一些改进方法和 Semantic Segmentation 方法做法相同的原因。
为了 alleviate 由 scale variation 和 small object instances 本身导致的问题,目前大概有下面这些思路:
- features from the layers near to the input, referred to as shallow(er) layers, are combined with deeper layers for detecting small object instances [23, 34, 1, 13, 27],
- 典型代表是 FPN、SSD
- 这个路线其实用来处理上面的难点 3,coarse representation vs fine resolution 的
- 但作者点出了 the high level semantic features (at conv5) generated even by feature pyramid networks will not be useful for classifying small objects,高层特征没用如果目标小,这个很合理,因为这个途径并没有来处理难点 1 和 难点 2 所以当然束手无措
- dilated/deformable convolution is used to increase receptive fields for detecting large objects [32, 7, 37, 8]
- 这个路线也是用来处理上面的难点 3,为了最后有一个 fine resolution 的 representation
- independent predictions at layers of different resolutions are used to capture object instances of different scales [36, 3, 22]
- 这个路线还是用来处理上面的难点 3,做 Prediction 的时候能够在合适的 Feature 抽象程度(Resolution)上做
- context is employed for disambiguation [38, 39, 10]
- 这个不了解,需要去看论文
- training is performed over a range of scales [7, 8, 15] or, inference is performed on multiple scales of an image pyramid
- 这条路线对于小目标来说其实也就是 上采样,很暴力但也很有效,同时来处理上面的难点 1 scale variation 和 难点 3 目标太小在 coarse representation 中残留不多的问题,当然这种方式也有问题,这个会在后面讨论
- predictions are combined using nonmaximum suppression [7, 8, 2, 33]
总之,检测小目标,要么解决问题,也就是对小目标做很好的特征表示,要么消灭问题本身,把小目标消灭掉,统统 upsampling 成大目标,在对小目标进行 scale-invariant 的特征表示束手无策的情况下,upsampling 似乎就成了比较可行的方案了。不过还需要有很多问题要搞清楚:
- upsampling 到底有没有用?
- 到底要怎么做 upsampling?
- 要对谁做 upsampling?只对 training,还是只对 test,还是都做?
- 如果都做 upsampling,彼此又该怎么用?都遍历所有尺度么?还是要固定尺度,为了和 pre-trained datasets 的尺度一致。
对应到作者原文中,作者问的是下面两个问题:
- Is it critical to upsample images for obtaining good performance for object detection? Even though the typical size of images in detection datasets is 480x640, why is it a common practice to up-sample them to 800x1200? Can we pre-train CNNs with smaller strides on low resolution images from ImageNet and then fine-tune them on detection datasets for detecting small object instances?
- When fine-tuning an object detector from a pre-trained image classification model, should the resolution of the training object instances be restricted to a tight range (from 64x64 to 256x256) after appropriately re-scaling the input images, or should all object resolutions (from 16x16 to 800x1000, in the case of COCO) participate in training after up-sampling input images?
在本文中,作者依次回答了上面这些问题:
- 首先,up-sampling 对于 small object detection 来说非常重要,这也是为什么对于 detection datasets, it is a common practice to up-sample 480x640 to 800x1200。
- pre-train CNNs with smaller strides on low resolution images from ImageNet 然后再 fine-tune them on detection datasets for detecting small object instances 这种是方式是可以的而且是本文提倡的,只不过 fine-tuning 和 test 都要在本文提出的特殊的 Pyramid 上做
- 为了消除 domain-shift,在做 fine-tuning 的时候,需要将 training object instances 大小限制在 a tight range (from 64x64 to 256x256) 以保持与 pre-trained datasets 的 object scales 一致这种方式效果最好,而不是 all object resolutions (from 16x16 to 800x1000, in the case of COCO) 都参与到训练中。
因此,综上所述,本文的贡献或者说 argument 就在于提倡训练 detector 的时候要用 Pyramid,但只有固定尺度内的目标才被拿来参与训练,作者把这种训练方式叫作 Scale Normalization for Image Pyramids (SNIP)。本文本质上是一篇讨论怎么来使用 Image Pyramid 的论文,故而后面的论文都是比较不同的 Image Pyramid 使用方式的。
最典型的就是下面两种使用方式:
- scale-specific detectors:variation in scale is handled by training separate detectors - one for each scale range.
- 一个 detector 负责一个 scale 的 objects
- 这里的样本应该是没有做过 Image Pyramid 的 Datasets,这样的话,对于每个 scale 来说,样本数量就减少了,训练样本少了,对于训练一个 detector 来说,并没有把全部的 samples 用上
- scale invariant detector:training a single object detector with all training samples
- 这个虽然叫作 scale invariant detector,其实不过只是一个美好的期许而已,实际上 CNN 本身是没有 scale invariance 这个性质的。即使最后表现出了一定的能够检测 multi-scale object 的能力,但这只是「『假象』,那不过 CNN 是用其强大的拟合能力来强行 memorize 不同 scale 的物体来达到的capacity 来强行memorize 不同 scale 的物体来达到的capacity,这其实浪费了大量的 capacity」[1],也就是说 capacity 并没有被用到该用的地方去
所以,这里就有一个取舍了,scale-specific detector 没有用上全部 samples 可能会导致性能不佳;scale invariant detector 浪费了大量的 capacity 来强行 memorize 不同 scale 的物体,而不是用来学习语义信息,也会导致性能不佳。最好的当然是,不做取舍,两个都要,即能用上全部 samples,而且不将 capacity 浪费在强行 memorize 不同 scale 的物体上。实际上,这个是可以做到的。
本文的 SNIP,通过 Image Pyramid,使得每个 Object 都能有一个落在与 Pre-trained 的 ImageNet 数据集的 Scale 相同的表达,并且只对经过 Image Pyramid 后与 Pre-trained 的 ImageNet 数据集的 Scale 相同的 Sample 进行训练,既保证了用上全部 samples,又将capacity 都用在了学习语义信息上。
论证
作者在「3. Image Classification at Multiple Scales」和「5. Data Variation or Correct Scale?」两处安排了两个论证实验。
Fining-tuning, whether or not?
「3. Image Classification at Multiple Scales」这一节研究 domain shift 的影响,除此之外,作者其实还要回答另外一个问题,那就是既然 domain-shift 有影响,那还要不要采用 fine-tuning 这种方式,也就是拿 pre-trained weights 做初始化,直接在 object detection 的 target dataset 上 train from scratch 不好吗?
作者安排了三个论证实验,最后证明了即使有 domain shift,还是应该要采用 pre-trained + fine-tuning 这种方式。也就是回答了作者一开始提出来的问题:
Can we pre-train CNNs with smaller strides on low resolution images from ImageNet and then fine-tune them on detection datasets for detecting small object instances?
答案是 yes, we can.
此外,其实 domain shift 不仅仅是在 pre-trained datasets 和 target datasets 之间存在,其实我们在做 Test 的时候,为了检测小目标通常会做 Image Pyramid,会缩小、放大图像,这个时候,Test 的 Pyramid 里面的 object 也会跟 Training 时候的 object scale 不一致,所以这里就提醒我们一点,在使用 Image Pyramid 的时候还要考虑 domain shift 的影响。
因此,Pre-trained Data 与 Training Data 之间有 domain shift,Training Data 与 Test Data 之间也会有 domain shift. 但这两个虽然都叫 Domain Shift,其实还有点不同,Pre-trained Data 与 Training Data 之间有 domain shift 是由于 Object 在原有 Resolution 下本身的 Scale 分布造成的;而 Training Data 与 Test Data 之间的 domain shift,则是由 Test 时候采用 Image Pyramid 造成的。
Naive Multi-Scale Inference
- 这个实验所采用的是直接拿在 Full Resolution 的数据集上得到的 Pre-trained Weights 拿来应用于 Target Dataset,不做 Fine-tuning。
- 但是对于 Detection,这个实验的启示是 Training Data 与 Test Data 之间由于 Image Pyramid 造成的 domain shift 的影响。
- 这个实验是在原尺寸的 ImageNet 上 Training,然后在经过 down-sampling 再 up-sampling 的图像上做 Test;
- 对原图像做 down-sampling 是为了获得 low-resolution 的图,再把 low-resolution 的图 up-sampling 成跟 training image 一样大小是为了模拟 Pyramid 里面的 up-sampling 的行为,因为 Detection 最后还是对一个 Region Proposal 的区域做 Classification,因此,这个实验虽说是在审视 Training Set 和 Test Set 在 Resolution 上的差异对 Classification 的影响,但其实也解释了做 Detection 的时候,Training Set 和 Test Set 在 Resolution 上的差异的影响。
- 这里的 Resolution 指的是图像的清晰程度。
- 结论自然是 Training Set 和 Test Set 的 Resolution 差异越大,效果越差,因此要保证 Training Set 和 Test Set 的 Resolution 一致。
说明直接放大小物体去测试是不行的,是要把放大后的小物体真正参与到训练里。
Resolution Specific Classifiers
- 这个实验所采用的是直接在 Low Resolution 的 Target Dataset 上 Training from scratch,不做 pre-training。
- Naive Multi-Scale Inference 这个 Network 是应用于 Full Resolution 数据的网络,网络本身相对复杂,CNN-B 的 B 应该是 Base 的意思吧,也就是基准网络,模拟的是在 Full Resolution 上训练的基准网络在 Low Resolution 图像上测试的效果。
- Resolution Specific Classifiers 这个 Network,是在 Low Resolution 数据上训练并在 Low Resolution 数据上测试,但是为了能够让网络应用在 Low Resolution 的图像上,采用的是 Simplified network,所以叫 CNN-S。此时,虽然 Training Data 和 Test Data 的 Resolution 一致了,但是因为 Network 简单了,capacity 弱了,也会造成预测效果不好。
- 这时候就要看,究竟是 简化网络造成的预测效果不好影响大,还是 Training 和 Test 数据的 Resolution 不一致的 Domain Shift 对预测效果不好的影响大了,从实验结果上看,CNN-S 远好于 CNN-B,注意这里的前提是 数据充足。
- 因此可以得到的结论是,在数据充足的前提下,Domain Shift 会造成很大的性能损失,也就是说 CNN 并没有学习 Scale Invariance 的能力,可以遇见即使在 Image Pyramid 做 Test 的时候,CNN 对于在 Training 没见过的 Scale 的 Object 的时候,效果会很差,这其实也说明了一定要让 Training Data 和 Test Data 在一个尺度的重要性。
Fine-tuning High-Resolution Classifiers
- 这个实验所采用的是先在 Full Resolution 的 Pre-trained Dataset 上做 Pre-training,然后再在 Low Resolution 的 Target Dataset 上做 Fine-tuning。当然为了输入网络,Low Resolution Image 要做下 Upsampling.
- 因为这个是在 CNN-B 的基础上做了 Fine-tuning,因此叫作 CNN-B-FT。
- CNN-B-FT 的效果明显好于 CNN-S,这说明为了 Low Resolution Data 去削足适履采用 low capacity 的简单网络,不如还是采用 Pre-trained on Full Resolution Dataset + Fine-tuning on Low Resolution Dataset 这种方式。
- 其实这是很合理的,相比 Learning from Scratch 的随机初始化权重,Pre-trained weights 至少给了一个合适的权重初始化。反正最后还是要在 Target Dataset 上做。但要注意,Fine-tuning 的时候,Target Dataset 是被 up-scaling 了跟 Pre-trained Dataset 一样的大小。这样做应该是为了保证 pre-trained datasets 和 target datasets 之间的 object 大小一致。
Fine-tuning, how?
Training on 800 x 1400,test on 1400 x 2000
- 这个是模拟仅仅 inference is performed on multiple scales of an image pyramid;在 800 x 1400 的图片上 Training,然后在 1400 x 2000 上的图片上做 Test 是为了检测小目标常常采用的是策略。
- 这是基准,后面的都要跟这个比,这个叫做 800-all。
Training on 1400 x 2000,test on 1400 x 2000
- 这个 upsampling 了 小目标,而且 Training 和 Test 在同一尺度上,但最后的效果仅仅比 800-all 好了一点点,可以忽略的一点。
- 作者给的话就是 up-sampling 会 blows up the medium-to-large objects which degrades performance,median size object become too big to be correctly classified!
- 我自己的理解是 up-sampling,虽然减小了小目标在 target dataset 与 pre-trained dataset 之间 domain shift,但是又增加了 medium size 的 objects 在 target dataset 与 pre-trained dataset 之间 domain shift,大量 median objects 变成了超大目标, scale 和 ImageNet 这样的 pretrained dataset 上大部分目标的 scale 不一致
Scale specific detectors
- 为了去除 Scale Variation 让 CNN 把能力都用在 Memorizing 而不是 Learning Semantic 上带来的性能下降,作者只对一定 scale 的小目标做了训练,也就是没有了 scale variation,但 training data 的数量减少了。
- 实验结果表明,这比 800-all 的效果还要差,因为去除掉了 median-to-large 的 objects,并不有利于 CNN 学习语义,也就是说,去掉一些 scale 的样本不利于学习语义,塞给 CNN 各种 scale 的样本让它去强行记忆也不利于 CNN 学习语义。
单纯只用小物体效果也不好是因为数据不足,大物体其实对于语义信息是很有帮助的。你只用了部分数据还不如全用了虽然用的不特别好。
Multi-Scale Training (MST)
- 用 Image Pyramid 生成多个 Resolution,然后用一个 CNN 去 fit 所有这些不同 Resolution 的 object,最后的结果是跟 800-all 差不多。
- 说明 CNN 没有学习 Scale Invariance 的能力,强行让它记住不同尺寸的目标,会损害它 Learning Semantic 的能力,从而虽然 Data 经过 Image Pyramid 数量增加了会带来一点增益,也随着 Learn 到的 Semantic 能力的损失下降了。
- 这要要求我们理想的 detector,即能够利用上所有的样本,但喂它的这些样本又能够都处于合适的尺度内,从而能够让 CNN 把能力都放在 Learning Semantic Information 上。
所以由 DNN 学到的特征不具有: 旋转不变性,尺度不变性?都是数据堆起来的假象,或者说是通过 capacity 由不同 neuron 死记硬背
结论
- 对于 Scale-Variation,有两种思路,一种是增大学到 Scale-Variation 的能力,从而能够 handle Scale-Variation,另一种是 减少面对数据中的 Scale-Variation,这样就相当于把任务给 simplified 的了。作者采用了后面一种,可以说是简单粗暴,也可以说是治标不治本。
- 如果要想赋予 CNN 尺度不变性,还是要考虑怎么样的结构在设计上考虑了 scale invariance,以及怎么从 data 中抽取出或者说学习到这个 scale invariance。
- 除了尺度不变性,CNN 其实也学不到旋转不变性,如果你的 target dataset 里面旋转不变性很重要,那可以考虑采取跟本文一样的操作。
感想
我很喜欢这篇文章,它给了我们这些做应用的人一个清晰的怎么做应用研究的范式。通过仔细分析现在存在的问题背后的原因,然后找出可以解决这个问题的手段,而不是堆叠一些 fancy 时髦的东西,是值得我学习的榜样
最新文章
- Unicode转义(\uXXXX)的编码和解码
- jquery验证手机号码和固定电话号码
- 一个简单驱动的makefile
- UISwitch(开关控件)、UISegmentedControl(分段控件)
- Promises与Javascript异步编程
- 一步一步制作yaffs/yaffs2根文件系统(七)---真挚地道歉以及纠正前边出现的错误!
- Swift中共有74个内建函数
- js的水仙花数的输出
- KSImageNamed-Xcode
- pager-taglib插件进行普通分页
- 学习ActiveMQ(二):点对点(队列)模式消息演示
- 回文的范围——算法面试刷题2(for google),考察前缀和
- 指定的经纬度是否落在多边形内 java版
- css的再深入9(更新中···)
- 开源一个最近写的spring与mongodb结合的demo(spring-mongodb-demo)
- 使用 Trace 将日志输入到文件中
- 20165310 学习基础和C语言基础调查
- 2018.10.18 poj2187Beauty Contest(旋转卡壳)
- JS知识点整理(二)
- jbpm角色审批