正排索引(forward index)与倒排索引(inverted index)
正常的索引一般是指关系型数据库里的索引。 把不同的数据存放到不同的字段中。如果要实现baidu或google那种搜索,就需要与一条记录的多个字段进行比对,需要 全表扫描,如果数据量比较大的话,性能就很低。
那反过来,如果把mysql中存放在不同字段中字符串,按一定规则拆分成term【词】存放到 一个字段中【套用mysql中的表结构,实际上不是这样处理的】,然后把这些词存放到一个字段中,并在这个字段建立索引。
这样一来,搜索时,只需要查 带有索引的这列就可以了【这一点和关系型数据库 field_name='xxx'一样了】,这一步解决了效率问题
这个term对应所在记录,中这个term所在的原始记录,这一步解决了获取源内容的问题
正排索引(forward index)与倒排索引(inverted index)
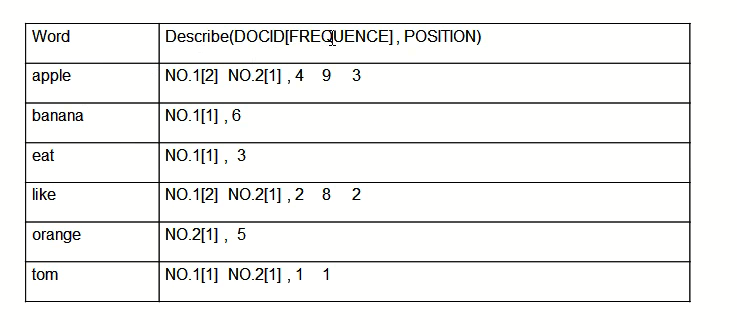
正排索引(前向索引) 正排索引也称为"前向索引"。
正向索引的结构如下:
“文档1”的ID > 单词1:出现次数,出现位置列表;单词2:出现次数,出现位置列表;…………。
“文档2”的ID > 此文档出现的关键词列表。

一般是通过key,去找value。
当用户在主页上搜索关键词“华为手机”时,假设只存在正向索引(forward index),那么就需要扫描索引库中的所有文档,找出所有包含关键词“华为手机”的文档,再根据打分模型进行打分,排出名次后呈现给用户。因为互联网上收录在搜索引擎中的文档的数目是个天文数字,这样的索引结构根本无法满足实时返回排名结果的要求。
所以,搜索引擎会将正向索引重新构建为倒排索引,即把文件ID对应到关键词的映射转换为关键词到文件ID的映射,每个关键词都对应着一系列的文件,这些文件中都出现这个关键词。
得到倒排索引的结构如下:
“关键词1”:“文档1”的ID,“文档2”的ID,…………。
“关键词2”:带有此关键词的文档ID列表。

从词的关键字,去找文档。
官网
https://www.elastic.co/guide/en/elasticsearch/reference/5.x/analysis.html

官网,提供了很多很多。大家自行去看!
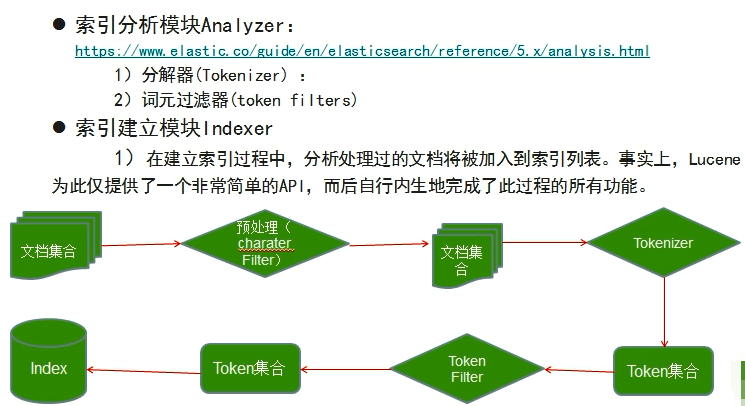
索引分析模块Analyzer
分解器Tokenizer
词元过滤器token filters

经过 Tokenizer

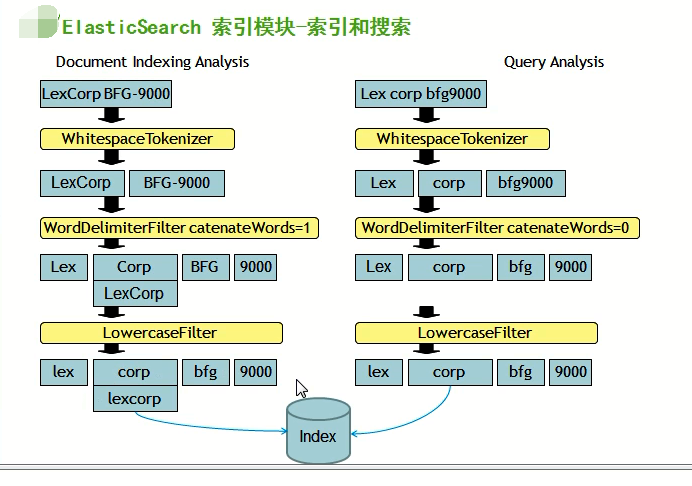

Elasticsearch之IKAnalyzer的过滤停止词
大家,有兴趣,可以看看,英文停用词
http://www.ranks.nl/stopwords
大家,有兴趣,可以看看,中文停用词

Elasticsearch之中文分词器

Elasticsearch之几个重要的分词器
作者:大数据和人工智能躺过的坑
出处:http://www.cnblogs.com/zlslch/
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文链接,否则保留追究法律责任的权利。 如果您认为这篇文章还不错或者有所收获,您可以通过右边的“打赏”功能 打赏我一杯咖啡【物质支持】,也可以点击右下角的【好文要顶】按钮【精神支持】,因为这两种支持都是我继续写作,分享的最大动力!
最新文章
- 使用java泛型设计通用方法
- How to configure a static IP address on CentOS 7(CentOS7静态IP地址设置)
- 【extjs】:获取列名,时间转换
- CodeSmith 使用说明
- Timer
- Java中基本数据类型的存储方式和相关内存的处理方式(java程序员必读经典)
- android学习——error opening trace file: No such file or directory (2)
- web设计经验<三>值得你深入了解的交互设计5大支柱
- android操作sdcard中的多媒体文件(二)——音乐列表的更新
- php laravel mysql无法连接处理方案(linux服务器配置)
- 关于java的上转型对象
- Win32对话框程序(2)
- 第49节:Java集合框架中底层文档的List与Set
- kubernetes session回话保持
- UWP简单示例(二):快速开始你的3D编程
- Redis、RabbitMQ、Memcached
- [转]在Windows上安装RabbitMQ
- utf8.php
- Iframe 父页面自动获取子页面的高度
- EF CodeFirst 数据库的操作