django 学习之DRF (一)
Django框架基础DRF-01
前后端分离介绍
1.前后端不分离图解
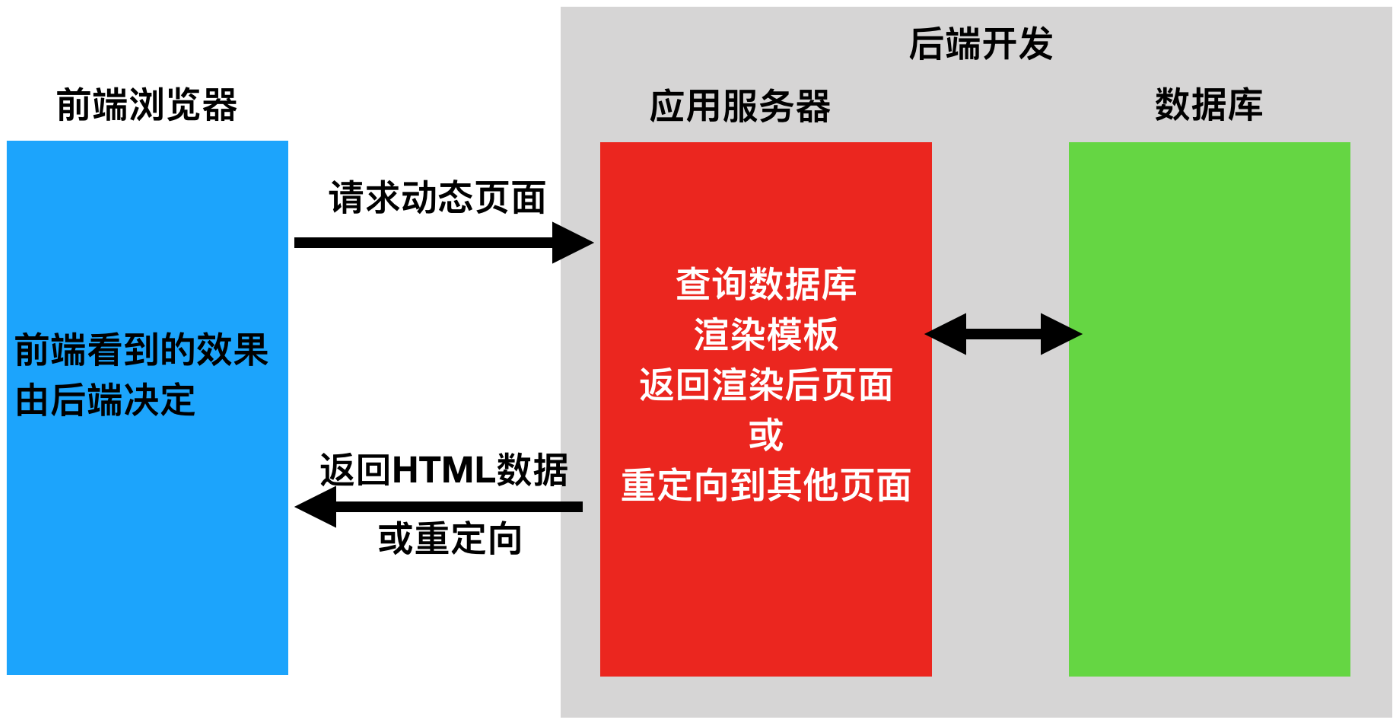
2.前后端分离图解
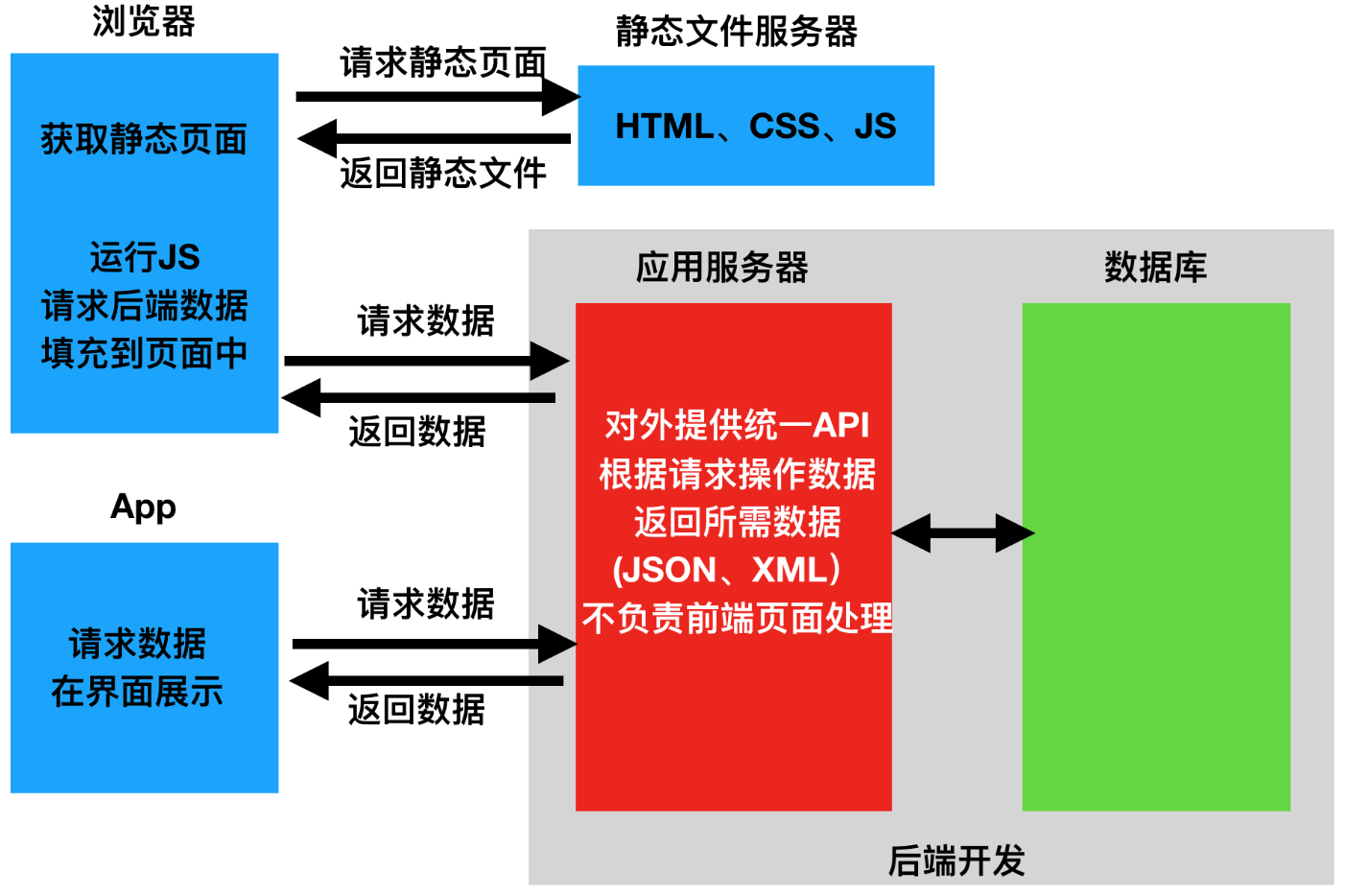
3.为什么要学习DRF DRF可以帮助我们开发者快速的开发⼀个依托于Django的前后后端分离的项目
RESTful 介绍
1.认识 RESTful
1.在前后端分离的应⽤模式⾥,后端API接⼝如何定义?
需要⼀种规范和⻛格来约束后端程序员对接⼝的定义
RESTful 就是⽤来约束后端程序员对接⼝的定义的⼀种⻛格
2.描述
REST,即Representational State Transfer的缩写。维基百科称其为“ 具象状态传输” ,国内⼤部分⼈理解为“ 表现层状态转化” 。
RESTful是⼀种开发理念。维基百科说:REST是设计⻛格⽽不是标准
RESTful架构就是:
• 每⼀个URL代表⼀种资源;
• 客户端和服务器之间,传递这种资源的某种表现层;
• 客户端通过四个HTTP动词,对服务器端资源进⾏操作,实现" 表现层状态转化" 。
2.RESTful 设计⽅法
域名
版本
路径
HTTP动词
过滤信息
状态码
错误处理
返回结果
超媒体
数据传输格式
3.Django和 DRF对⽐
1.Django可以实现前后端分离
Django开发前后端分离的周期⻓
Django如果要遵守RESTful设计⻛格需要⾃⼰写对应⻛格的路由
2.DRF专⻔实现前后端分离
DRF开发前后端分离的周期短
默认遵守的是RESTful设计⻛格
使⽤Django定义REST API
0.⽬的 为了学习在没有DRF的情况下,如何使⽤Django原⽣的形式实现前后端分离且遵守RETSful设计⻛格的项⽬
1.REST API 路由说明
"""
GET /books/ 提供所有记录
POST /books/ 新增⼀条记录
GET /books/<pk>/ 提供指定id的记录
PUT /books/<pk>/ 修改指定id的记录
DELETE /books/<pk>/ 删除指定id的记录
响应数据 JSON
"""
2.提供所有记录
def get(self, request):
"""提供所有记录
GET /books/
"""
# 查询所有记录 books = [BookInfo,BookInfo,BookInfo,BookInfo,BookInfo]
books = BookInfo.objects.all()
# 将模型列表转成字典列表
book_list = []
for book in books:
book_list.append({
'id': book.id,
' btitle' : book.btitle,
' bpub_date' : book.bpub_date,
'bread': book.bread,
' bcomment' : book.bcomment,
'image': book.image.url if book.image else ''
})
# 响应JSON数据
return JsonResponse(book_list, safe= False)
3.新增⼀条记录
def post(self, request):
"""新增⼀条记录
POST /books/
"""
# 读取客户端传⼊的JSON数据
json_bytes = request.body
json_str = json_bytes.decode()
book_dict = json.loads( json_str)
# 创建新的记录
book = BookInfo.objects.create(
btitle=book_dict.get(' btitle' ),
bpub_date=datetime.strptime(book_dict.get(' bpub_date' ), '%Y-%m-%d').date(),
bread = book_dict['bread'],
bcomment = book_dict[' bcomment' ]
)
# 构造响应数据
response_book_dict = {
'id': book.id,
' btitle' : book.btitle,
' bpub_date' : book.bpub_date,
'bread': book.bread,
' bcomment' : book.bcomment,
'image': book.image.url if book.image else ''
}
# 响应结果
return JsonResponse(response_book_dict, status= 201)
4.提供指定id的记录
def get(self, request, pk):
"""提供指定id的记录
GET /books/<pk>/
"""
# 判断pk是否合法
try:
book = BookInfo.objects.get(id=pk)
except BookInfo.DoesNotExist:
return HttpResponse(status= 404)
# 构造响应数据
response_book_dict = {
'id': book.id,
' btitle' : book.btitle,
' bpub_date' : book.bpub_date,
'bread': book.bread,
' bcomment' : book.bcomment,
'image': book.image.url if book.image else ''
}
# 响应结果
return JsonResponse(response_book_dict)
5.修改指定id的记录
def put(self, request, pk):
"""修改指定id的记录
PUT /books/<pk>
"""
# 判断pk是否合法
try:
book = BookInfo.objects.get(id=pk)
except BookInfo.DoesNotExist:
return HttpResponse(status= 404)
# 读取客户端传⼊的JSON数据
json_bytes = request.body
json_str = json_bytes.decode()
book_dict = json.loads( json_str)
# 修改记录
book.btitle = book_dict.get(' btitle' )
book.save()
# 构造响应数据
response_book_dict = {
'id': book.id,
' btitle' : book.btitle,
' bpub_date' : book.bpub_date,
'bread': book.bread,
' bcomment' : book.bcomment,
'image': book.image.url if book.image else ''
}
# 响应结果
return JsonResponse(response_book_dict)
6.删除指定id的记录
def delete(self, request, pk):
"""删除指定id的记录
DELETE /books/<pk>/
"""
# 判断pk是否合法
try:
book = BookInfo.objects.get(id=pk)
except BookInfo.DoesNotExist:
return HttpResponse(status= 404)
# 删除
book.delete()
# 响应
return HttpResponse(status= 204)
序列化和反序列化介绍
0.提示
在开发REST API接⼝时,视图中做的最主要有三件事:
• 将请求的数据(如JSON格式)转换为模型类对象(反序列化)
• 操作数据库
• 将模型类对象转换为响应的数据(如JSON格式)(序列化)
1.序列化
1.概念 将程序中的⼀个数据结构类型转换为其他格式(字典、JSON、 XML等),例如将Django中的模型类对象装换为JSON字符串,这个转换过程我们称为序列化。
2.序列化⾏为
# 判断pk是否合法
try:
book = BookInfo.objects.get(id=pk)
except BookInfo.DoesNotExist:
return HttpResponse(status= 404)
# 构造响应数据
response_book_dict = {
'id': book.id,
' btitle' : book.btitle,
' bpub_date' : book.bpub_date,
'bread': book.bread,
' bcomment' : book.bcomment,
'image': book.image.url if book.image else ''
}
# 响应结果
return JsonResponse(response_book_dict)
3.序列化时机 当需要给前端响应模型数据时,需要将模型数据 序列化 成前端需要的格式
2.反序列化
1.概念 将其他格式(字典、JSON、 XML等)转换为程序中的数据,例如将JSON字符串转换为Django中的模型类对象,这个过程我们称为反序列化。
2.反序列化⾏为
# 读取客户端传⼊的JSON数据
json_bytes = request.body
json_str = json_bytes.decode()
book_dict = json.loads( json_str)
# 创建新的记录
book = BookInfo.objects.create(
btitle=book_dict.get(' btitle' ),
bpub_date=datetime.strptime(book_dict.get(' bpub_date' ), '%Y-%m-%d').date(),
bread = book_dict['bread'],
bcomment = book_dict[' bcomment' ]
)
3.反序列化时机 当需要将⽤户发送的数据存储到数据库之前,需要使⽤反序列化
3.总结
在开发REST API接⼝时,我们在视图中需要做的最核⼼的事是:
• 将数据库数据序列化为前端所需要的格式,并返回;
• 将前端发送的数据反序列化为模型类对象,并保存到数据库中。
1.DRF介绍
1.序列化和反序列化提示
1.在序列化与反序列化时,虽然操作的数据不尽相同,但是执⾏的过程却是相似的,也就是说这部分代码是可以复⽤简化编写的。
2.在开发REST API的视图中,虽然每个视图具体操作的数据不同,但增、删、改、查的实现流程基本套路化,所以这部分代码也是可以复⽤简化编写的:
• 增 :校验请求数据 -> 执⾏反序列化过程 -> 保存数据库 -> 将保存的对象序列化并返回
• 删 :判断要删除的数据是否存在 -> 执⾏数据库删除
• 改 :判断要修改的数据是否存在 -> 校验请求的数据 -> 执⾏反序列化过程 -> 保存数据库 -> 将保存的对象序列化并返回
• 查 :查询数据库 -> 将数据序列化并返回
3.DRF将序列化和反序列化的业务逻辑进⾏了封装 程序员只需要将序列化和反序列化的数据传给DRF即可
2.DRF作⽤ Django REST framework可以帮助我们简化序列化和反序列化部分的代码编写,⼤⼤提⾼REST API的开发速度。
3.DRF特点
• 提供了定义序列化器Serializer的⽅法,可以快速根据 Django ORM 或者其它库⾃动序列化/ 反序列化;
• 提供了丰富的类视图、Mixin扩展类,简化视图的编写;
• 丰富的定制层级:函数视图、类视图、视图集合到⾃动⽣成 API,满⾜各种需要;
• 多种身份认证和权限认证⽅式的⽀持;
• 内置了限流系统;
• 直观的 API web 界⾯;
• 可扩展性,插件丰富
4.相关⽂档
官⽅⽂档 http://www.django-rest-framework.org/
源码 https://github.com/encode/django-rest-framework/tree/master
2.DRF安装和配置
1.DRF环境依赖
• Python (2.7, 3.2, 3.3, 3.4, 3.5, 3.6)
• Django (1.10, 1.11, 2.0)
DRF是以Django扩展应⽤的⽅式提供的,所以我们可以直接利⽤已有的Django环境⽽⽆需从新创建。(若没有Django环境,需要先创建环境安装Django)
2.安装DRF pip install djangorestframework
3.添加rest_framework应⽤
INSTALLED_APPS = [
' django.contrib.admin' ,
' django.contrib.auth' ,
' django.contrib.contenttypes' ,
' django.contrib.sessions' ,
' django.contrib.messages' ,
' django.contrib.staticfiles' ,
'rest_framework', # DRF
'users.apps.UsersConfig', # 安装users应⽤, 演示基本使⽤
'request_response.apps.RequestResponseConfig', # 演示请求和响应
' booktest.apps.BooktestConfig' , # 图书英雄管理应⽤
]
3.DRF初体验
1.创建序列化器 booktest.serializers
from rest_framework import serializers
from .models import BookInfo
class BookInfoSerializer(serializers.ModelSerializer):
"""BookInfo模型类的序列化器"""
class Meta:
model = BookInfo
fields = '__all__'
2.编写视图逻辑
from rest_framework.viewsets import ModelViewSet
from .models import BookInfo
from . import serializers
class BookInfoViewSet(ModelViewSet):
"""使⽤DRF实现增删改查的后端API"""
# 指定查询集
queryset = BookInfo.objects.all()
# 指定序列化器
serializer_class = serializers.BookInfoSerializer
3.定义路由
from django.conf.urls import url from rest_framework.routers import DefaultRouter from . import views urlpatterns = [ # url(r'^books/$', views.BooksAPIView.as_view()), # url(r'^books/(?P<pk>\d+)/$', views.BookAPIView.as_view()), ] # 创建路由对象 router = DefaultRouter() # 将视图集注册到路由 router.register(r'books', views.BookInfoViewSet) # 视图集路由添加到urlpatterns urlpatterns += router.urls
4.运⾏测试 GET http://127.0.0.1:8000/books/
Serializer序列化器
1.序列化器的作⽤
1. 进⾏数据的校验
2. 对数据对象进⾏转换
2.定义序列化器说明
1.模型类
# 定义图书模型类BookInfo
class BookInfo(models.Model):
btitle = models.CharField(max_length= 20, verbose_name= ' 名称' )
bpub_date = models.DateField(verbose_name= ' 发布⽇期' )
bread = models.IntegerField(default= 0 , verbose_name= ' 阅读量' )
bcomment = models.IntegerField(default= 0 , verbose_name= ' 评论量' )
is_delete = models.BooleanField(default= False, verbose_name= ' 逻辑删除' )
image = models.ImageField(upload_to= 'book', verbose_name= ' 图书图⽚' , null= True)
2.序列化器
class BookInfoSerializer(serializers.Serializer):
"""图书数据序列化器"""
id = serializers.IntegerField(label= 'ID', read_only= True)
btitle = serializers.CharField(label= ' 名称' , max_length= 20, validators=[about_django])
bpub_date = serializers.DateField(label= ' 发布⽇期' , required= False)
bread = serializers.IntegerField(label= ' 阅读量' , required= False)
bcomment = serializers.IntegerField(label= ' 评论量' , required= False)
image = serializers.ImageField(label= ' 图⽚' , required= False)
heroinfo_set = serializers.PrimaryKeyRelatedField(read_only= True, many= True)
3.定义序列化器字段类型和选项
1.字段类型 类似于模型字段类型
2.选项参数
3.通⽤选项、参数
4.创建Serializer序列化器对象
1.构造⽅法
Serializer的构造⽅法为:
Serializer(instance=None, data=empty, **kwarg)
2.构造⽅法说明
1.⽤于序列化时
将模型类对象传⼊instance参数
Serializer(book)
序列化 == 模型数据—>python字典 (⽤于输出,返回数据给前端)
2.⽤于反序列化时
将要被反序列化的数据传⼊data参数
Serializer(data=data)
反序列化 == 前端发送的数据—>经过验证—>python字典—>save—>模型类对象(⽤于输⼊,接受前端数据)
Serializer序列化器之序列化操作
1.序列化⼀个模型对象
>>> from booktest.models import BookInfo
>>> book = BookInfo.objects.get(id=1)
>>> book
<BookInfo: 射雕英雄传>
>>> from booktest.serializers import BookInfoSerializer
>>> s = BookInfoSerializer(book)
>>> s.data
{'id': 1, 'btitle': '射雕英雄传', 'bpub_date': '1980-05-01', 'bread': 12, 'bcomment': 34, 'image': None}
2.序列化多个模型对象
>>> qs = BookInfo.objects.all()
>>> qs
<QuerySet [<BookInfo: 射雕英雄传>, <BookInfo: 天⻰⼋部>, <BookInfo: 笑傲江湖>, <BookInfo: 雪⼭⻜狐>, <BookInfo: ⻄游记>]>
>>> s = BookInfoSerializer(qs, many=True)
>>> s.data
3.关联对象嵌套序列化
1.增加HeroInfo对应的序列化器
class HeroInfoSerializer(serializers.Serializer):
"""英雄数据序列化器"""
GENDER_CHOICES = (
(0 , 'male'),
(1 , 'female')
)
id = serializers.IntegerField(label= 'ID', read_only= True) # 只会做序列化(输出)
hname = serializers.CharField(label= ' 名字' , max_length= 20)
hgender = serializers.ChoiceField(choices=GENDER_CHOICES, label= ' 性别' , required= False)
hcomment = serializers.CharField(label= ' 描述信息' , max_length= 200, required= False, allow_null= True)
# 在序列化器中定义外键关联字段
# 必须:read_only=True(让前端⽆法对外键进⾏输⼊操作,只能输出)
hbook = serializers.PrimaryKeyRelatedField(label= ' 图书' , read_only= True)
2.序列化过程
>>> from booktest.serializers import BookInfoSerializer, HeroInfoSerializer
>>> from booktest.models import BookInfo, HeroInfo
>>> hero = HeroInfo.objects.get(id=1)
>>> hero
<HeroInfo: 郭靖>
>>> s = HeroInfoSerializer(hero)
>>> s.data
{'id': 1, 'hname': '郭靖', 'hgender': 1, 'hcomment': '降⻰⼗⼋掌', 'hbook': 1}
4.many参数
1.增加⼀查多的关系字段
class BookInfoSerializer(serializers.Serializer):
"""图书数据序列化器"""
id = serializers.IntegerField(label= 'ID', read_only= True) # 只会做序列化(输出)
btitle = serializers.CharField(label= ' 名称' , max_length= 20)
bpub_date = serializers.DateField(label= ' 发布⽇期' , required= False)
bread = serializers.IntegerField(label= ' 阅读量' , required= False)
bcomment = serializers.IntegerField(label= ' 评论量' , required= False)
image = serializers.ImageField(label= ' 图⽚' , required= False)
# 定义⼀关联多的序列化器字段
# many=True : 表示⼀对多
heroinfo_set = serializers.PrimaryKeyRelatedField(read_only= True, many= True) # 新增
2.序列化过程
>>> from booktest.models import BookInfo, HeroInfo
>>> from booktest.serializers import BookInfoSerializer
>>> book = BookInfo.objects.get(id=1)
>>> book
<BookInfo: 射雕英雄传>
>>> s = BookInfoSerializer(book)
>>> s.data
{'id': 1, 'btitle': '射雕英雄传', 'bpub_date': '1980-05-01', 'bread': 12, 'bcomment': 34, 'image': None, 'heroinfo_set': [1, 2, 3, 4, 5]}
相关源码连接:
最新文章
- nodejs复习01
- jquery了解
- redis事务
- Linux基础※※※※如何使用Git in Linux(二)
- 解决Tomcat 6.0 只支持 J2EE 1.2, 1.3, 1.4, and Java EE 5 Web modules
- 51nod 1043 幸运号码(数位dp)
- linux下怎么编译运行C语言程序?
- C++学习笔记:List容器
- ios开发——实用技术OC-Swift篇&触摸与手势识别
- QT中的OpcDa 客户端 实现
- 转:jmeter之线程组
- [深入学习Redis]RedisAPI的原子性分析
- python中的pymongo连接脚本
- firewalld的使用(CentOS7的端口打开关闭)
- MVC4.0中cshtml中怎么解析html编码
- Python的函数名作为参数传入调用以及map、reduce、filter
- LoadRunner设置监控Windows系统资源步骤
- cannot be cast to
- 飞舞的蝴蝶(GraphicsView框架)
- Selenium+Python学习之一