6.2 DataFrame
一、DataFrame概述

在Spark SQL中,DataFrame就是它的数据抽象,对DataFrame进行转换操作。
DataFrame的推出,让Spark具备了处理大规模结构化数据的能力,不仅比原有的RDD转化方式更加简单易用,而且获得了更高的计算性能Spark能够轻松实现从MySQL到DataFrame的转化,并且支持SQL查询。

- RDD是分布式的Java对象的集合,但是,对象内部结构对于RDD而言却是不可知的;
- DataFrame是一种以RDD为基础的分布式数据集,提供了详细的结构信息
RDD就像一个空旷的屋子,你要找东西要把这个屋子翻遍才能找到。DataFrame相当于在你的屋子里面打上了货架。那你只要告诉他你是在第几个货架的第几个位置,那不就是二维表吗。那就是我们DataFrame就是在RDD基础上加入了列。实际上我们处理数据就像处理二维表一样。
二、DataFrame的创建
从Spark2.0以上版本开始,Spark使用全新的SparkSession接口替代Spark1.6中的SQLContext及HiveContext接口来实现其对数据加载、转换、处理等功能。SparkSession实现了SQLContext及HiveContext所有功能

SparkSession支持从不同的数据源加载数据,并把数据转换成DataFrame,并且支持把DataFrame转换成SQLContext自身中的表,然后使用SQL语句来操作数据。SparkSession亦提供了HiveQL以及其他依赖于Hive的功能的支持。
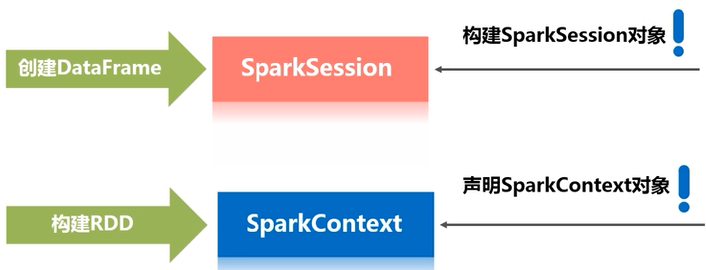
(1)如果是通过交互式shell,执行下面的语句,spark-shell自动创建一个SparkSession对象spark,SparkContext对象sc;

(2)如果是编程中,需要手动创建。(?)
在创建DataFrame之前,为了支持RDD转换为DataFrame及后续的SQL操作,需要通过import语句(即import spark.implicits._)导入相应的包,启用隐式转换。
隐式转换介绍:
- 包括隐式参数、隐式对象、隐式类
- scala独有的
- 当调用对象中不存在的方法,系统会扫描上下文和伴对象看是否有implicit方法,如果有隐式方法则调用隐式方法,隐式方法传入原生对象返回包含扩展方法的对象。
- 原类型和伴生对象都找不到的隐式值,会找手动导入的implicit Import Spark.implicit._
在创建DataFrame时,可以使用spark.read操作,从不同类型的文件中加载数据创建DataFrame,例如:
spark.read.json("people.json"):读取people.json文件创建DataFrame;在读取本地文件或HDFS文件时,要注意给出正确的文件路径;
spark.read.parquet("people.parquet"):读取people.parquet文件创建DataFrame;
spark.read.csv("people.csv"):读取people.csv文件创建DataFrame。
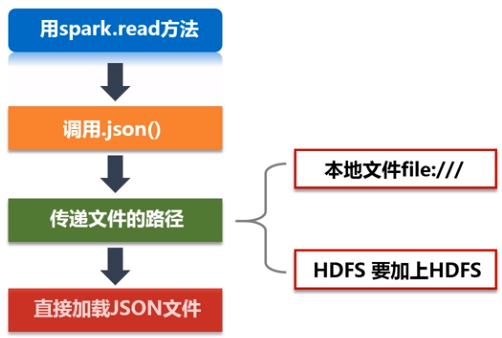

举例:




三、DataFrame的保存
可以使用spark.write操作,把一个DataFrame保存成不同格式的文件,例如,把一个名称为df的DataFrame保存到不同格式文件中,方法如下:
df.write.json("people.json“)
df.write.parquet("people.parquet“)
df.write.csv("people.csv")
例子:从示例文件people.json中创建一个DataFrame,然后保存成csv格式文件,代码如下:

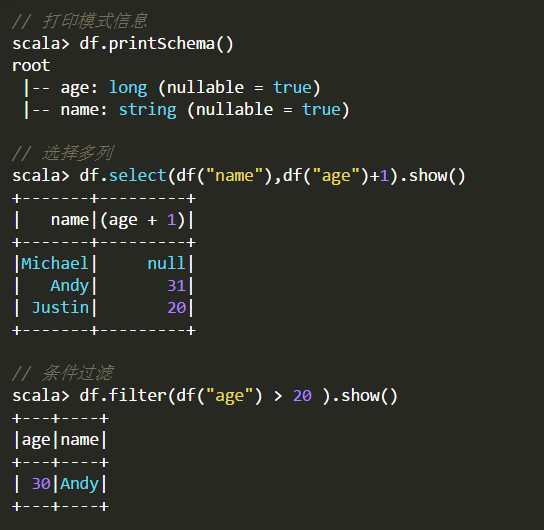
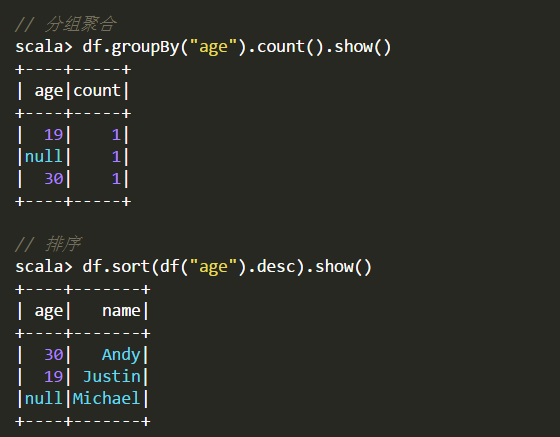
四、DataFrame的常用操作

五、从RDD转换得到DataFrame
Spark SQL支持两种方式将现有RDD转换为DataFrame。
- 第一种方法使用反射来推断RDD的schema并创建DataSet然后将其转化为DataFrame。这种基于反射方法十分简便,但是前提是在您编写Spark应用程序时就已经知道RDD的schema类型。
- 第二种方法是通过编程接口,使用您构建的StructType,然后将其应用于现有RDD。虽然此方法很麻烦,但它允许您在运行之前并不知道列及其类型的情况下构建DataSet
1.利用反射机制推断RDD模式
适用对已知数据结构的RDD转换
举例:在“/usr/local/spark/examples/src/main/resources/”目录下,有个Spark安装时自带的样例数据people.txt,其内容如下,现在要把people.txt加载到内存中生成一个DataFrame,并查询其中的数据:


在利用反射机制推断RDD模式时,需要首先定义一个case class,因为只有case class才能被Spark隐式地转换为DataFrame。


必须要把dataframe注册为临时表才能供下面的查询使用

打印dataframe


2.使用编程方式定义RDD模式
适用于事先不知道字段,通过动态的方式得到信息。
比如,现在需要通过编程方式把people.txt加载进来生成DataFrame,并完成SQL查询。







参考文献:
最新文章
- window.showModalDialog返回值和window.open返回值实例详解
- 绘制图形与3D增强技巧(二)----直线图元
- gedit配置记
- window 安装 sass compass 记录
- [转载] 文件系统vs对象存储——选型和趋势
- 用java运行Hadoop程序报错:org.apache.hadoop.fs.LocalFileSystem cannot be cast to org.apache.
- 利用TEA算法进行数据加密
- Python使用Pygame.mixer播放音乐
- sitecore(key\value\language)的灵活应用
- js抽象类和抽象方法
- MAC OS中使用ll,la命令
- CodeForces 22C System Administrator
- ArcGis for flex查询FeatureLayer数据
- iOS 钥匙串存储用户数据
- Java访问权限修饰符public protected friendly private用法总结(转载好文Mark)
- jmeter获取cookies信息(配置)
- ANSYS附加动水质量(westergarrd公式)
- 搭建RDA交叉编译器
- android:AlertDialog控件
- jquery动态加载js/css文件方法