Image Caption论文合辑2
说明: 这个合辑里面的论文不全是Image Caption, 但大多和Image Caption相关, 同时还有一些Workshop论文。
Guiding Long-Short Term Memory for Image Caption Generation (ICCV 2015)
Highlight: Beam Search with Length Normalization
From Captions to Visual Concepts and Back (CVPR 2015)
Highlight: First use CNN to detect the concepts in the image, and then use these detected concepts to guide the language model to generate a sentence.
Show and Tell: Lessons learned from the 2015 MSCOCO Image Captioning Challenge (TPAMI 2016)
Improvements Over Our CVPR15 model:
1.Image Model Improvement (Batch Normalization)
2.Image Model Fine Tuning: Fine tuning the image model must be carried after the LSTM parameters have settled on a good language model: when jointly training both, the noise in the initial gradients coming from the LSTM into the image model corrupted the CNN and would never recover.
3.Scheduled Sampling: There is a discrepancy between training and inference. Curriculum learning strategry to gently change the training process from a fully guided scheme using the true previous word, towards a less guided scheme which mostly uses the model generated word instead.
4.Ensembling
5.Beam Size Reduction: (the best beam size is 3) reduced beam size technique as another way to regularize.
Rich Image Captioning in the Wild (CVPR 2016 workshop)
Highlight: identifies celebrities and landmarks
Main work: Built on top of a state-of art framework, we developed a deep vision model that detects a broad range of visual concepts, an entity recognition model that identifies celebrities and landmarks ,and a confidence model for the caption output.
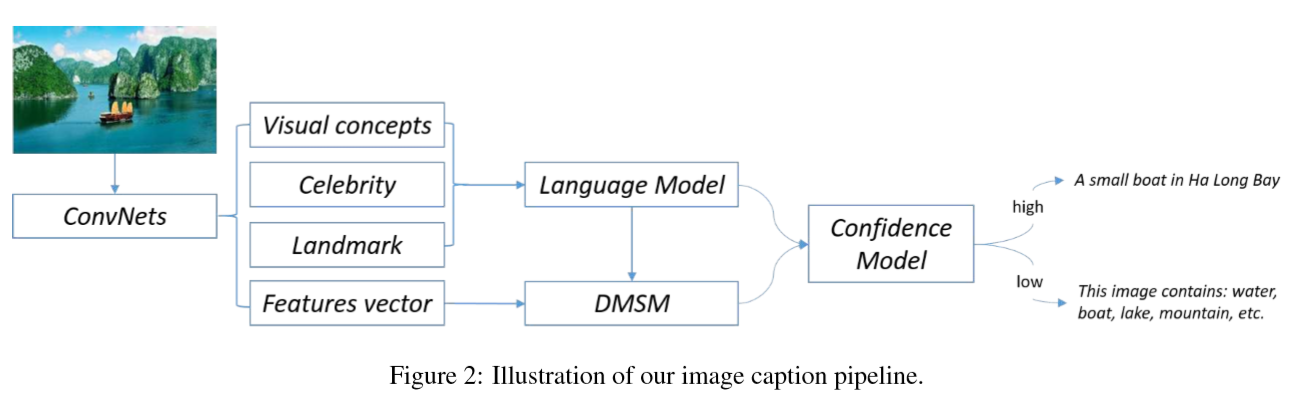
MELM+DMSM
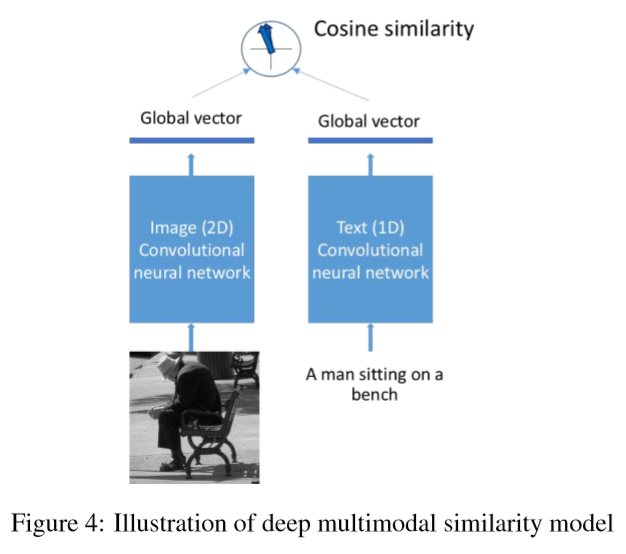
maximum entropy language model
deep multimodal similarity model
What the Role of Recurrent Neural Networks (RNNs) in an Image Caption Generator? (ACL 2017)
Highlight: This paper compares two architectures: the inject architecture and the merge architecture. Suggesting that RNNs are better viewed as encoders, rather than generators.(recurrent networks are best viewed as learning representations, not as generating sequences)

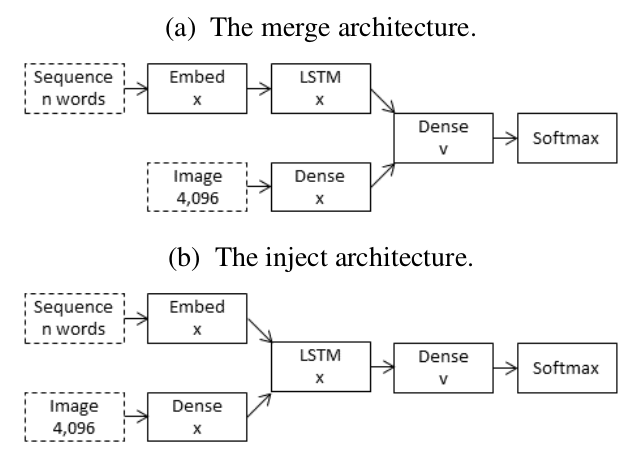
In short, given a neural network architecture that is expected to process input sequences from multiple modalities, arriving at a joint representation, it would be better to have a separate component to encode each input, bringing them together at a late stage, rather than to pass them all into the same RNN through separate input channels.
There are also more practical advantages to merge architectures, such as for transfer learning. Since merge keeps the image seperate from the RNN, the RNN used for captioning can conceivably be transferred from a neural language model that has been trained on general text.
Actor-Critic Sequence Training for Image Captioning (NIPS 2017 workshop)
Semantic Regularisation for Recurrent Image Annotation (CVPR 2017)
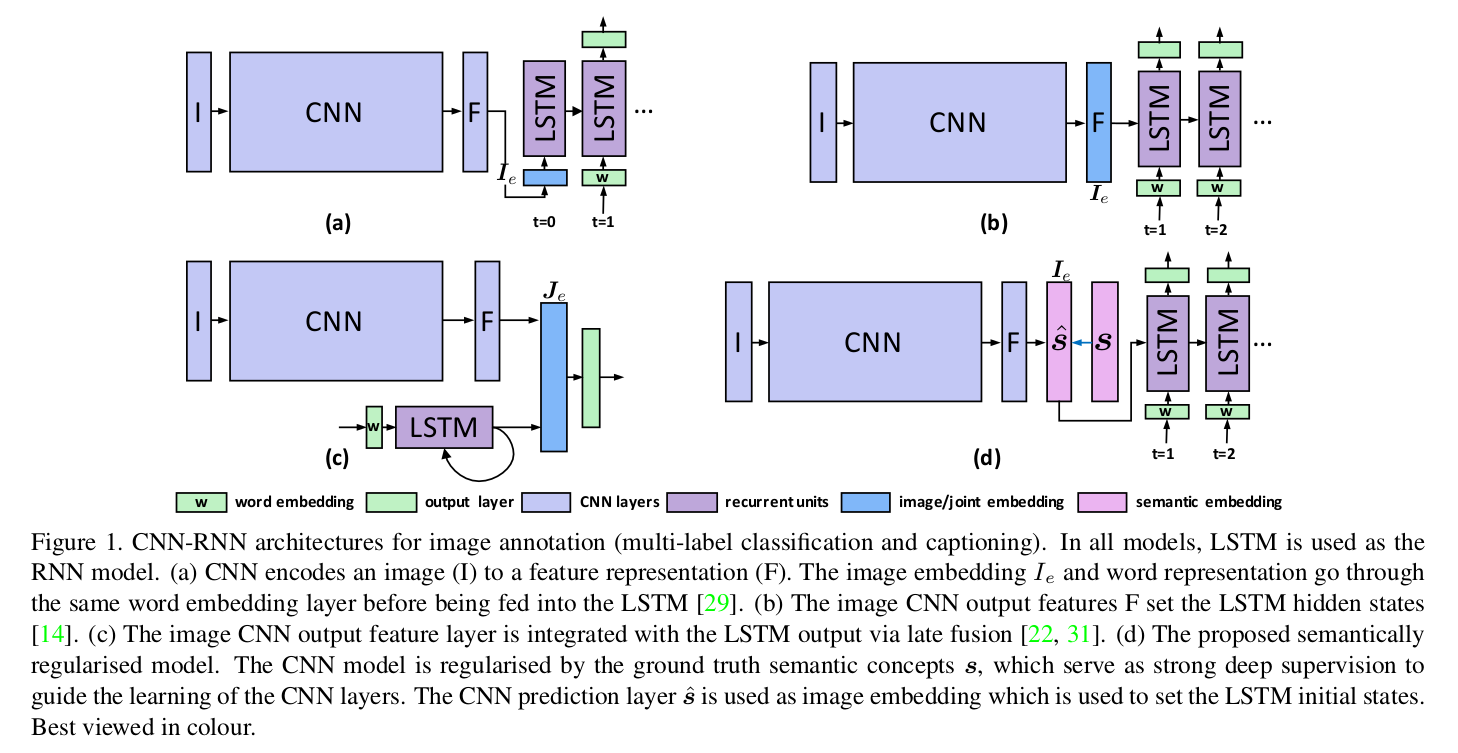
[29]——Show and Tell
[14]——Annotation order matters: Recurrent image annotator for arbitrary length image tagging
[22]——Deep captioning with multimodal recurrent neural networks (m-rnn)
[31]——CNN-RNN: A unified framework for multi-label image classification

Rethinking the Form of Latent States in Image Captioning (ECCV 2018) Bo Dai
Highlight: latent states vector--->2D explores two dimensional states in the context of image captioning. Taking advantages of spatial locality.
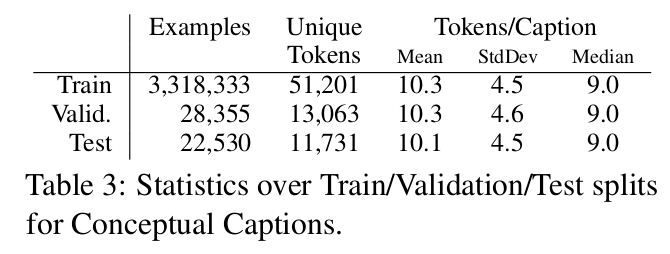
Conceptual Captions: A Cleaned, Hypernymed, Image Alt-text Dataset For Automatic Image Captioning (ACL 2018)
Highlight: This paper is from Google AI and it presents a new dataset of image caption annotations.
Github: https://github.com/google-research-datasets/conceptualcaptions


这两篇是同一作者, Constrained Beam Search
Guided Open Vocabulary Image Captioning with Constrained Beam Search (NMNLP2017)
Highlight: Contrained Beam Search
implemented in AllenNLP.

Partially-Supervised Image Captioning (NIPS 2018)
Attribute
Boosting Image Captioning with Attributes (ICCV 2017)

Show, Observe and Tell: Attribute-driven Attention Model for Image Captioning (IJCAI 2018)
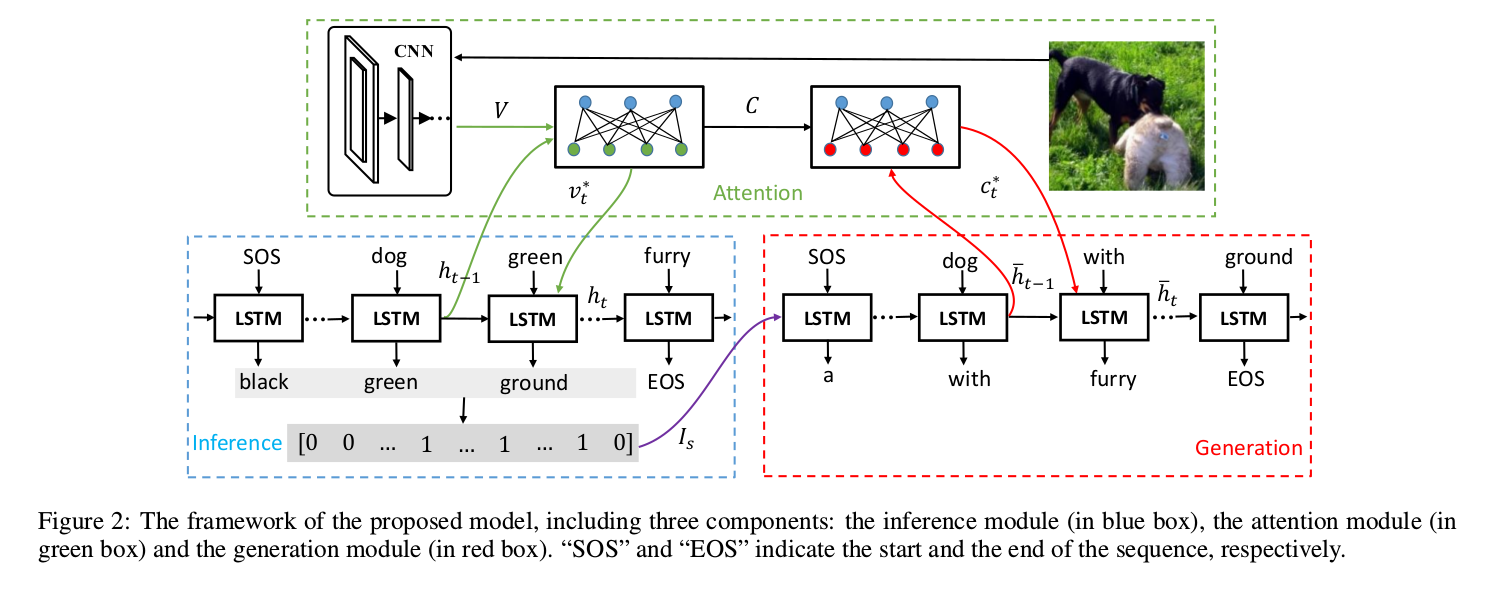
The inference module aims to predict the attributes and produce their observed context features in a sequential manner.
The generation module attempts to generate the sentence word by word, on the basis of the image information.
The attention module interacts with the inference module and the generation module and provides different types of features for them.
Diversity
Context-aware Captions from Context-agnostic Supervision (CVPR 2017)
Contrastive Learning for Image Captioning (NIPS 2017)
Highlight: distinctiveness (diversity)
Compared to human descriptions, machine-generated captions are often quite rigid and tend to favor a "safe"(i.e. matching parts of the training captions in a word-by-word manner) but restrictive way. As a consequence, captions generated for different images, especially those that contain objects if the same categories, are sometimes very similar despite their differences in other aspects.
We propose Contrastive Learning (CL), a new learning method for image captioning, which explicitly encourages distinctiveness, while maintaining the overall quality of the generated captions.
During learning, in addition to true image-caption pairs, denoted as (I,c), this method also takes as input mismatched pairs, denoted as (I,c/) where c/ is a caption describing another image. Then, the target model is learned to meet two goals namely (1) giving higher probabilities p(c|I) to positive pairs, and (2) lower probabilities p(c/|I) to negative pairs, compared to the reference model. The former ensures that the overall performance of the target model is not inferior to the reference; while the latter encourages distinctiveness.
Discriminability objective for training descriptive captions (CVPR 2018)
Personalized
Attend to You: Personalized Image Captioning with Context Sequence Memory Networks (CVPR 2017)
Towards Personalized Image Captioning via Multimodal Memory Networks (TPAMI 2018)
Novel Object-based
Captioning Images with Diverse Objects (CVPR 2017)
Neural Baby Talk (CVPR 2018)
涉及到Novel Object-based Image Captioning和Templated Image Captioning
Our approach reconciles classical slot filling approaches(that are generally better grounded in images) with modern neural captioning approaches (that are generally more natural sounding and accurate).
Our approach first generates a sentence 'template' with slot locations explictly tied to specific image regions. These slots are then filled in by visual concepts identified in the regions by object detectors.
The entire architecture (sentence template generation and slot filling with object detectors ) is end to end differentiable.
One nice feature of our model is that it allows for different object detectors to be plugged in easily.
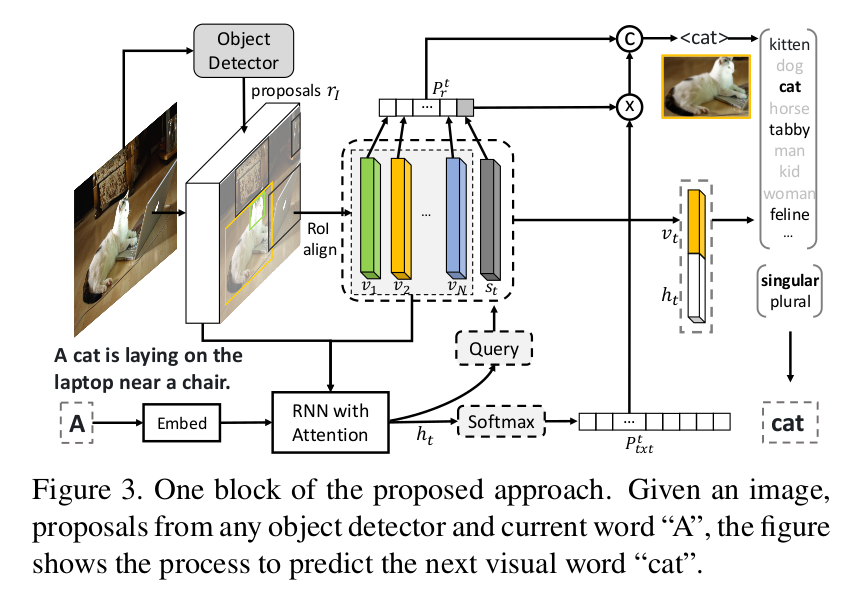
Improving Reinforcement Learning Based Image Captioning with Natural Language Prior (EMNLP 2018)
最新文章
- django中css问题
- Java创建WebService服务及客户端实现(转)
- linux系统的7种运行级别
- BeanShell用法汇总(部分摘抄至网络)【转】
- Abstract Factory(抽象工厂)模式
- cvLoadImage函数解析 cvLoadImageM()函数
- .net通过获取客户端IP地址反查出用户的计算机名
- sonarQube 管理
- Mac设置
- 第六节,初识python和字符编码
- HDU2199,HDU2899,HDU1969,HDU2141--(简单二分)
- PHP文件上传处理
- POJ-1068 Parencodings---模拟括号的配对
- JS案例五:设置全选、全不选以及反选
- [转]Angular开发(十八)-路由的基本认识
- 安装Linux系统
- Zuul 跨域
- 今天通过npm 安装 install 的时候出现的问题
- 【机器学习】用Octave实现一元线性回归的梯度下降算法
- uni - 自定义组件