python爬虫之路——无头浏览器初识及简单例子
2024-08-23 04:02:43
from selenium import webdriver
url='https://www.jianshu.com/p/a64529b4ccf3'
def get_info(url):
include_title=[]
driver=webdriver.PhantomJS()
driver.get(url)
driver.implicitly_wait(20)
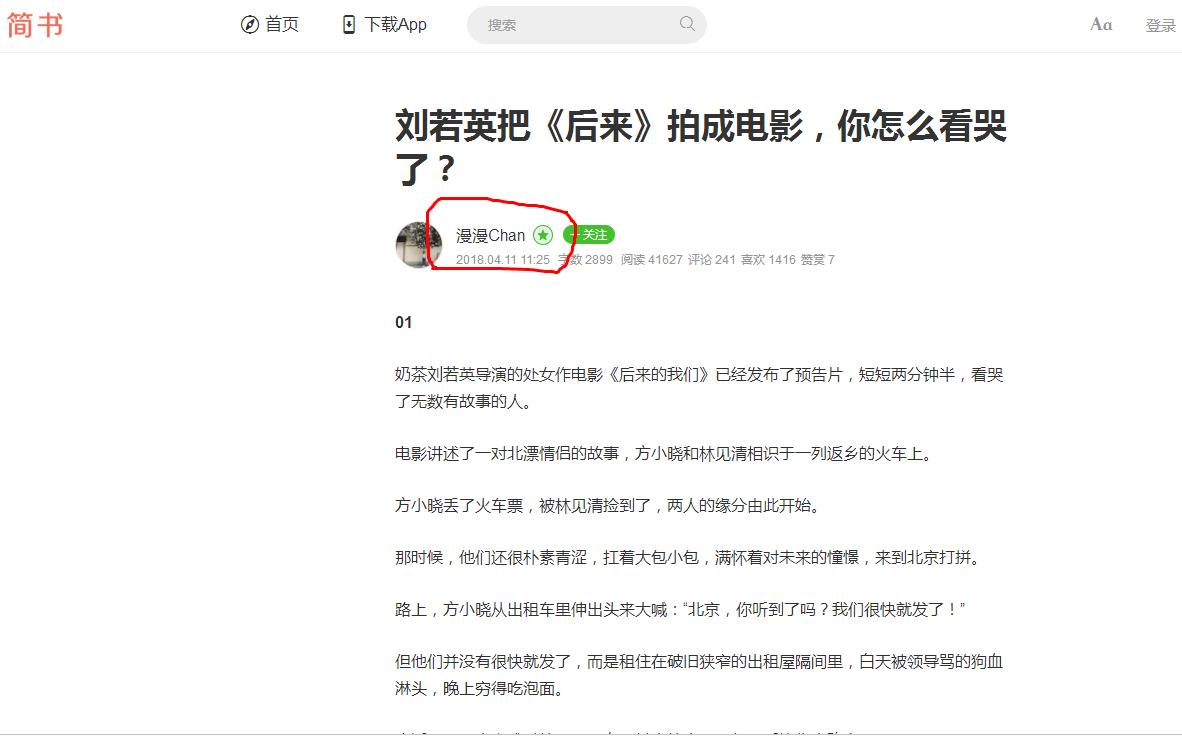
author=driver.find_element_by_xpath('/html/body/div[1]/div[1]/div[1]/div[1]/div/span/a').text
print(author)
get_info(url)

最新文章
- 输入事件驱动---evdev_handler的大致实现流程(修整版)
- 剑指Offer:面试题31——连续子数组的最大和(java实现)
- OpenGL的简单研究-开端
- ajax之jsonp跨域请求
- Struts 2.x No result defined for action 异常
- js高级程序设计(七)函数表达式
- <s:select>下拉框是空白的解决办法
- Jquery核心函数
- MVC4下拉少数名族
- 如何创建和使用XMLHttpRequest对象?
- DB天气app冲刺二阶段第三天
- javascript 冒泡
- 问题-[Delphi]用LoadLibrary加载DLL时返回0的错误
- apache kafka技术分享系列(目录索引)--转载
- MYSQL <=>运算符
- vs 2015常用快捷键
- 使用nginx作为websocket的proxy server
- 第三期分享:一款很好用的api文档生成器
- TensorFlow tensor张量拼接concat - split & stack - unstack
- Robot Framework 入门教程总结