机器学习1—简介及Python机器学习环境搭建
简介
前置声明:本专栏的所有文章皆为本人学习时所做笔记而整理成篇,转载需授权且需注明文章来源,禁止商业用途,仅供学习交流.(欢迎大家提供宝贵的意见,共同进步)
正文:
机器学习,顾名思义,就是研究计算机如何学习和模拟人类的行为,并根据已学得的知识对该行为进行增强和改进。
举例来说,假设邮箱收到了一封新邮件,通常我们可以通过邮件里是否含有广告、不相关信息以及乱码等特征,人为的来判断这封邮件是否是一封垃圾邮件。
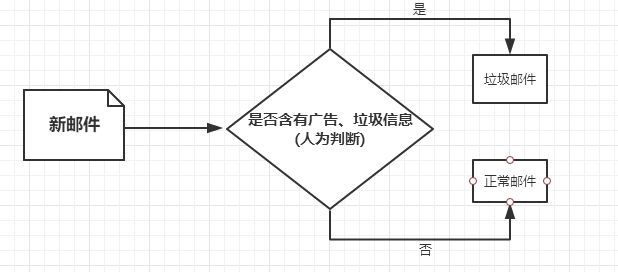
如上述可知,机器学习模拟人类的行为,所以它同样依据这些邮件内容的特征来判断一封邮件是否是垃圾邮件。那么计算机是如何判断邮件内容里那些是广告和垃圾信息的呢? 我们知道,在我们刚出生的时候,大家都不知道世间那些事情是好的,那些事情是坏的,都是爸爸妈妈告诉我们说:打人是不对的,帮助他人才是该做的。同理,尚未学习的计算机刚开始也不能独立思考,为了让它区分垃圾邮件和正常邮件,所以我们必须需要告诉它,邮件里的内容那些是广告和垃圾信息,那些是正常的内容。这一过程是机器学习的核心过程,通过这一核心过程,计算机便有了初步的对于邮件垃圾与否的“知识”,正如我们学了加减乘除后便可以做简单的运算。
机器学习的核心过程一般分为包含如下模块:
- 训练数据集:训练数据集是机器学习的“课本”,如邮件训练数据集,其中包含了各种各样的邮件,其中每个邮件都有一个标识,用来表示其为正常邮件还是垃圾邮件。典型的数据格式如:邮件1,1;邮件2,0,;邮件3,1;其中0表示正常邮件,1表示垃圾邮件,因此可以看出邮件1和3为垃圾邮件,邮件2为正常邮件;
- 学习算法:计算机通过机器学习算法对训练数据集进行分析,并建立最终的模型。即通过对“课本”的学习,建立一套自己的解题方案。如通过对邮件数据集的学习后,当收到新邮件时,通过模型便可判断该邮件是否是垃圾邮件。模型的最终生成以及其性能的高低依据选择的机器算法而定。
- 测试模型:通过某些测试数据[类别未知]对模型进行测试,如输入多封新邮件测试模型能够将邮件正确分类的效果,若达不到预期效果则需要调整学习算法的参数。
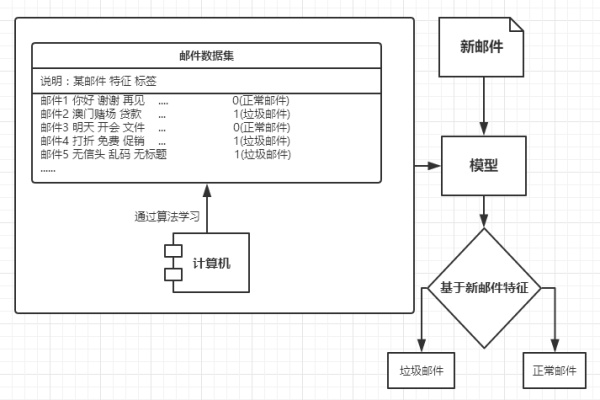
机器学习算法有很多,大致分为监督学习算法和无监督学习算法。
监督学习:训练数据集的类别已知,如上文提到的邮件训练数据集,通过对训练数据集的学习生成模型。好比面前有一位老师告诉了你题目的方法和答案,,当你了解了老师教你的方法时,面对的新的题目便可自行解答。
监督学习的算法:
- 分类算法 —— K-近邻算法、决策树、朴素贝叶斯算法、Logistic回归、etc.
- 预测算法 —— 局部加权线性回归、线性回归、支持向量、Ridge回归、Lasso最小回归系数估计、etc.
无监督学习:数据集的类别未知,如草原上一群未被标记的动物,起初不知道这些动物该如何分类,但通过观察这些动物的特征便可知道,可以将体格壮的分为一类(大型动物),食草的分为一类(食草动物)以及爬行的分为一类(爬行动物)等,因此无监督学习也是通过对数据集的特征进行分析,根据特征相似性对数据集进行分类。
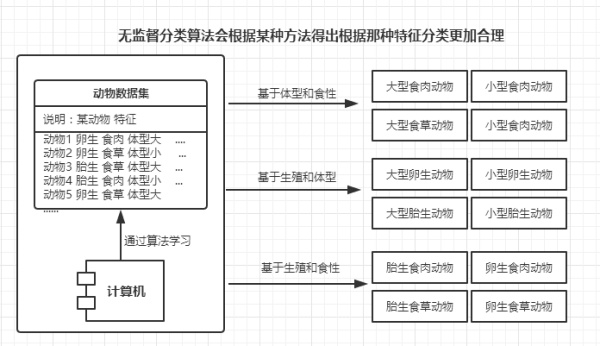
无监督学习算法:K-均值、最大期望算法、DBSCAN、Parzen窗设计、etc.
[上述提到的机器算法会在后续中一 一讲解]
总之,机器学习通过算法对训练数据集进行学习,生成最终的模型,并用此模型模拟人类行为对新输入进行判断。
机器学习模型除了可以分辨垃圾邮件外,还可以做很多事情,比如根据对超市顾客购物清单的学习分析,可知买了尿布的顾客会顺便买一罐啤酒,因此超市可将尿布和啤酒放在一起从而提高销量;通过对图书馆借书记录的分析,可以将相似的书籍推荐给读者;对购买产品记录的分析,网站会提示买家该产品的最佳搭配产品或者提示买家其他顾客除了购买该产品还购买了哪些与之搭配的产品;通过对房子的特征及其房价的数据分析,可以预测某种房子的房价;通过对文本的分析对大量的文章进行自动分类......。机器学习可以做很多自动化的事情,从而提高效率。
在学习机器学习算法的理论及代码实现前,需要如下几个前提:
- 高等数学、线性代数、概率论与数理统计的基础 (至少了解概念)
- 编程基础 (Java、C++、Python 等都可作为实现机器学习算法的语言) [建议:Python,Python包含众多的科学计算包,更容易更方便实现其算法]
Python机器学习环境搭建
若未接触过Python,需要看下Python的基础语法,不过代码里面我会写上详细注释。
正如安装Java一样,我们需要去官方网站下载JDK,Python类似,Python分为2.7和3.6版本,本专栏选择使用2.7版本。
安装好Python后,还需要安装机器学习所需要的Python科学计算包 ,例如:numpy+mkl、scipy、matplotlib等。不过这里我们并不安装原始的Python版本,而是安装anaconda,它是Python的一个发行版本,安装好它后就不用再去下载上述Python包,其本身已经包含了,比较方便。

anaconda下载地址:Downloads 选择Python 2.7 version下载
安装步骤在此略过。
安装好后打开Anaconda Navigator 如图:

启动后如图所示:
lauch spyder,spyder是Anaconda下的一个Python集成开发环境,正如Java之于Eclipse,.net之于Visual Studio .其他工具后续再说。


当然按照惯例 输出 hello world
机器学习的简介和Python开发环境的搭建到此结束,后续将会依次讲解机器学习的算法、数学知识以及算法的推导过程。
2017/10/30 阿弎
最新文章
- 分布式系统理论进阶 - Paxos
- 程序设计入门——C语言 第7周编程练习 1多项式加法(5分)
- java提高篇之理解java的三大特性——多态
- Xcode8以及iOS10问题总结!
- grep 和 wc命令 --- !管道命令!
- 在LiteIDE 中增加build 的参数
- C#中属性简写原理
- .NET 利用反射将对象数据添加到数据库
- GCD教程(一):基本概念
- AngularJS高级程序设计读书笔记 -- 指令篇 之 内置指令
- php开发微信公众号获取信息LBS
- PHP算法练习1:两数之和
- 用交叉验证改善模型的预测表现-着重k重交叉验证
- [c/c++] programming之路(16)、指针
- Ubuntu 下搭建 Android 开发环境(图文)
- Lunx下 怎样启动和关闭oracle数据库
- SQL2008 2机镜像
- mysql 之 主从同步(单向同步和双向同步)
- C++生成斐波拉其数列
- Inversion of Control Containers and the Dependency Injection pattern