使用 reshape2 重塑数据框
我们已经学习了如何筛选、排序、合并和汇总数据框。这些操作只适用于行和列,然
而有时候我们需要做一些更复杂的事情。
例如,下面这段代码读取了一个数据集,包含了两种产品不同日期的质量和耐久性的
测试结果:
toy_tests <- read_ _csv("data/product-toy-tests.csv")
toy_tests
## id date sample quality durability
## 1 T01 20160201 100 9 9
## 2 T01 20160302 150 10 9
## 3 T01 20160405 180 9 10
## 4 T01 20160502 140 9 9
## 5 T02 20160201 70 7 9
## 6 T02 20160303 75 8 8
## 7 T02 20160403 90 9 8
## 8 T02 20160502 85 10 9
上述数据框的每一行都表示一个特定产品(id)在一个特定日期(date)的测试记录。
如果需要同时比较两种产品的质量和耐久性,这种数据格式可能比较麻烦。相反,如果将
数据转换为下面这样,就可以很方便地比较两种产品的值:
date T01 T02
20160201 9 9
20160301 10 9
reshape2 扩展包就是用来完成这种转换的。若还没有安装,请运行以下命令:
install.packages("reshape2")
一旦安装成功,就可以使用 reshape2::dcast( ) 来转换数据,以便于比较相同日
期不同产品的质量(quality)。更确切地说,它重塑了 toy_test 使得 date 列被共享,id 的
值被分割成列,每个 date 和 id 下的值都是 quality 数据:
library(reshape2)
toy_quality <- dcast(toy_tests, date ~ id, value.var = "quality")
toy_quality
## date T01 T02
## 1 20160201 9 7
## 2 20160302 10 NA
## 3 20160303 NA 8
## 4 20160403 NA 9
## 5 20160405 9 NA
## 6 20160502 9 10
如你所见,toy_tests 立即被转换了。两种产品的 quality 值都以 date 对齐。尽
管两种产品每个月都要进行一次测试,它们的日期却不一定会完全匹配。如果一种产品在
某一天有值,另一个产品在同一天没有对应值,结果就会产生缺失值。
一种填补缺失值的方法称为末次观测值结转法(Last Observation Carried Forward,
LOCF),当非缺失值后面紧跟着一个缺失值时,就用该非缺失值填补后面的缺失值,直到
所有的缺失值都被填补完成。zoo 包提供了 LOCF 的一个实现。如果你还没有安装这个包,
请运行以下代码安装:
install.packages("zoo")
为了演示它的工作方式,我们在一个非常简单的带缺失值的数值向量上调用 zoo::
na.locf( ):
zoo::na.locf(c(1, 2, NA, NA, 3, 1, NA, 2, NA))
## [1] 1 2 2 2 3 1 1 2 2
显然,所有的缺失值都被它前面的非缺失值替换了。为了对 toy_quality 的 T01
和 T02 两列进行相同的处理,我们可以将处理后的向量分别赋值到对应列中:
toy_quality$T01 <- zoo::na.locf(toy_quality$T01)
toy_quality$T02 <- zoo::na.locf(toy_quality$T02)
然而,如果 toy_tests 包含了成百上千种产品,我们也相应地写出上千行代码来完
成类似工作的话,就有点荒唐了。一个更好的做法是使用子分配:
toy_quality[-1] <- lapply(toy_quality[-1], zoo::na.locf)
toy_quality
## date T01 T02
## 1 20160201 9 7
## 2 20160302 10 7
## 3 20160303 10 8
## 4 20160403 10 9
## 5 20160405 9 9
## 6 20160502 9 10
我们使用 lapply( ) 对 toy_quality 中除了 date 外的所有列都进行了 LOCF 处
理,并将结果赋值给对应的列。这里,数据框的子分配可以接收列表输入,返回结果也保
留了数据框的类。
但是,虽然数据中没有包含任何缺失值,每一行的含义却发生了变化。原始数据中产
品 T01 在 20160303 这天并没有测试。所以这一天的值应该被解释为在此之前的最后一次
quality 的测试值。另一个缺点是原始数据中,两种产品都是按月测试的,但是重塑后的
数据框并没有以固定频率对齐 date。
这里有一种修正方法,就是使用年-月数据而不是一个确定的日期。在接下来的代码中,
我们会创造一个新列 ym,也就是 toy_tests 的日期值中的前 6 个字符。例如,
substr (20160101, 1, 6) 将会返回 201601:
toy_tests$ym <- substr(toy_tests$date, 1, 6)
toy_tests
## id date sample quality durability ym
## 1 T01 20160201 100 9 9 201602
## 2 T01 20160302 150 10 9 201603
## 3 T01 20160405 180 9 10 201604
## 4 T01 20160502 140 9 9 201605
## 5 T02 20160201 70 7 9 201602
## 6 T02 20160303 75 8 8 201603
## 7 T02 20160403 90 9 8 201604
## 8 T02 20160502 85 10 9 201605
这次,我们按 ym 列对齐,而不是 date:
toy_quality <- dcast(toy_tests, ym ~ id,
value.var = "quality")
toy_quality
## ym T01 T02
## 1 201602 9 7
## 2 201603 10 8
## 3 201604 9 9
## 4 201605 9 10
现在,缺失值消失了,并且两种产品每月的质量得分都被自然地表示出来了。
有时候,我们需要将许多列合并为一列,用于表示被测量的对象,另一列则存储对应
的值。例如,以下代码使用 reshape2::melt( ) 组合原始数据的两种测量(quality 和
durability),并生成一个名为 measure 的列和一个度量值列:
toy_tests2 <- melt(toy_tests, id.vars = c("id", "ym"),
measure.vars = c("quality", "durability"),
variable.name = "measure")
toy_tests2
## id ym measure value
## 1 T01 201602 quality 9
## 2 T01 201603 quality 10
## 3 T01 201604 quality 9
## 4 T01 201605 quality 9
## 5 T02 201602 quality 7
## 6 T02 201603 quality 8
## 7 T02 201604 quality 9
## 8 T02 201605 quality 10
## 9 T01 201602 durability 9
## 10 T01 201603 durability 9
## 11 T01 201604 durability 10
## 12 T01 201605 durability 9
## 13 T02 201602 durability 9
## 14 T02 201603 durability 8
## 15 T02 201604 durability 8
## 16 T02 201605 durability 9
现在,变量名就出现在数据中了,可以被扩展包直接使用。例如,针对这种格式的数据,
我们使用 ggplot2 扩展包来画图。以下代码先对不同的因子组合进行分面,然后绘制散点图:
library(ggplot2)
ggplot(toy_tests2, aes(x = ym, y = value)) +
geom_ _point() +
facet_ _grid(id ~ measure)
这样,我们便得到了一个按照产品 id 和 measure 分组,并以 ym 为 x 轴,以 value
为 y 轴的散点图,如图 12-1 所示。
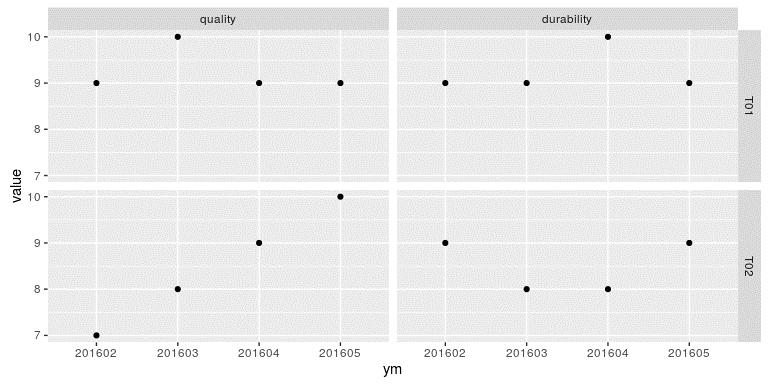
图 12-1
因为分组因子包含在数据中,而不是列名,因此可以很方便地通过透视图将其表示出来。
这次,我们用两种不同颜色的点表示两种产品,如图 12-2 所示。
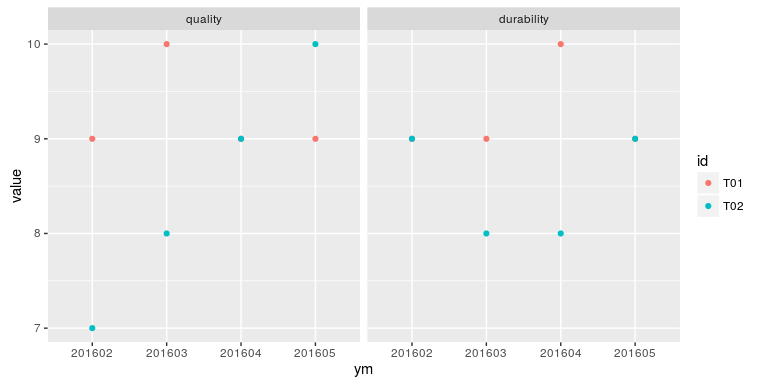
图 12-2
ggplot(toy_tests2, aes(x = ym, y = value, color = id)) +
geom_ _point() +
facet_ _grid(. ~ measure)
最新文章
- Maven + Eclipse + Tomcat - 开启项目调试之旅(转)
- js-定时任务setInterval,setTimeout,clearInterval,clearTimeout
- C++ 把输出结果写入文件/从文件中读取数据
- Tornado源码探寻(开篇)
- JavaScript 中的闭包和作用域链(读书笔记)
- LeetCode: Best Time to Buy and Sell Stock III [123]
- DMA为什么比轮询、中断方式性能要卓越非常多?(你不懂)
- java 操作格子问题(线段树)
- shell按行读取文件
- centos 6.8 下安装redmine(缺陷跟踪系统)
- mingw-gcc-8.3.0-i686-posix-sjlj
- kubernetes系列05—kubectl应用快速入门
- 你知道Java的四种引用类型吗
- Confluence 6 启用和禁用 Office 连接器
- python(5):scipy之numpy介绍
- Spring Boot(八):RabbitMQ详解
- Jenkins job 之间实现带参数触发
- django序列化单表的4种方法的介绍
- Microsoft Tech Summit 2017
- io分析神器blktrace