DKhadoop大数据系统架构设计方案
大数据作为当下最为热门的事件之一,其实已经不算是很新鲜的事情了。如果是三五年前在讨论大数据,那可能会给人一种很新鲜的感觉。大数据作为当下最为重要的一项战略资源,已经是越来越得到国家和企业的高度重视,我们从大数据被上升到国家战略层面就可窥见一二!
现在关于大数据的知识分享可以说已经是铺天盖地了,作为新手入门想查询的信息基本都可以通过网络查询到一些。我对的大数据的了解其实也不是特别丰富,毕竟学习的时间也不是特别长。仅以我熟悉的DKhadoop为例给大家分享一些小知识,往对初学者有点小帮助就可以了。
大数据平台基础框架是很多初学者必然要掌握的内容,大数据太过抽象,有时候写分享的时候难免感觉写的很多困难。还是通过具体的案例来写会比较好理解。关于大数据平台基础框架我还是用自己熟悉的DKhadoop为例。
在此之前还是对DKhadoop做一个简单的说明:DKhadoop大快大数据平台,由大快搜索开发的为了打通大数据生态系统与传统非大数据公司之间的通道而设计的一站式搜索引擎级大数据通用计算平台(写的这么专业,肯定是我从大快宣传册上搬运过来的啦)。对于有大量数据需要处理的传统型企业而言,通过DKhadoop这样的大数据处理平台可以很轻松的跨越大数据技术鸿沟,实现搜索引擎级的大数据平台性能。既然有如此大的优势,那么样的大数据平台的基础框架又是如何的呢?
我们先来看一张图片:这张图是DKH标准平台技术架构图
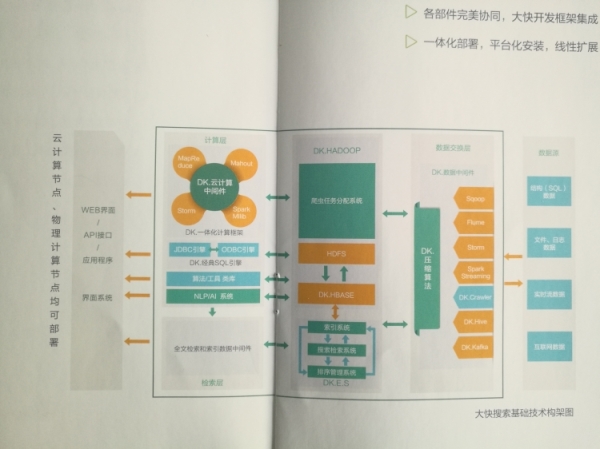
DKhadoop大数据平台基础框架设计方案概述:
1、如果你对原生hadoop较为熟悉的,你就会发现dkhadoop是集成了整个hadoop生态系统的全部组建,当然不仅仅是集成这么简单,而是做了深度的优化,重新编写成的一个完整的更高性能的大数据通过计算平台。这一点跟其他国产发行本大数据平台还是有着非常的区别的,DKH是做的原生态开发,其他的国产发行版仅仅是简单的二次开发。
2、DKhadoop通过中间件技术,将复杂的大数据集群配置简化至三种节点(主节点、管理节点、计算节点),很大程度上简化了集群的管理运维,增强了集群的高可用性、高可维护性、高稳定性。(数据中间件是大快DKH数据交换层的核心)
3、DKH在原生态的基础上开发,并且保持了开源系统的全部优点,与开源系统100%兼容。这样,那些基于开源平台开发的大数据应用就不要经过任何改动,就可以在DKH上高效运行了。
最新文章
- springmvc @responseBody自动打包json出现错误(外键查询死循环)问题
- Slip.js – 在触摸屏上实现列表的滑动排序功能
- MVC 上传文件并展示
- Oracle列操作引起的全表扫描
- Telerik XML 数据源绑定的问题
- Oracle-Oracle10 数据空间建立,导入,导出--oracle10g 删除步骤
- Nginx 配置指令的执行顺序(十)
- 交易应用-运行多个SQL声明
- 【百度地图API】如何制作公交线路的搜索?如331路
- APUE学习笔记(1):APUE运行环境
- Centos7.0 安装 oracle 11g 以及相关问题解决
- 【LSGDOJ 1852】青蛙的烦恼 DP
- 如何将Ubuntu部署到U盘中,用U盘安装linux操作系统
- 正则表达式,提取html标签的属性值
- 【洛谷P2756】飞行员配对方案问题
- python基础--numpy.dot
- 我眼中的K-近邻算法
- 不创建实体对象,利用newstonjson得到json格式字符串,键对应的值
- 接口签名进行key排序,并MD5加密
- C++学习(三十三)(C语言部分)之 队列