scrapy爬虫框架学习笔记(一)
2024-08-27 04:25:10
scrapy爬虫框架学习笔记(一)
1.安装scrapy
pip install scrapy
2.新建工程:
(1)打开命令行模式
(2)进入要新建工程的目录
(3)运行命令:
scrapy startproject projectname
这个命令会在运行命令的目录下新建一个工程目录
这个目录有一个初始的目录结构:
一个以工程 名命名的文件夹和一个名为scrapy.cfg的文件
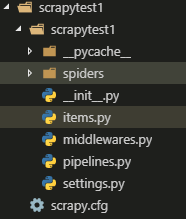
工程名命名的文件夹下有两个文件夹,和五个py文件:
最新文章
- ms-dos中 MSCDEX命名语法详解
- Learn ZYNQ(10) – zybo cluster word count
- node与socket.io搭配小例子-转载
- Lua学习----Lua基础数据类型
- OutputCache概念学习
- Timestamp 使用
- Java Date与SimpleDateFormat
- 安卓手机修改hosts攻略-摘自网络
- iOS之自定义UITabBar替换系统默认的(添加“+”号按钮)
- 【原】Shell脚本-判断文件有无进而复制
- 使用 logback + slf4j 进行日志记录
- Git Bash下实现复制粘贴等快速编辑功能
- STM32实战应用(一)——1602蓝牙时钟1液晶的显示测试
- MyBatis_多查询条件问题
- shiro的DelegatingFilterProxy怎么找到ShiroFilterFactoryBean
- angular-nvd3初体验
- Codeforces 1095F Make It Connected(最小生成树)
- Centos7下GlusterFS分布式存储集群环境部署记录
- OO第三阶段纪实
- nodeJS有多快