pytorch中如何使用DataLoader对数据集进行批处理
最近搞了搞minist手写数据集的神经网络搭建,一个数据集里面很多个数据,不能一次喂入,所以需要分成一小块一小块喂入搭建好的网络。
pytorch中有很方便的dataloader函数来方便我们进行批处理,做了简单的例子,过程很简单,就像把大象装进冰箱里一共需要几步?
第一步:打开冰箱门。
我们要创建torch能够识别的数据集类型(pytorch中也有很多现成的数据集类型,以后再说)。
首先我们建立两个向量X和Y,一个作为输入的数据,一个作为正确的结果:

随后我们需要把X和Y组成一个完整的数据集,并转化为pytorch能识别的数据集类型:

我们来看一下这些数据的数据类型:

可以看出我们把X和Y通过Data.TensorDataset() 这个函数拼装成了一个数据集,数据集的类型是【TensorDataset】。
好了,第一步结束了,冰箱门打开了。
第二步:把大象装进去。
就是把上一步做成的数据集放入Data.DataLoader中,可以生成一个迭代器,从而我们可以方便的进行批处理。

DataLoader中也有很多其他参数:
dataset:Dataset类型,从其中加载数据
batch_size:int,可选。每个batch加载多少样本
shuffle:bool,可选。为True时表示每个epoch都对数据进行洗牌
sampler:Sampler,可选。从数据集中采样样本的方法。
num_workers:int,可选。加载数据时使用多少子进程。默认值为0,表示在主进程中加载数据。
collate_fn:callable,可选。
pin_memory:bool,可选
drop_last:bool,可选。True表示如果最后剩下不完全的batch,丢弃。False表示不丢弃。
好了,第二步结束了,大象装进去了。
第三步:把冰箱门关上。
好啦,现在我们就可以愉快的用我们上面定义好的迭代器进行训练啦。
在这里我们利用print来模拟我们的训练过程,即我们在这里对搭建好的网络进行喂入。

输出的结果是:
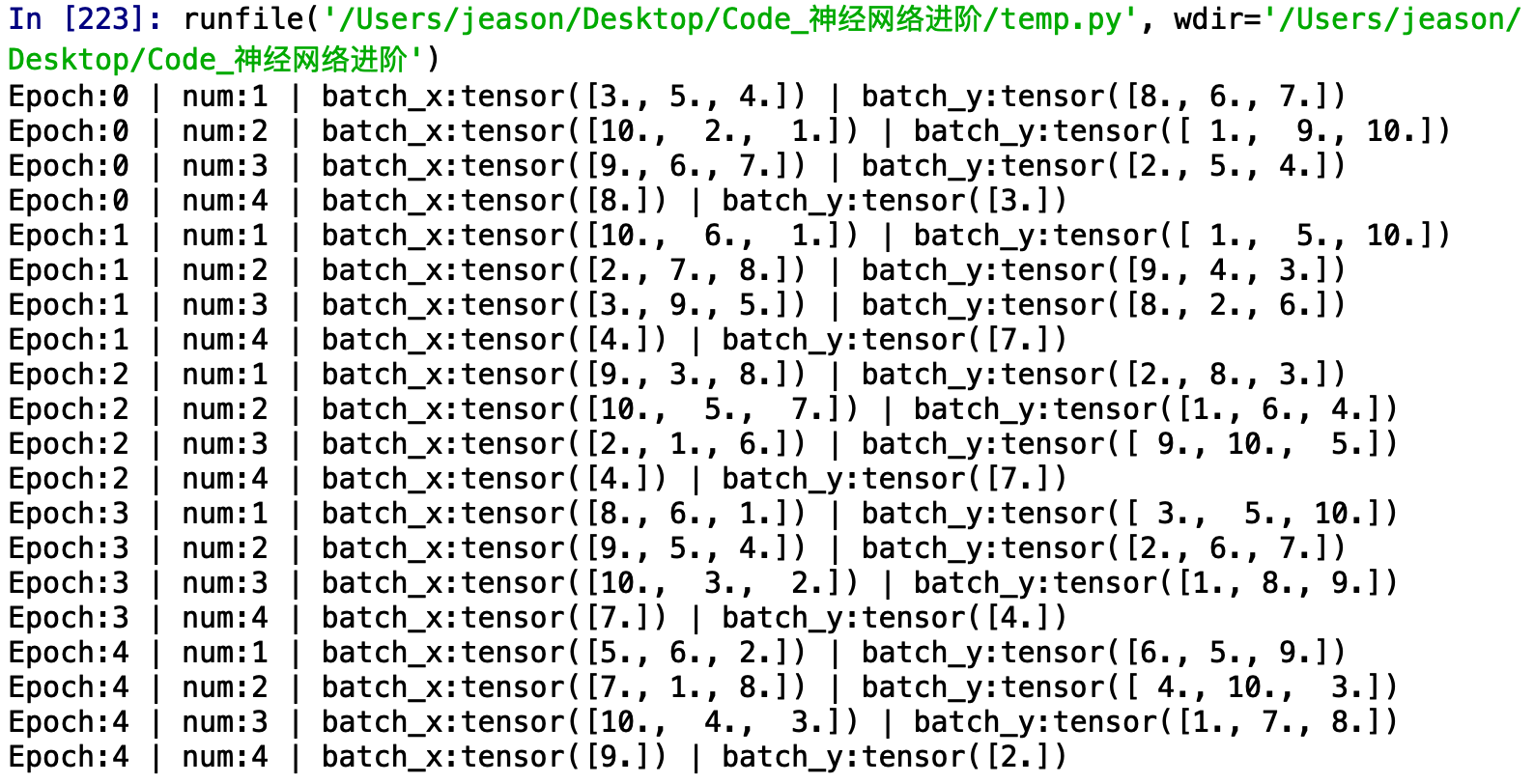
可以看到,我们一共训练了所有的数据训练了5次。数据中一共10组,我们设置的mini-batch是3,即每一次我们训练网络的时候喂入3组数据,到了最后一次我们只有1组数据了,比mini-batch小,我们就仅输出这一个。
此外,还可以利用python中的enumerate(),是对所有可以迭代的数据类型(含有很多东西的list等等)进行取操作的函数,用法如下:
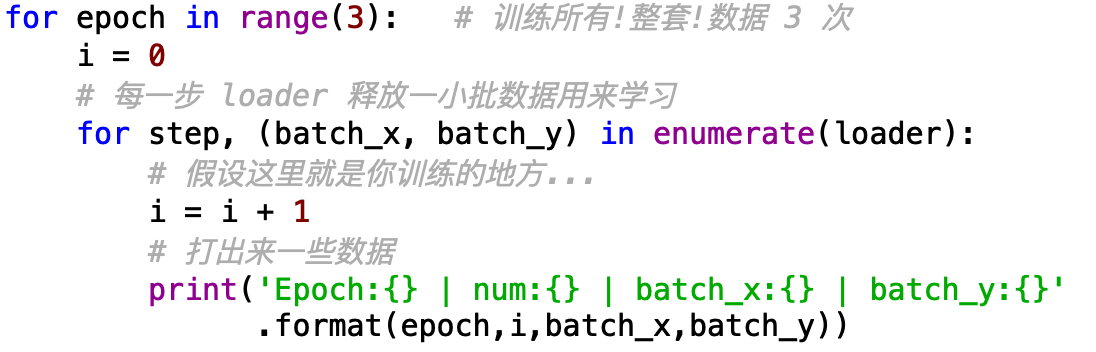
好啦,现在冰箱门就关上啦,(*^__^*)
最新文章
- 解决svn uuid变更问题
- java web学习总结(二十) -------------------监听器属性详解
- AWS国际版的Route 53和CloudFront
- RDIFramework.NET(.NET快速开发框架) 答客户问(2014-02-23)
- CardView的简单介绍
- 10.14_魅族手机音乐播放无故暂停,MetroUICss-tile中的字如何居中
- [LeetCode328]Odd Even Linked List
- python字符串中的中文处理
- Activity中finish()和onDestroy()的区别
- ⒃bootstrap组件 轮播图 基础案例
- springboot+jpa+thymeleaf增删改查的示例(转)
- 我在 B 站学习深度学习(生动形象,跃然纸上)
- 利用ZYNQ SOC快速打开算法验证通路(4)——AXI DMA使用解析及环路测试
- Numpy 系列(八)- 广播机制
- 训练赛-Move Between Numbers
- SOPC与 hello world
- myeclipise生成javadoc
- python 解码json数据并在一个OrderdDict中保留其顺序
- php unset变量
- ats编译中增加透明度 选项