solr 中文分词器IKAnalyzer和拼音分词器pinyin
solr分词过程:
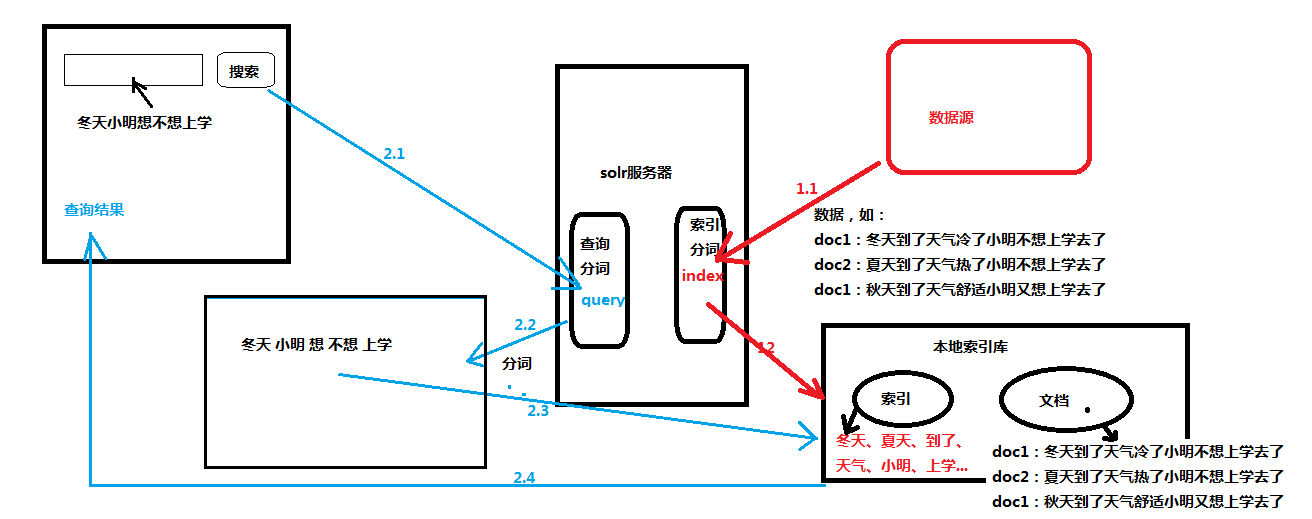
Solr Admin中,选择Analysis,在FieldType中,选择text_en
左边框输入 “冬天到了天气冷了小明不想上学去了”,点击右边的按钮,发现对每个字都进行分词。这不符合中国人的习惯。
solr6.3.0自带中文分词包,在 \solr-6.3.0\contrib\analysis-extras\lucene-libs\lucene-analyzers-smartcn-6.3.0.jar,但是不能自定义词库
好在我们有IKAnalyzer(已无人更新,目前版本是2012)和pinyin分词插件。
IKAnalyzer安装
IKAnalyzer下载地址:https://github.com/EugenePig/ik-analyzer-solr5
因为原始的IKAnalyzer已经不支持solr5以后的版本,这里是修改过后的
用git clone到本地或者直接下载zip到本地,然后执行mvn clean instal(Java8),或者mvn clean -Djavac.src.version=1.7 -Djavac.target.version=1.7 install(jdk1.7)
执行完,在项目 /target 目录下,看到jar文件
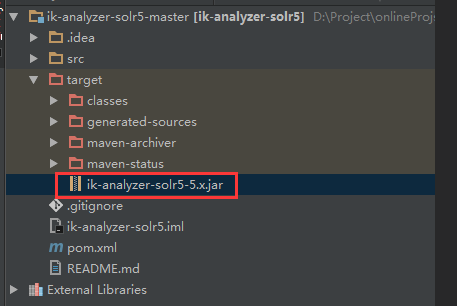
将改jar文件copy到 solr目录:\solr-6.3.0\server\solr-webapp\webapp\WEB-INF\lib
然后修改core的配置文件:\solr-6.3.0\server\solr\test\conf\managed-schema
添加如下配置:
<fieldType name="text_ik" class="solr.TextField">
<analyzer type="index">
<tokenizer class="org.wltea.analyzer.lucene.IKTokenizerFactory" useSmart="false" />
</analyzer>
<analyzer type="query">
<tokenizer class="org.wltea.analyzer.lucene.IKTokenizerFactory" useSmart="true" />
</analyzer>
</fieldType>
或者
<fieldType name="text_ik" class="solr.TextField">
<analyzer type="index" useSmart="false" class="org.wltea.analyzer.lucene.IKAnalyzer"/>
<analyzer type="query" useSmart="true" class="org.wltea.analyzer.lucene.IKAnalyzer"/>
</fieldType>
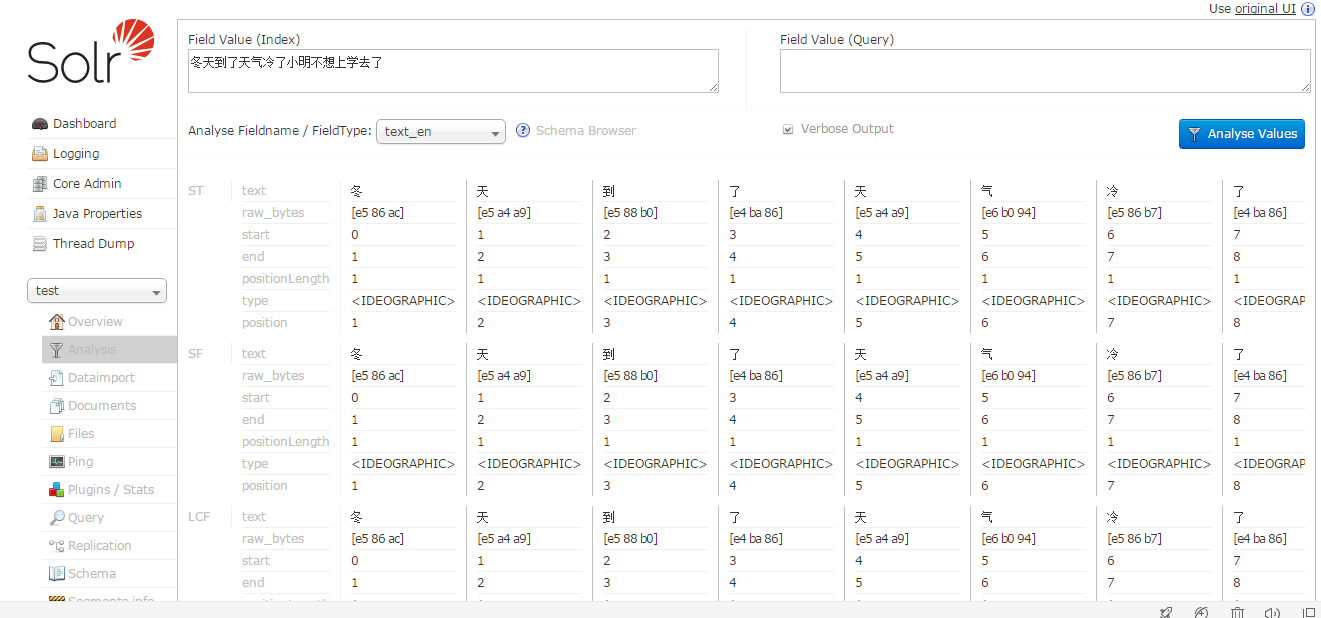
保存重启solr,到选择test核心-Analysis,进入分词页面,输入“冬天到了天气冷了小明不想上学去了”,FieldType选择“text_cn”,点击Analyse Value按钮:
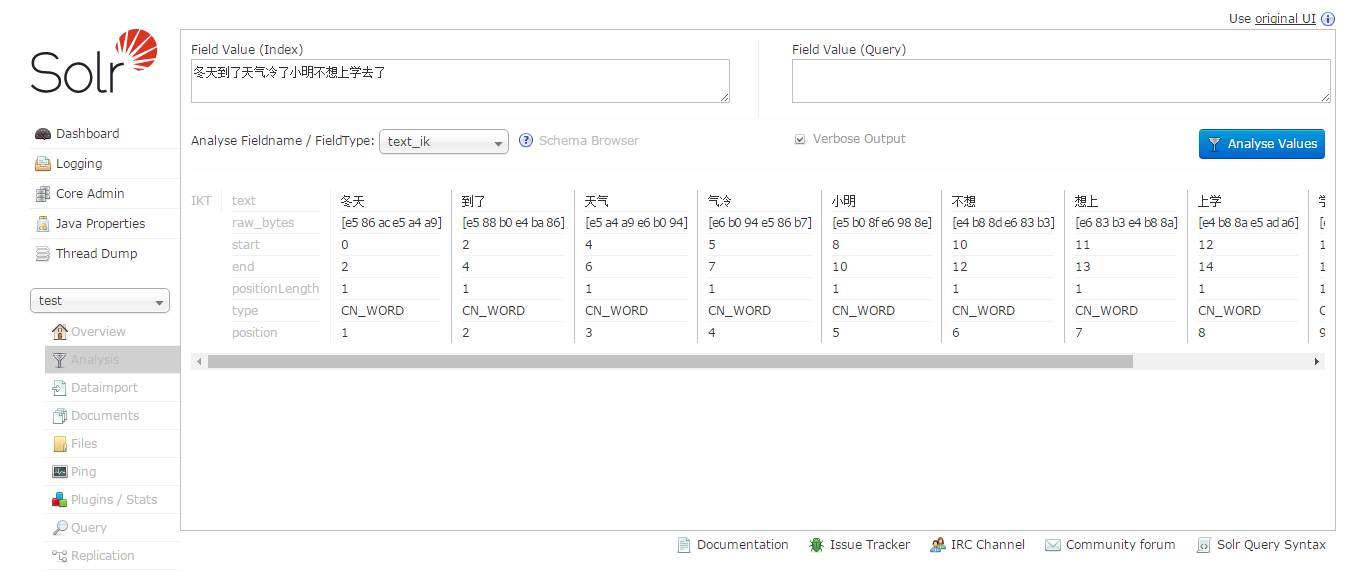
看到已经分词中文成功了。
pinyin安装
pinyin下载地址:http://files.cnblogs.com/files/wander1129/pinyin.zip
下载后将2个jar文件copy到\solr-6.3.0\server\solr-webapp\webapp\WEB-INF\lib目录下,
然后修改core的配置文件:\solr-6.3.0\server\solr\test\conf\managed-schema,添加:
<!-- 配置拼音分词 pinyin-->
<fieldType name="text_pinyin" class="solr.TextField" positionIncrementGap="0">
<analyzer type="index">
<tokenizer class="org.apache.lucene.analysis.ik.IKTokenizerFactory"/>
<filter class="com.shentong.search.analyzers.PinyinTransformTokenFilterFactory" minTermLenght="2" />
<filter class="com.shentong.search.analyzers.PinyinNGramTokenFilterFactory" minGram="1" maxGram="20" />
</analyzer>
<analyzer type="query">
<tokenizer class="org.apache.lucene.analysis.ik.IKTokenizerFactory"/>
<filter class="com.shentong.search.analyzers.PinyinTransformTokenFilterFactory" minTermLenght="2" />
<filter class="com.shentong.search.analyzers.PinyinNGramTokenFilterFactory" minGram="1" maxGram="20" />
</analyzer>
</fieldType>
重启solr
到选择test核心-Analysis,进入分词页面,输入“冬天到了天气冷了小明不想上学去了”,FieldType选择“text_pinyin”,点击Analyse Value按钮:
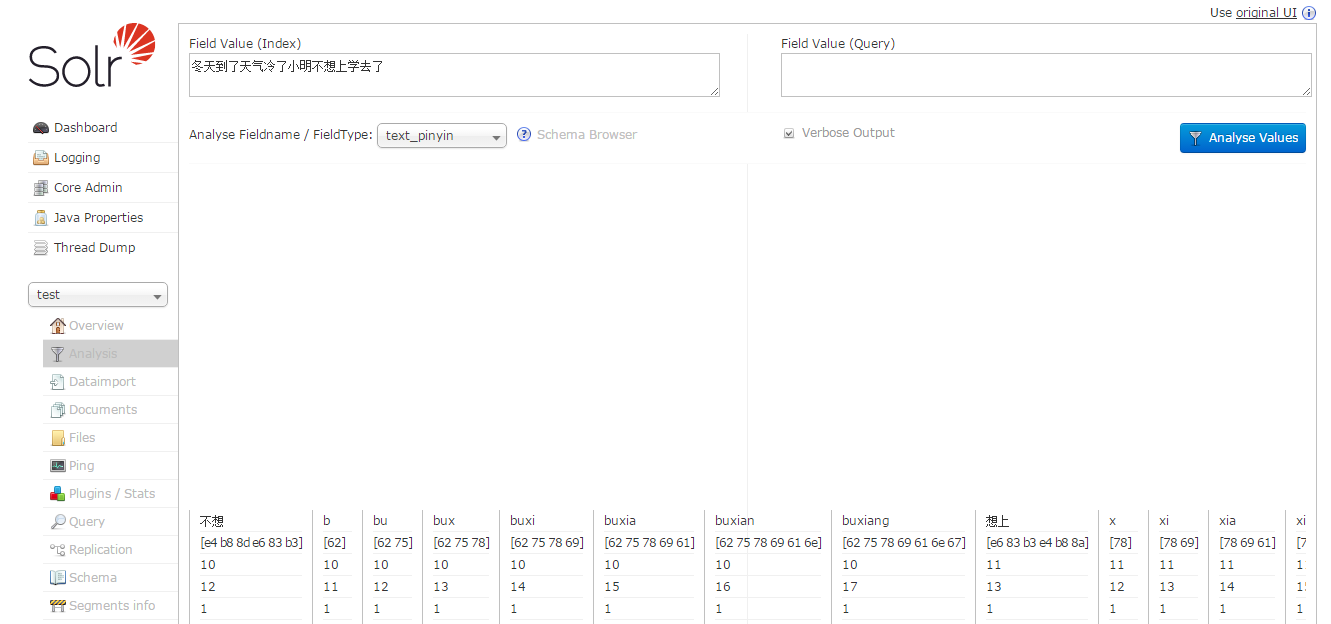
看到汉字转成拼音了。
最新文章
- iOS10之Expected App Behaviors
- js的touch事件的实际引用
- 2-2. Initializing Objects with Initializer Lists
- android中的广播接收实现总结
- 泛型约束 where T : class,new()
- 理解Java中的final和static关键字
- 深入浅出 ES6:ES6 与 Babel / Broccoli 的联用
- java.lang.ExceptionInInitializerError的原因(转)
- PADS封装
- CSS3秘笈:第一章
- OpenCV ——背景建模之CodeBook(2)
- linux pagecache限制与查看
- hadoop中setup,cleanup,run和context讲解
- Supervisor使用(启动nginx/tomcat/redis)
- Is-a
- 使用UtraISO为U盘制作系统启动盘
- [转]JSON Web Token - 在Web应用间安全地传递信息
- rapidjson使用总结
- spring之mvc原理分析及简单模拟实现
- ARM Linux 内核 panic 之cache 一致性 ——Cortex-A9多核cache和TLB一致性广播
热门文章
- 【mysql】mysql索引及优化学习
- Windows cmd命令
- height、clientHeight、offsetHeight、scrollHeight、height()、 innerHeight()、outerHeight()等的区别
- A1127. ZigZagging on a Tree
- 关于MySQL锁的详解
- linux less对文件内容进行搜索
- Java 实例 - 如何执行指定class文件目录(classpath) Java 实例 J
- Jquery Mobile基本元素
- DK location not found. Define location with sdk.dir in the local.properties file or with an ANDROID_HOME
- mysql优化好文