快速部署网络爬虫框架scrapy
2024-10-21 05:39:35
1. 安装Anaconda,因为Anaconda基本把所有需要依赖的环境都一键帮我们部署好了,不需要再操心其他事了,进官网选择需要下载的版本:https://www.anaconda.com/download/
2. 安装完Anaconda,添加环境变量,见截图
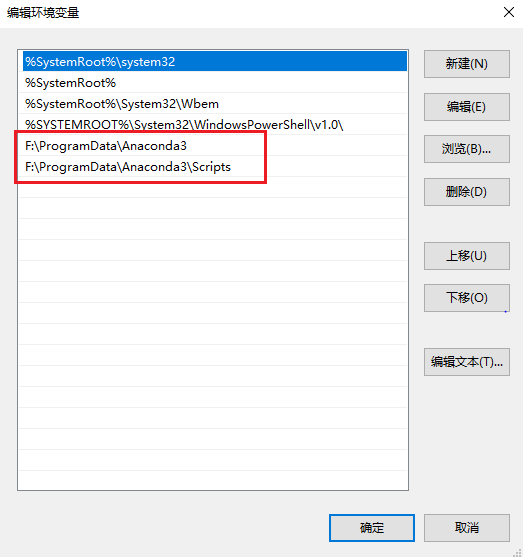
3. 验证Anaconda是否安装OK,打开开始菜单,选择  ,输入命令conda,出现截图的情况就说明装好了,环境变量也是OK的
,输入命令conda,出现截图的情况就说明装好了,环境变量也是OK的

4. 接下来就是安装scrapy,在刚才的Anaconda Prompt,输入命令:conda install scrapy. 系统自动搜索下载最新版本的scrapy
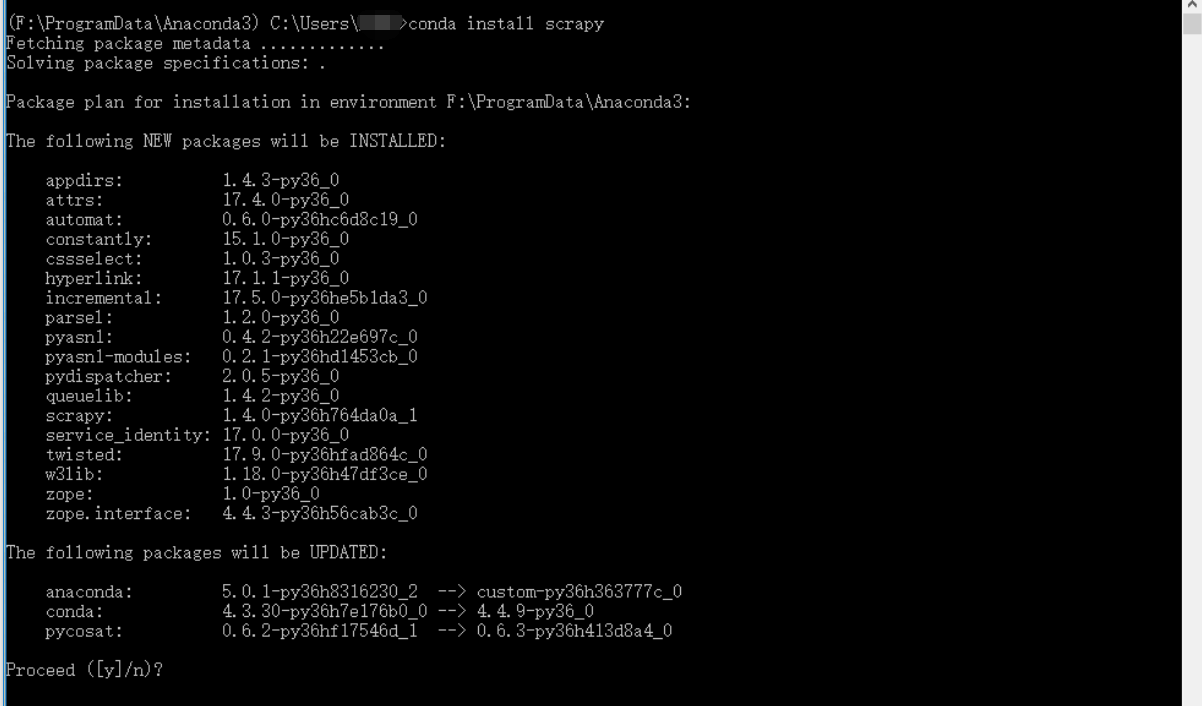
输入y,等待安装完后,输入命令:scrapy version.出现下面截图的情况就说明安装好了,到这里就安装完了scrapy,可以畅快的去编写网络爬虫代码了~~

最新文章
- Perforce 与Source Insight, Visual Studio集成
- 三款不错的图片压缩上传插件(webuploader+localResizeIMG4+LUploader)
- R语言进行数据预处理wranging
- [转]JUnit-4.11使用报java.lang.NoClassDefFoundError: org/hamcrest/SelfDescribing错误
- 再谈collections模块defaultdict()和namedtuple()
- tar 打包文件 除某个文件夹
- hdu 1505(dp求最大子矩阵)
- Coreseek/sphinx全文检索的了解
- JavaWeb 后端 <十二> 之 过滤器 filter 乱码、不缓存、脏话、标记、自动登录、全站压缩过滤器
- BZOJ_1717_[Usaco2006 Dec]Milk Patterns 产奶的模式_后缀数组
- Angularjs 学习笔记-2017-02-06-双向数据绑定
- SQL Server利用XML找字符串相同部分
- Python进行MySQL数据库操作
- 【Linux】rpm常用命令及rpm参数介绍
- Linux下配置多个tomcat多个域名
- python 获取IP
- 《Hands-On Machine Learning with Scikit-Learn&TensorFlow》读书笔记
- 整理iOS9适配中出现的坑
- FreeRTOS 低功耗之待机模式
- 无限级分类 mysql设计